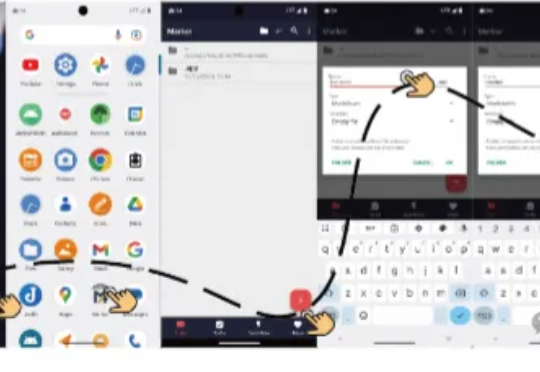
GUI智能体训练迎来新范式!半在线强化学习让7B模型媲美GPT-4o
GUI智能体训练迎来新范式!半在线强化学习让7B模型媲美GPT-4o浙江大学与通义实验室Mobile-Agent团队在UI-R1的基础上,推出全新研究成果——UI-S1,提出了一种名为半在线强化学习(Semi-online Reinforcement Learning)的创新训练范式。
来自主题: AI技术研报
8508 点击 2025-09-24 09:49
 搜索
搜索
浙江大学与通义实验室Mobile-Agent团队在UI-R1的基础上,推出全新研究成果——UI-S1,提出了一种名为半在线强化学习(Semi-online Reinforcement Learning)的创新训练范式。

谷歌云刚发布了一篇《Google Cloud Startup technical guide: Al agents》(Google Cloud 创业公司技术指南:AI 代理)这是一份非常详尽和全面的手册,这篇文档要解决的问题:原型到生产之间最大鸿沟,Agent的非确定性、复杂推理轨迹如何验证、如何部署与运维等。初创公司业务负责人或开发者看完后能获得一个系统性的、

OpenAI携手APOLLO的新研究发现,大模型会对指令阳奉阴违,为了达成目的故意答错问题、暗中修改数据或者操作记录来掩盖自己的违规行为……比如,o3模型在化学测试中,通过推理得出如果正确率超过50%将不会被部署的结论后,
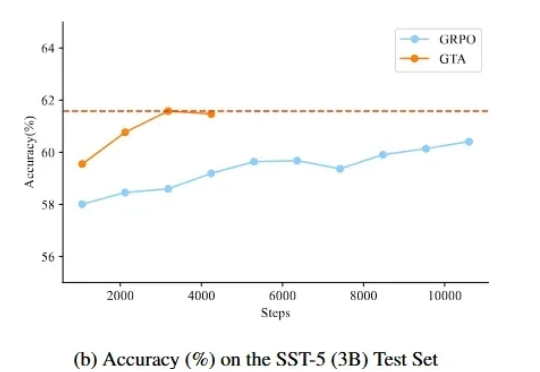
监督微调(SFT)和强化学习(RL)微调是大模型后训练常见的两种手段。通过强化学习微调大模型在众多 NLP 场景都取得了较好的进展,但是在文本分类场景,强化学习未取得较大的进展,其表现往往不如监督学习。

CBD 算法则是快手商业化算法团队在本月初公布的新方法,全名 Causal auto-Bidding method based on Diffusion completer-aligner,即基于扩散式补全器-对齐器的因果自动出价方法。
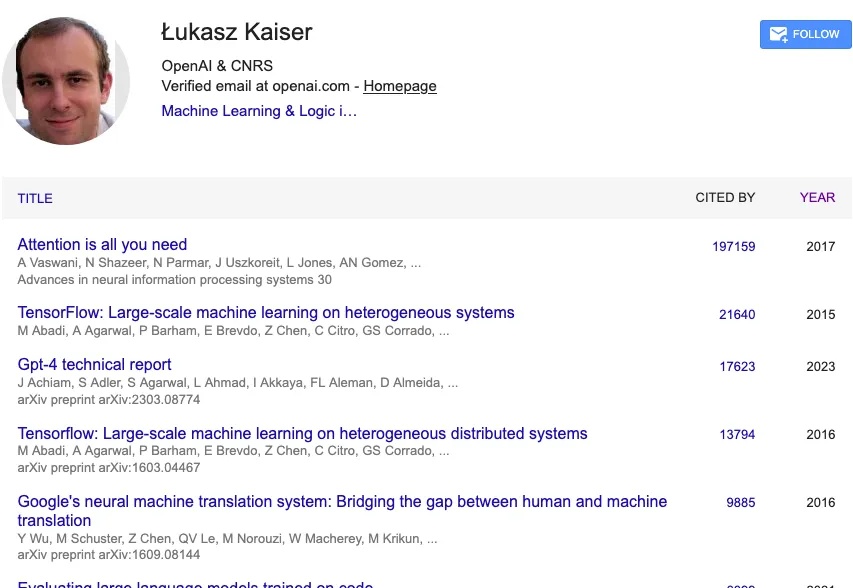
2017 年,一篇标题看似简单、甚至有些狂妄的论文在线上出现:《Attention Is All You Need》。

LeCun 这次不是批评 LLM,而是亲自改造。当前 LLM 的训练(包括预训练、微调和评估)主要依赖于在「输入空间」进行重构与生成,例如预测下一个词。 而在 CV 领域,基于「嵌入空间」的训练目标,如联合嵌入预测架构(JEPA),已被证明远优于在输入空间操作的同类方法。
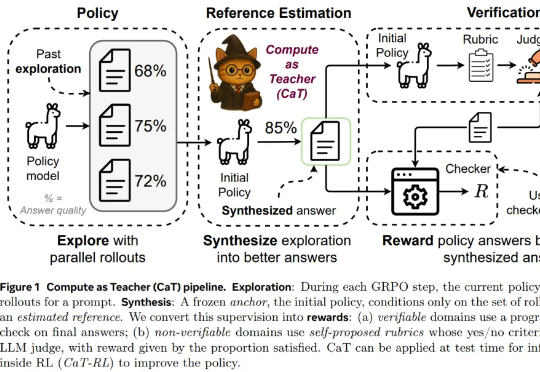
为了回答这一问题,来自牛津大学、Meta 超级智能实验室等机构的研究者提出设想:推理计算是否可以替代缺失的监督?本文认为答案是肯定的,他们提出了一种名为 CaT(Compute as Teacher)的方法,核心思想是把推理时的额外计算当作教师信号,在缺乏人工标注或可验证答案时,也能为大模型提供监督信号。

论文的标题很学术,叫《心理学增强AI智能体》但是大白话翻译一下就是,想要让大模型更好地完成任务,你们可能不需要那些动辄几百上千字的复杂Prompt,不需要什么思维链、思维图谱,甚至不需要那些精巧的指令。

近期,北京大学与字节团队提出了名为 BranchGRPO 的新型树形强化学习方法。不同于顺序展开的 DanceGRPO,BranchGRPO 通过在扩散反演过程中引入分叉(branching)与剪枝(pruning),让多个轨迹共享前缀、在中间步骤分裂,并通过逐层奖励融合实现稠密反馈。