
2025年了,AI还看不懂时钟!90%人都能答对,顶尖AI全军覆没
2025年了,AI还看不懂时钟!90%人都能答对,顶尖AI全军覆没一般人准确率89.1%,AI最好只有13.3%。在新视觉基准ClockBench上,读模拟时钟这道「小学题」,把11个大模型难住了。为什么AI还是读不准表?是测试有问题还是AI真不行?
来自主题: AI资讯
8088 点击 2025-09-09 17:24
 搜索
搜索
一般人准确率89.1%,AI最好只有13.3%。在新视觉基准ClockBench上,读模拟时钟这道「小学题」,把11个大模型难住了。为什么AI还是读不准表?是测试有问题还是AI真不行?
几十G的大模型,怎么可能塞进一台手机?YouTube却做到了:在 Shorts 相机里,AI能实时「重绘」你的脸,让你一秒变身僵尸、卡通人物,甚至瞬间拥有水光肌,效果自然到分不清真假。

Meta超级智能实验室的首篇论文,来了—— 提出了一个名为REFRAG的高效解码框架,重新定义了RAG(检索增强生成),最高可将首字生成延迟(TTFT)加速30倍。

英伟达也做深度研究智能体了。

过去几年,大语言模型(LLM)的训练大多依赖于基于人类或数据偏好的强化学习(Preference-based Reinforcement Fine-tuning, PBRFT):输入提示、输出文本、获得一个偏好分数。这一范式催生了 GPT-4、Llama-3 等成功的早期大模型,但局限也日益明显:缺乏长期规划、环境交互与持续学习能力。
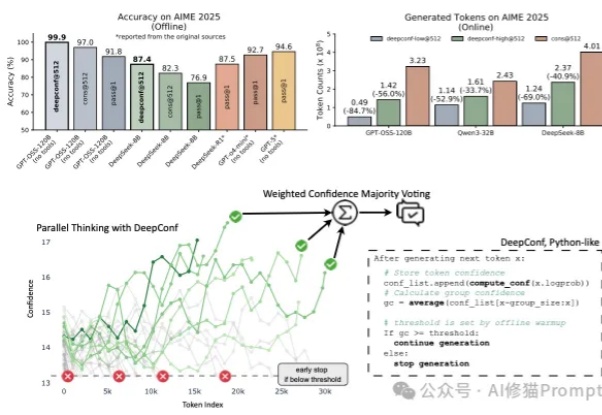
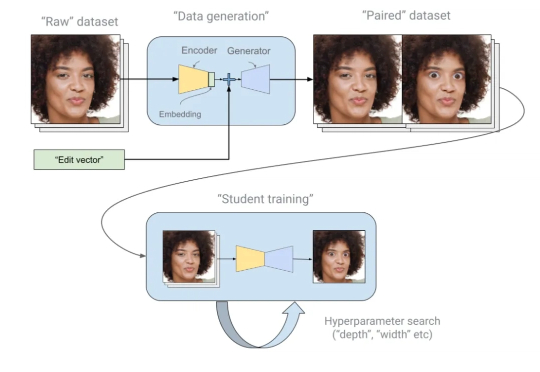
在大型语言模型(LLM)进行数学题、逻辑推理等复杂任务时,一个非常流行且有效的方法叫做 “自洽性”(Self-Consistency),通常也被称为“平行思考”。

