
4500美元复刻DeepSeek神话,1.5B战胜o1-preview只用RL!训练细节全公开
4500美元复刻DeepSeek神话,1.5B战胜o1-preview只用RL!训练细节全公开只用4500美元成本,就能成功复现DeepSeek?就在刚刚,UC伯克利团队只用简单的RL微调,就训出了DeepScaleR-1.5B-Preview,15亿参数模型直接吊打o1-preview,震撼业内。
来自主题: AI资讯
9095 点击 2025-02-11 15:26
 搜索
搜索
只用4500美元成本,就能成功复现DeepSeek?就在刚刚,UC伯克利团队只用简单的RL微调,就训出了DeepScaleR-1.5B-Preview,15亿参数模型直接吊打o1-preview,震撼业内。

DeepSeek 在海内外搅起的惊涛巨浪,余波仍在汹涌。当中国大模型撕开硅谷的防线之后,在预设中总是落后半拍的中国 AI 军团,这次竟完成了一次反向技术输出,引发了全球范围内复现 DeepSeek 的热潮。

近日,来自香港科技大学、南洋理工大学等机构的研究团队最新成果让这一设想成为现实。他们提出的 SelfDefend 框架,让大语言模型首次拥有了真正意义上的 ' 自卫能力 ',能够有效识别和抵御各类越狱攻击,同时保持极低的响应延迟。
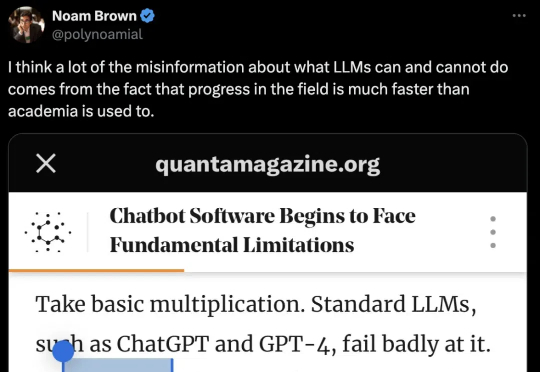
一篇报道,在AI圈掀起轩然大波。文中引用了近2年前的论文直击大模型死穴——Transformer触及天花板,却引来OpenAI研究科学家的紧急回应。谁能想到,一篇于2023年发表的LLM论文,竟然在一年半之后又「火」了。
这几天,一些人卖DeepSeek课的事冲上了热搜。什么9.9元的DeepSeek入门课,到几百块钱的deepseek变现特训营,再到线下动辄上万的本地AI训练师。甚至有卖家打出“三天精通AI,月入10万”的口号。闲鱼都快被卖课的屠榜了。
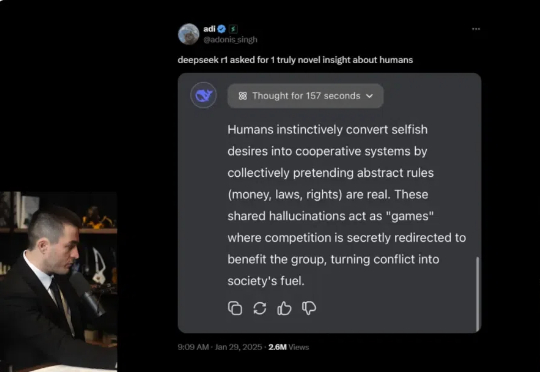
