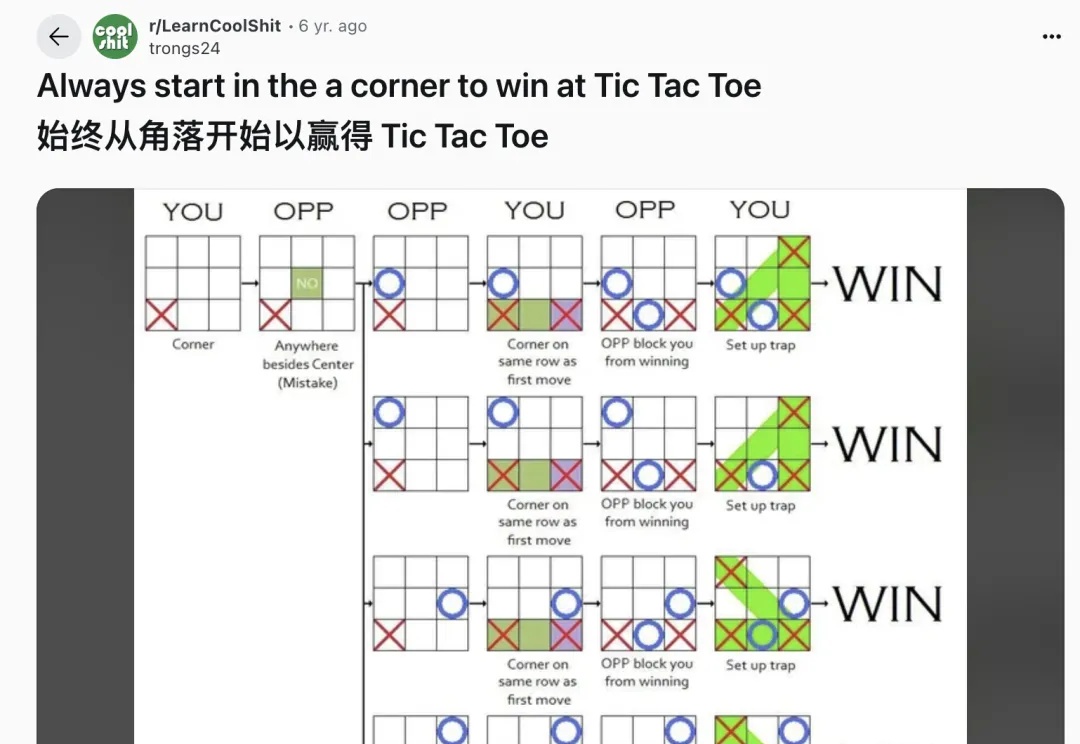
GPT-5“变笨”实锤,退休教授出了道井字棋送分题,结果它真送了
GPT-5“变笨”实锤,退休教授出了道井字棋送分题,结果它真送了退休经济学教授用一个简单问题干懵GPT-5,其拉胯表现与奥特曼口中“博士级AI”的宣传大相径庭。
来自主题: AI资讯
8161 点击 2025-09-01 17:08
 搜索
搜索
退休经济学教授用一个简单问题干懵GPT-5,其拉胯表现与奥特曼口中“博士级AI”的宣传大相径庭。
清华大学、北京中关村学院、无问芯穹联合北大、伯克利等机构重磅开源RLinf:首个面向具身智能的“渲训推一体化”大规模强化学习框架。
近期,AI营销公司橙果视界(PhotoG母公司)宣布完成数千万元新一轮融资,由云天使基金领投,力合创投和金沙江联合资本跟投。本轮融资将用于进一步扩大行业数据规模,推进垂直行业后训练模型迭代,进一步加快全链路营销智能体在多行业的业务落地,持续探索能感知、决策、创造并执行的商业大脑。
GRPO 就像一个树节点,从这里开始开枝散叶。
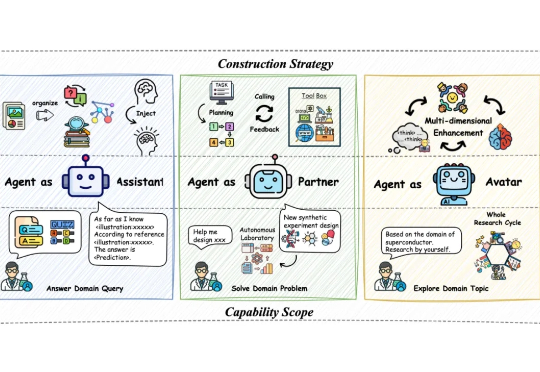
当前基于大语言模型(LLM)的智能体构建通过推动自主科学研究推动 AI4S 迅猛发展,催生一系列科研智能体的构建与应用。然而人工智能与自然科学研究之间认知论与方法论的偏差,对科研智能体系统的设计、训练以及验证产生着较大阻碍。

昨天,美团低调地开源了其560B参数的混合专家(MoE)模型——LongCat-Flash。 一时间,大家的目光都被吸引了过去,行业内的讨论大多围绕着它在公开基准测试中媲美顶尖模型的性能数据,以及其精巧的MoE架构设计。
两年半股价暴涨25倍,Palantir仍是企业级AI无出其右的领导者,甚至目前都找不出一家竞品。我们频道聚集了很多关注Palantir的朋友,大家问的最多的问题是:国内有没有真能对标Palantir的公司?