经历了前段时间的鸡飞狗跳,扎克伯格的投资似乎终于初见成效。
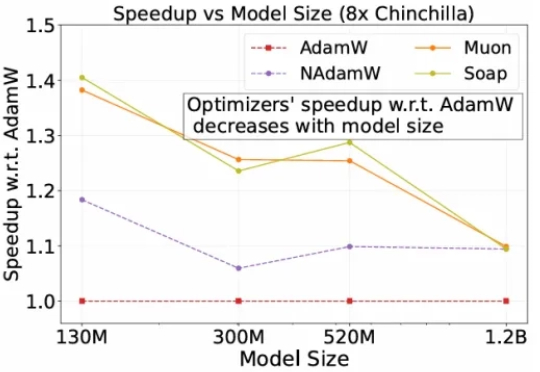
自2014 年提出以来,Adam 及其改进版 AdamW 长期占据开放权重语言模型预训练的主导地位,帮助模型在海量数据下保持稳定并实现较快收敛。
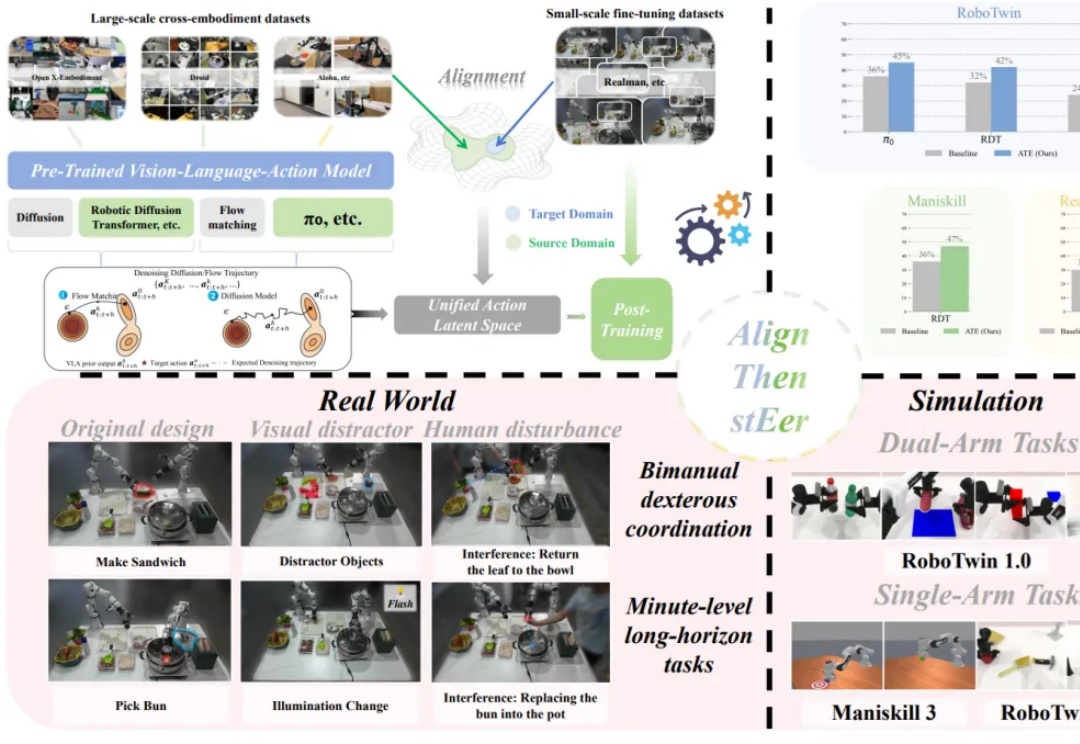
在多模态大模型的基座上,视觉 - 语言 - 动作(Visual-Language-Action, VLA)模型使用大量机器人操作数据进行预训练,有望实现通用的具身操作能力。
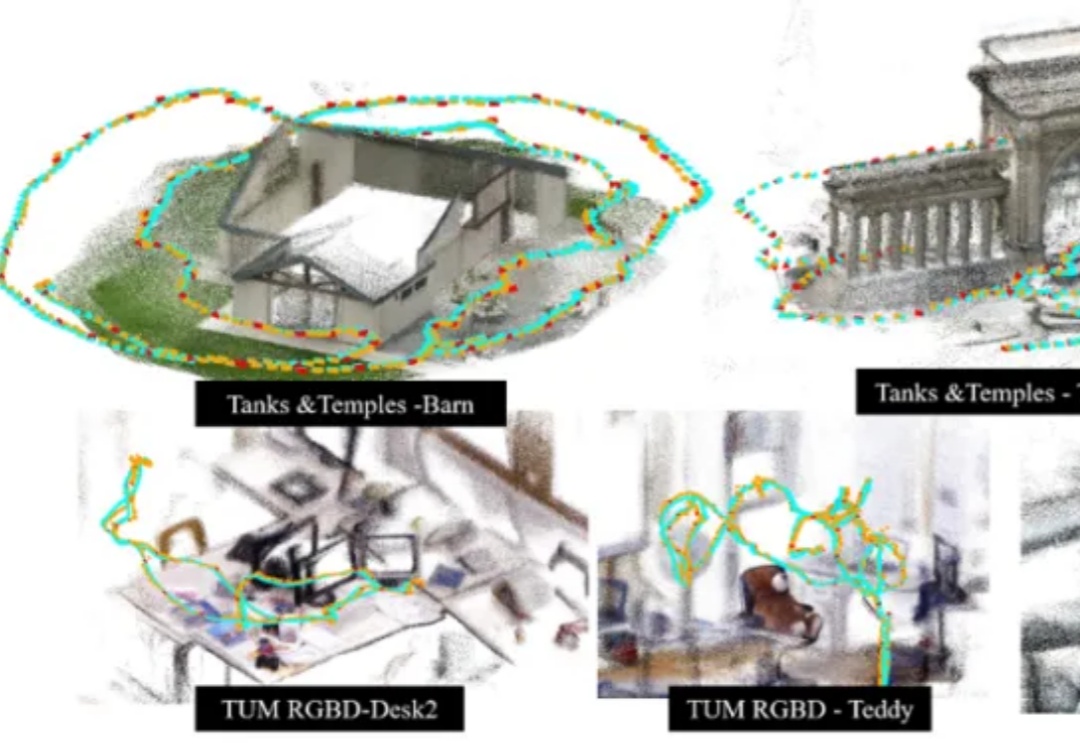
香港科技大学谭平教授团队与地平线(Horizon Robotics)团队最新发布了一项 3D 场景表征与大规模重建新方法 SAIL-Recon,通过锚点图建立构建场景全局隐式表征,突破现有 VGGT 基础模型对于大规模视觉定位与 3D 重建的处理能力瓶颈,实现万帧级的场景表征抽取与定位重建,将空间智能「3D 表征与建模」前沿推向一个新的高度。