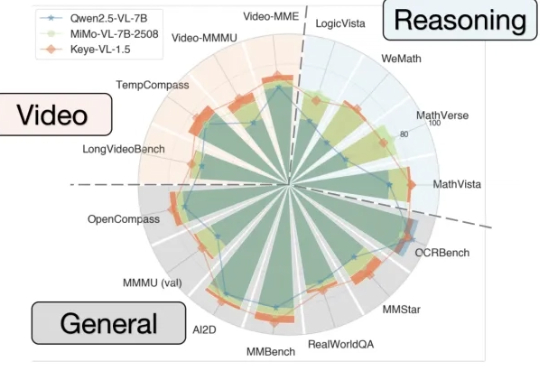
视频理解新标杆,快手多模态推理模型开源:128k上下文+0.1秒级视频定位+跨模态推理
视频理解新标杆,快手多模态推理模型开源:128k上下文+0.1秒级视频定位+跨模态推理能看懂视频并进行跨模态推理的大模型Keye-VL 1.5,快手开源了。
来自主题: AI技术研报
8765 点击 2025-09-06 12:44
 搜索
搜索
能看懂视频并进行跨模态推理的大模型Keye-VL 1.5,快手开源了。
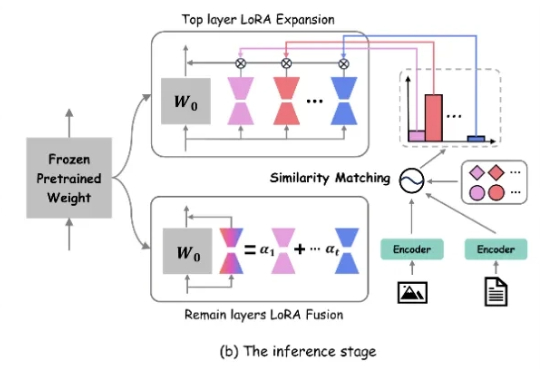
近年来,生成式 AI 和多模态大模型在各领域取得了令人瞩目的进展。然而,在现实世界应用中,动态环境下的数据分布和任务需求不断变化,大模型如何在此背景下实现持续学习成为了重要挑战
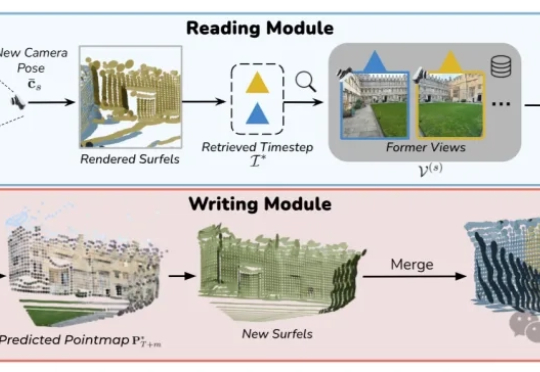
VMem用基于3D几何的记忆索引替代「只看最近几帧」的短窗上下文:检索到的参考视角刚好看过你现在要渲染的表面区域;让模型在小上下文里也能保持长时一致性;实测4.2s/帧,比常规21帧上下文的管线快~12倍。
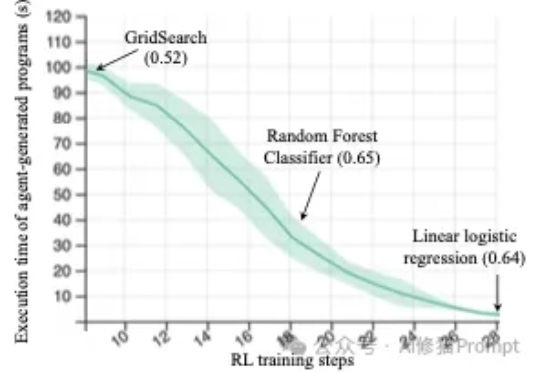
来自斯坦福的研究者们最近发布的一篇论文(https://arxiv.org/abs/2509.01684)直指RL强化学习在机器学习工程(Machine Learning Engineering)领域的两个关键问题,并克服了它们,最终仅通过Qwen2.5-3B便在MLE任务上超越了仅依赖提示(prompting)的、规模更大的静态语言模型Claude3.5。
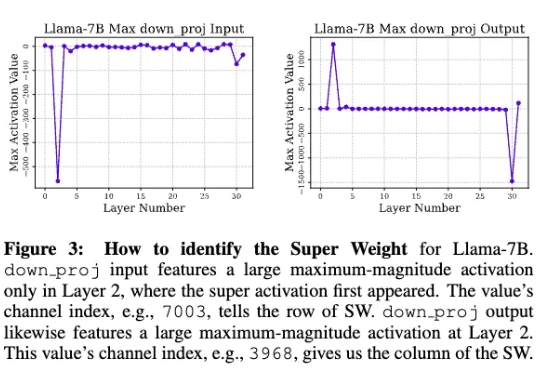