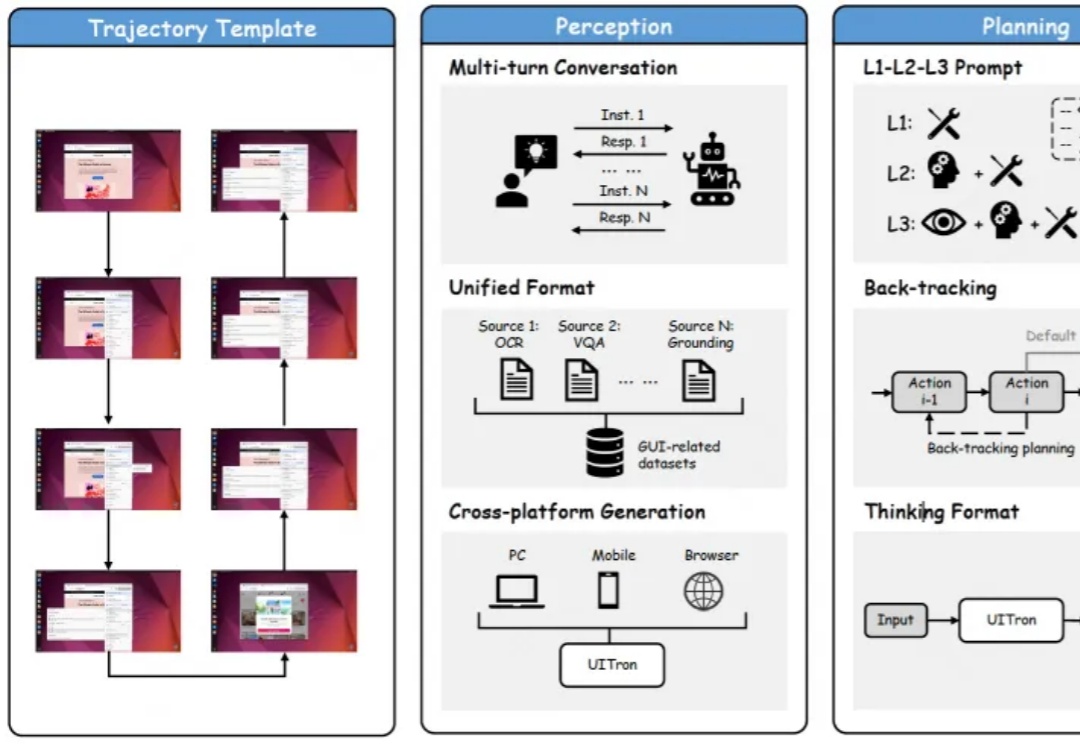
最新开源多模态智能体,能自动操作手机、电脑、浏览器的那种!开源评测榜单和中文场景交互成绩全面提升。
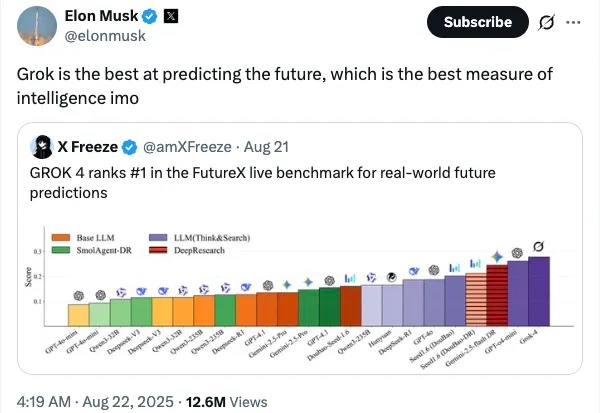
你有没有想过,AI 不仅能记住过去的一切,还能预见未知的未来?

记忆,你有我有,LLM 不一定有,但它们正在有。