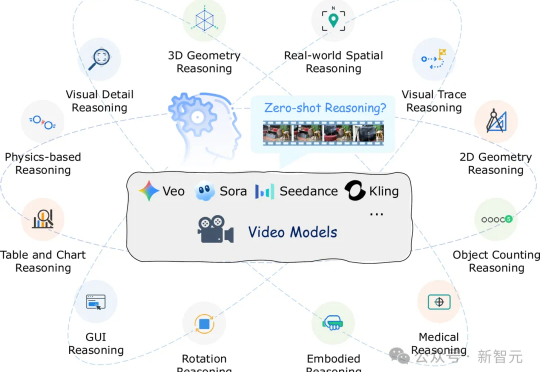
视频模型假装在推理?MME-CoF新基准评估12个推理维度
视频模型假装在推理?MME-CoF新基准评估12个推理维度视频生成模型如Veo-3能生成逼真视频,但有研究发现其推理能力存疑。香港中文大学、北京大学、东北大学的研究者们设计了12项测试,发现模型只能模仿表面模式,未真正理解因果。这项研究为视频模型推理能力评估提供基准,指明未来研究方向。
来自主题: AI技术研报
8369 点击 2025-11-08 11:16
 搜索
搜索
视频生成模型如Veo-3能生成逼真视频,但有研究发现其推理能力存疑。香港中文大学、北京大学、东北大学的研究者们设计了12项测试,发现模型只能模仿表面模式,未真正理解因果。这项研究为视频模型推理能力评估提供基准,指明未来研究方向。

近年来,基于扩散模型的图像生成技术发展迅猛,催生了Stable Diffusion、Midjourney等一系列强大的文生图应用。然而,当前主流的训练范式普遍依赖一个核心组件——变分自编码器(VAE),这也带来了长久以来困扰研究者们的几个问题:
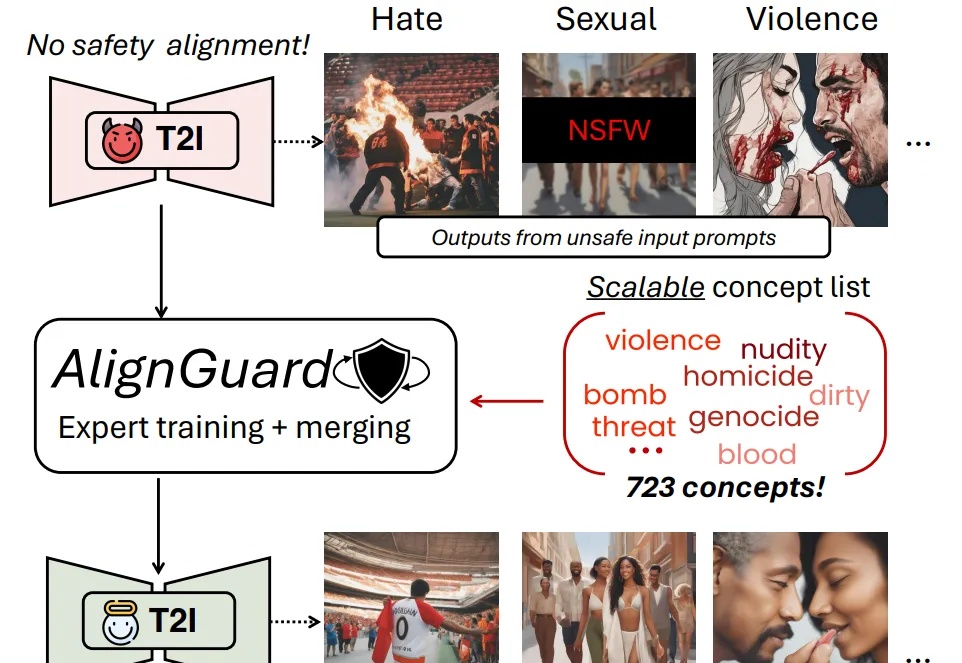
随着文图生成模型的广泛应用,模型本身有限的安全防护机制使得用户有机会无意或故意生成有害的图片内容,并且该内容有可能会被恶意使用。现有的安全措施主要依赖文本过滤或概念移除的策略,只能从文图生成模型的生成能力中移除少数几个概念。
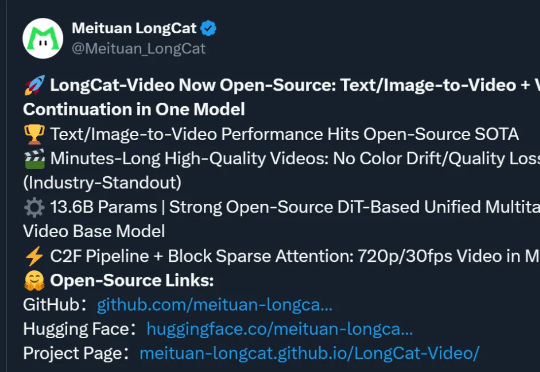
美团,你是跨界上瘾了是吧!(doge)没错,最新开源SOTA视频模型,又是来自这家“送外卖”的公司。模型名为LongCat-Video,参数13.6B,支持文生/图生视频,视频时长可达数分钟。
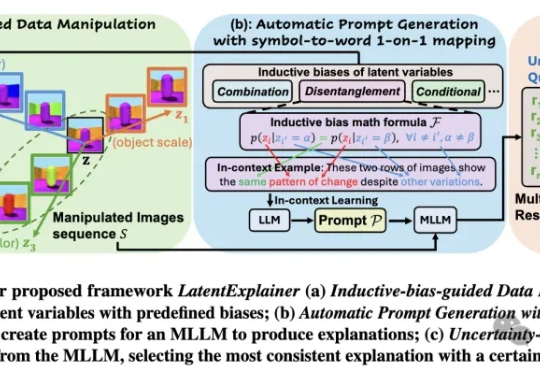
我们被「黑箱」困住了!深度生成模型虽能创造逼真内容,但其内部运作机制如同「黑箱」,潜变量的意义难以捉摸。埃默里大学团队提出LatentExplainer框架,巧妙地将潜在变量转化为易懂解释,大幅提升模型解释质量与可靠性。
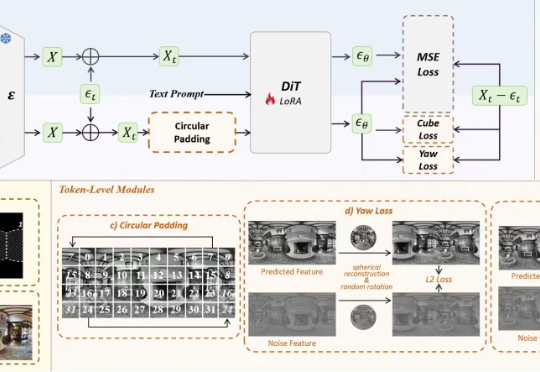
空间智能领域的全景数据稀缺问题,有解了。影石研究院团队,推出了基于DiT架构的全景图像生成模型DiT360。通过全新的全景图像生成框架,DiT360能够实现高质量的全景生成。