苹果研究人员发现,在大模型中,极少量的参数,即便只有0.01%,仍可能包含数十万权重,他们将这一发现称为「超级权重」。超级权重点透了大模型「命门」,使大模型走出「炼丹玄学」。
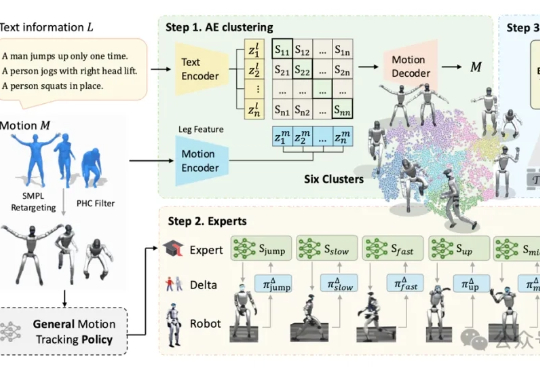
人形机器人对跳舞这件事,如今是越来越擅长了。北京大学与BeingBeyond团队联合研发的BumbleBee系统给出了最新答案:通过创新的“分治-精炼-融合”三级架构,该系统首次实现人形机器人在多样化动作中的稳定控制。
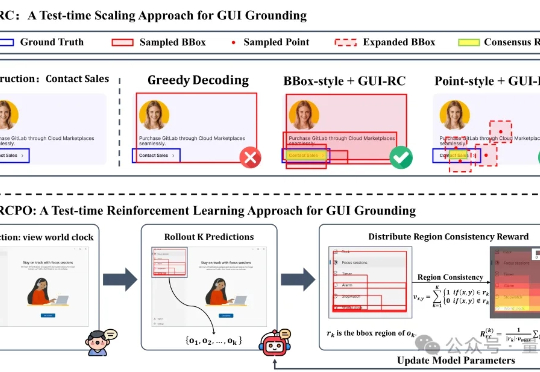
无需海量数据标注,智能体也能精确识别定位目标元素了! 来自浙大等机构的研究人员提出GUI-RCPO——一种自我监督的强化学习方法,可以让模型在没有标注的数据上自主提升GUI grounding(图形界面定位)能力。

这并非科幻片中的桥段,而是来自清华大学与北京航空航天大学团队的最新成果——BSC-Nav 的真实演示。通过模仿生物大脑构建、维护空间记忆的原理,研究团队让智能体拥有了前所未有的「空间感」。
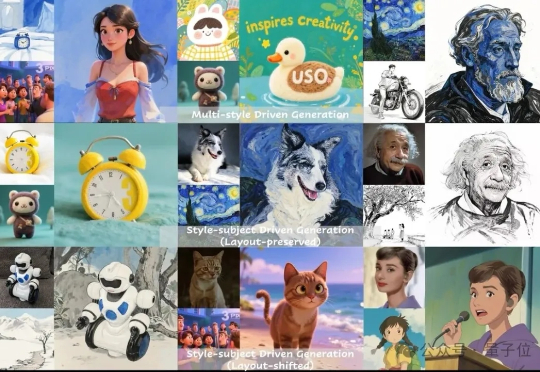
图像生成中的多指标一致性问题,被字节团队解决了! 字节UXO团队设计并开源了统一框架USO,让看上去不关联的任务相互促进,实现风格迁移和主体保持单任务和组合任务的SOTA。
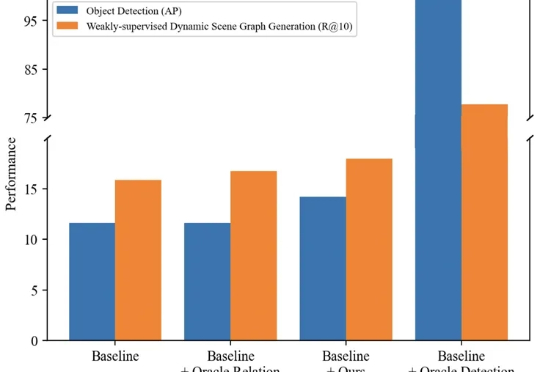
本文主要介绍来自该团队的最新论文:TRKT,该任务针对弱监督动态场景图任务展开研究,发现目前的性能瓶颈在场景中目标检测的质量,因为外部预训练的目标检测器在需要考虑关系信息和时序上下文的场景图视频数据上检测结果欠佳。