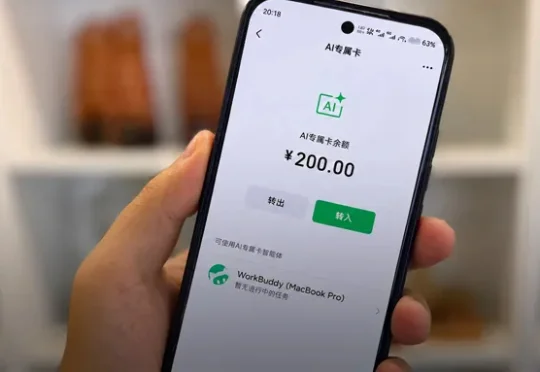
微信发布面向Agent消费的“AI专属卡”,给AI发“钱包”,转它200元全花光了!
微信发布面向Agent消费的“AI专属卡”,给AI发“钱包”,转它200元全花光了!今日,微信支付正式发布面向Agent消费的“AI专属卡”,腾讯AI办公助手WorkBuddy首发接入。简单来说,用户可以通过这张卡,在WorkBuddy中提出消费需求,从团购推荐到下单支付都由Agent完成。
来自主题: AI资讯
9638 点击 2026-06-18 00:02
 搜索
搜索
今日,微信支付正式发布面向Agent消费的“AI专属卡”,腾讯AI办公助手WorkBuddy首发接入。简单来说,用户可以通过这张卡,在WorkBuddy中提出消费需求,从团购推荐到下单支付都由Agent完成。
《读佳》获知,腾讯“TDream”带着“创造可玩的世界”的定位低调开启内测。“说句肺腑之言,这个产品,我觉得打破了我对腾讯的认知。”一位用户看了TDream生成《山月》视频作品后,十分感慨。他觉得,这个产品可以和字节的Seedance2.0、HappyHorse掰掰手腕。

对AI效率赛道,葬AI的朋友郭先生有一句名言:「效率赛道一定要做情绪价值,因为你会发现解决实际问题大家都不行。」

如果你最近关注 AI 圈,应该已经注意到一个变化:AI 产品正在从单点工具,走向统一入口。

刚刚,微信又对AI出手了!微信正式发布《关于开发者接入微信AI生态的指引》。今天起,获得内测的开发者可以授权微信,让它的AI读你的小程序、操作你的小程序、帮助用户唤起你的小程序服务。
有读者告诉《读佳》,腾讯做了一个龙虾社区“虾友会”,还没正式推广。说实话,“虾友会”这个社区挺有意思的,它就像是腾讯AI产品用户的“聚贤庄”,一些大佬还在里面做LV1的“小芯肝”,这个产品意味着什么呢?我们认为:

6月5日,腾讯云AI产业应用大会上,腾讯集团高级执行副总裁汤道生和首席AI科学家姚顺雨同台对谈。这是姚顺雨加入腾讯后第一次在公司活动中公开亮相。这场对谈的主题叫《腾讯AI的下半场》。2025年4月,姚顺雨曾在个人博客发表《The Second Half》一文,在技术社区广泛传播。文章的核心判断是:AI正站在中场分界线上,上半场的核心在于训练方法和模型的突破

你猜一个能翻译33种语言、性能逼近顶尖闭源模型的AI,装进手机里需要多大?
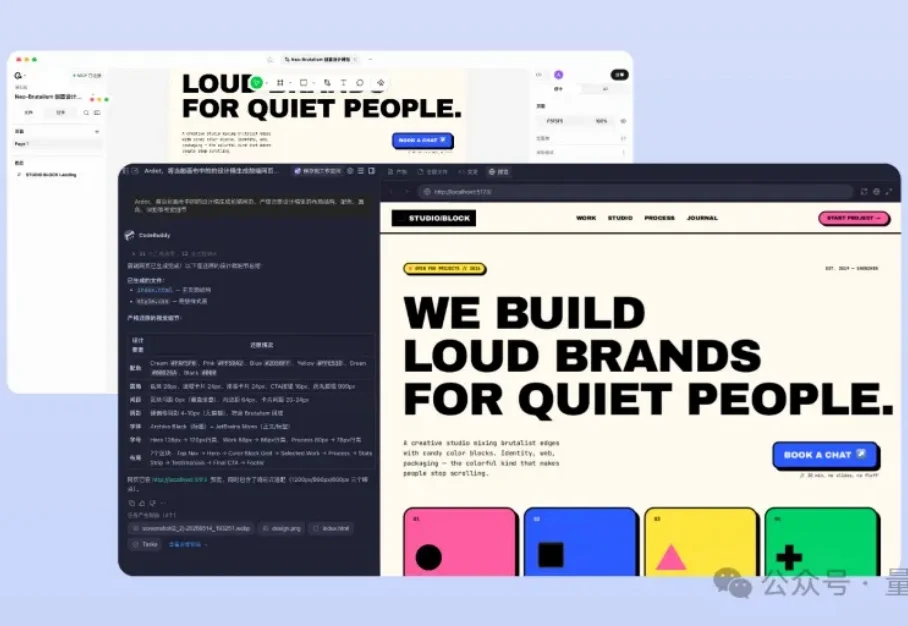
Claude Design前脚刚把设计圈炸完,腾讯又公测了一个Ardot—— AI设计智能体平台,一句话生成可编辑UI设计稿、Figma文件零成本导入、一键转代码直通IDE、多人在线评审……
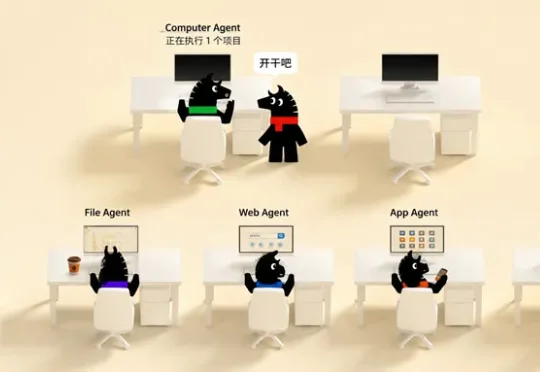
近日,腾讯开始内测一款名为Marvis(马维斯)的操作系统层个人AI助手。这一AI助手通过多个Agent的协作完成App操作、EXE操作、电脑操作、文件管理、文档生成以及各种复杂任务,24小时持续在线,并支持跨端操作。