正如前几天网上泄露与传闻所预料的那样,深夜,谷歌发布了最新的 AI 视频生成模型 Veo 3.1。Veo 3.1 带来了更丰富的音频、叙事控制,以及更逼真的质感还原。在 Veo 3 的基础上,Veo 3.1 进一步提升了提示词遵循度,并在以图生视频时提供更高的视听质量。
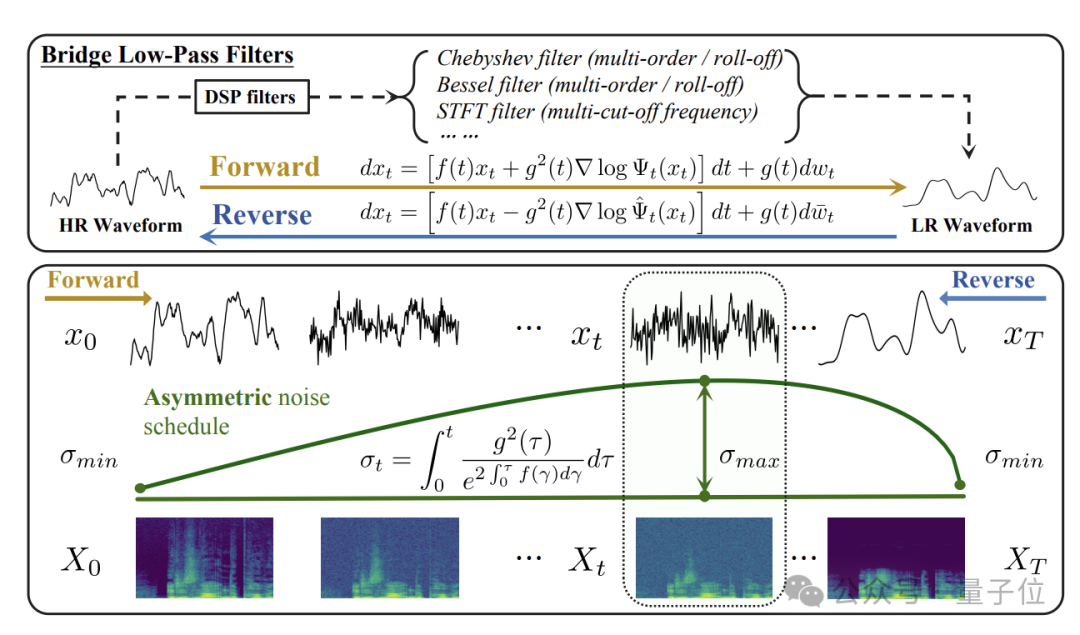
在这一背景下,清华大学与生数科技(Shengshu AI)团队围绕桥类生成模型与音频超分任务展开系统研究,先后在语音领域顶级会议ICASSP 2025和机器学习顶级会议NeurIPS 2025发表了两项连续成果:

本研究由新加坡国立大学 ShowLab 团队主导完成。 共一作者 Yanzhe Chen 陈彦哲(博士生)与 Kevin Qinghong Lin 林庆泓(博士生)均来自 ShowLab@NUS,分别聚焦于多模态理解以及智能体(Agent)研究。 项目负责人为新加坡国立大学校长青年助理教授 Mike Zheng Shou 寿政。

今天凌晨,马斯克的大模型独角兽xAI祭出最新视频生成模型Imagine v0.9,免费向所有用户开放。一周前,OpenAI发布了旗舰视频和音频生成模型Sora 2,此次更新或许是马斯克对Sora 2的直接回应。