
华为创造AI算力新纪录:万卡集群训练98%可用度,秒级恢复、分钟诊断
华为创造AI算力新纪录:万卡集群训练98%可用度,秒级恢复、分钟诊断大模型的落地能力,核心在于性能的稳定输出,而性能稳定的底层支撑,是强大的算力集群。其中,构建万卡级算力集群,已成为全球公认的顶尖技术挑战。
来自主题: AI技术研报
10550 点击 2025-06-10 17:05
 搜索
搜索
大模型的落地能力,核心在于性能的稳定输出,而性能稳定的底层支撑,是强大的算力集群。其中,构建万卡级算力集群,已成为全球公认的顶尖技术挑战。

游戏直播等实时渲染门槛要被击穿了?Adobe 的一项新研究带来新的可能。

为什么语言模型很成功,视频模型还是那么弱?

给大模型当老师,让它一步步按你的想法做数据分析,有多难?

测试时扩展(Test-Time Scaling)极大提升了大语言模型的性能,涌现出了如 OpenAI o 系列模型和 DeepSeek R1 等众多爆款。那么,什么是视觉领域的 test-time scaling?又该如何定义?
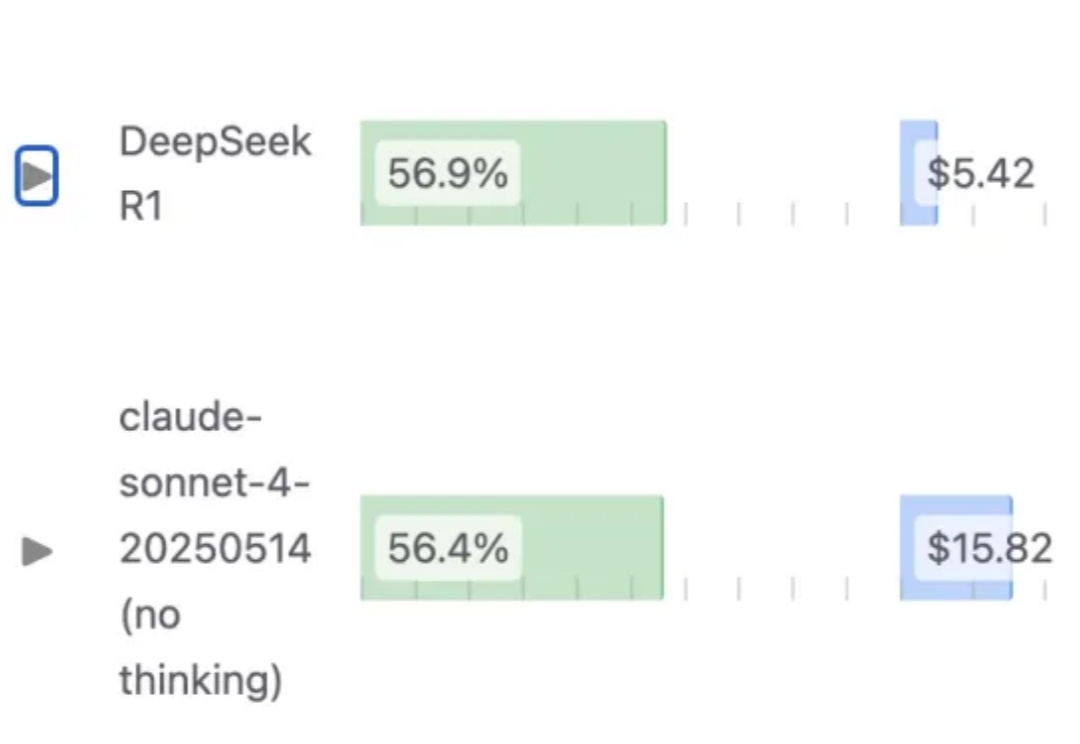
1.93bit量化之后的 DeepSeek-R1(0528),编程能力依然能超过Claude 4 Sonnet?

传统的视频编辑工作流,正在被AI彻底重塑。
王劲,香港大学计算机系二年级博士生,导师为罗平老师。研究兴趣包括多模态大模型训练与评测、伪造检测等,有多项工作发表于 ICML、CVPR、ICCV、ECCV 等国际学术会议。
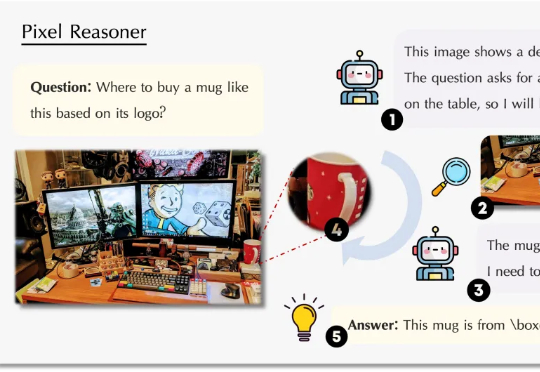
视觉语言模型(VLM)正经历从「感知」到「认知」的关键跃迁。 当OpenAI的o3系列通过「图像思维」(Thinking with Images)让模型学会缩放、标记视觉区域时,我们看到了多模态交互的全新可能。
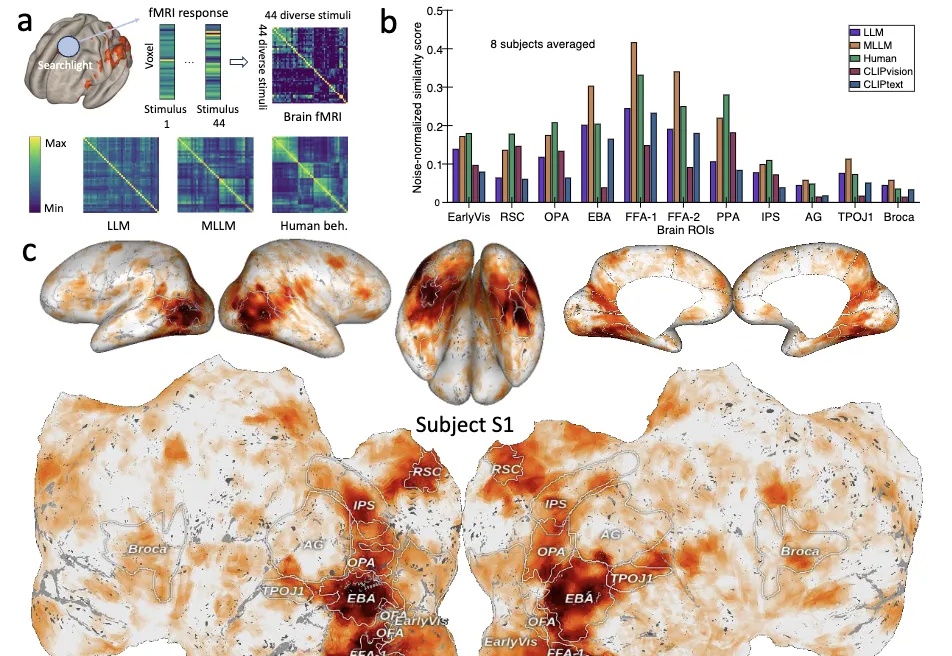
大模型≠随机鹦鹉!Nature子刊最新研究证明: 大模型内部存在着类似人类对现实世界概念的理解。