
微信、清华连续自回归模型CALM,新范式实现从「离散词元」到「连续向量」转变
微信、清华连续自回归模型CALM,新范式实现从「离散词元」到「连续向量」转变众所周知,大型语言模型(LLM)的根本运作方式是预测下一个 token(词元),能够保证生成的连贯性和逻辑性,但这既是 LLM 强大能力的「灵魂」所在,也是其枷锁,将导致高昂的计算成本和响应延迟。 可
来自主题: AI技术研报
8361 点击 2025-11-09 10:21
 搜索
搜索
众所周知,大型语言模型(LLM)的根本运作方式是预测下一个 token(词元),能够保证生成的连贯性和逻辑性,但这既是 LLM 强大能力的「灵魂」所在,也是其枷锁,将导致高昂的计算成本和响应延迟。 可

马斯克麾下的新AI虚拟女友Ani看似风光地上线,背后却被曝出员工被迫提供面容和声音等生物数据用于训练。这一做法在xAI公司内部引发争议,多名员工担心自己的相貌和声音可能被滥用于深度伪造,或在未授权情况下被他人使用。此事也让业界反思,在AI竞赛中冲锋陷阵的公司,是否正在以侵犯隐私和道德边界为代价换取技术进步。
研究团队提出一种简洁且高效的算法 ——SimKO (Simple Pass@K Optimization),显著优化了 pass@K(K=1 及 K>1)性能。同时,团队认为当前的用熵(Entropy)作为指标衡量多样性存在局限:熵无法具体反映概率分布的形态。如图 2(c)所示,两个具有相同熵值的分布,一个可能包含多个峰值,而另一个则可能高度集中于一个峰值。
OmniVinci是英伟达推出的全模态大模型,能精准解析视频和音频,尤其擅长视觉和听觉信号的时序对齐。它以90亿参数规模,性能超越同级别甚至更高级别模型,训练数据效率是对手的6倍,大幅降低成本。在视频内容理解、语音转录、机器人导航等场景中,OmniVinci能提供高效支持,展现出卓越的多模态应用能力。
视频生成模型如Veo-3能生成逼真视频,但有研究发现其推理能力存疑。香港中文大学、北京大学、东北大学的研究者们设计了12项测试,发现模型只能模仿表面模式,未真正理解因果。这项研究为视频模型推理能力评估提供基准,指明未来研究方向。

智源研究院(BAAI)、Spin Matrix、乐聚机器人与新加坡南洋理工大学等联合提出了一个全新的终身记忆系统——RoboBrain-Memory。RoboBrain-Memory是全球范围内首个专为全双工、全模态模型设计的终身记忆系统,旨在解决具身智能体在真实世界的复杂交互问题,不仅支持实时音视频中多用户身份识别与关系理解,还能动态维护个体档案与社会关系图谱,从而实现类人的长期个性化交互。
本文来自于香港中文大学 MMLab 和 vivo AI Lab,其中论文第一作者肖涵,主要研究方向为多模态大模型和智能体学习,合作作者王国志,研究方向为多模态大模型和 Agent 强化学习。项目 le
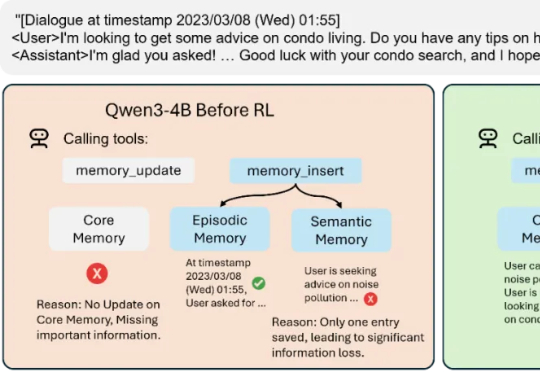
Mem-α 的出现,正是为了解决这一困境。由加州大学圣地亚哥分校的 Yu Wang 在 Anuttacon 实习期间完成,这项工作是首次将强化学习引入大模型的记忆管理体系,让模型能够自主学习如何使用工具去存储、更新和组织记忆。

两人小团队,仅用两周就复刻了之前被硅谷夸疯的DeepSeek-OCR?? 复刻版名叫DeepOCR,还原了原版低token高压缩的核心优势,还在关键任务上追上了原版的表现。完全开源,而且无需依赖大规模的算力集群,在两张H200上就能完成训练。
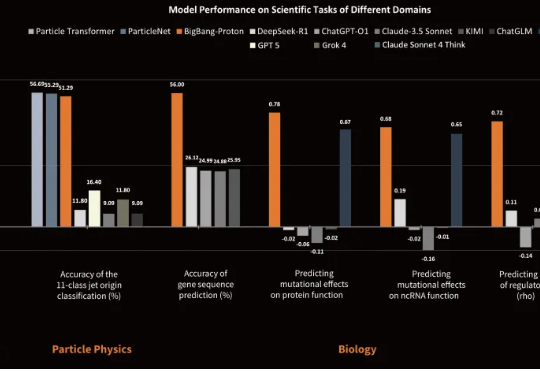
近日,专注于研发物质世界基座模型的公司超越对称(上海)技术有限公司(超对称)发布了新版基座模型 BigBang-Proton,成功实现多个真实世界的专业学科问题与 LLM 的统一预训练和推理,挑战了 Sam Altman 和主流的 AGI 技术路线。