DeepSeek火了之后,知名科技主播Lex Fridman,找了两位嘉宾,从 DeepSeek 及其开源模型 V3 和 R1 谈到了 AI 发展的地缘政治竞争,特别是中美在 AI 芯⽚与技术出⼝管制上的博弈。5 个小时的对谈,基于「赛博禅心」的翻译版本,我们精选出了5 万字,基本把 DeepSeek 的创新、目前 AI 的算力问题、AI 训练和蒸馏、以及产品落地等都聊透了。建议收藏后仔细阅读。
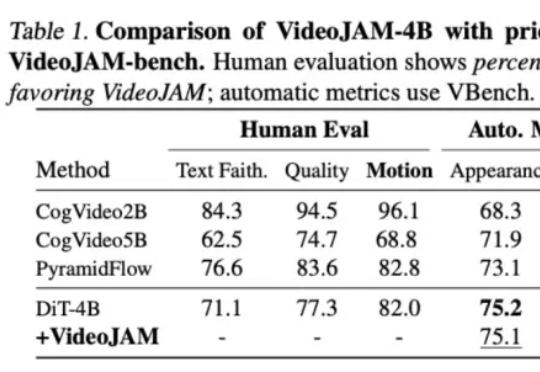
针对视频生成中的运动一致性难题,Meta GenAI团队提出了一个全新框架VideoJAM。VideoJAM基于主流的DiT路线,但和Sora等纯DiT模型相比,动态效果直接拉满:
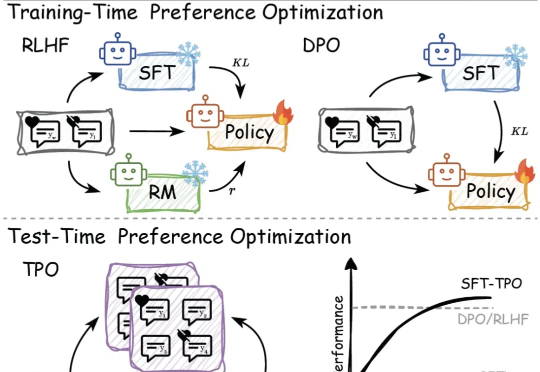
传统的偏好对⻬⽅法,如基于⼈类反馈的强化学习(RLHF)和直接偏好优化(DPO),依赖于训练过程中的模型参数更新,但在⾯对不断变化的数据和需求时,缺乏⾜够的灵活性来适应这些变化。
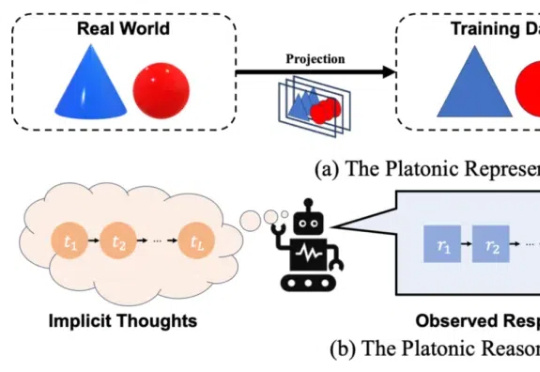
「慢思考」(Slow-Thinking),也被称为测试时扩展(Test-Time Scaling),成为提升 LLM 推理能力的新方向。近年来,OpenAI 的 o1 [4]、DeepSeek 的 R1 [5] 以及 Qwen 的 QwQ [6] 等顶尖推理大模型的发布,进一步印证了推理过程的扩展是优化 LLM 逻辑能力的有效路径。
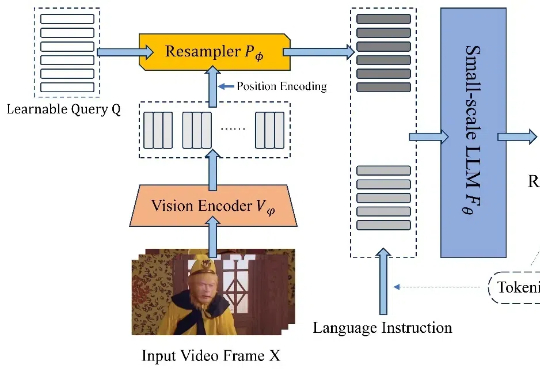
近日,北京航空航天大学的研究团队基于 TinyLLaVA_Factory 的原项目,推出小尺寸简易视频理解框架 TinyLLaVA-Video,其模型,代码以及训练数据全部开源。在计算资源需求显著降低的前提下,训练出的整体参数量不超过 4B 的模型在多个视频理解 benchmark 上优于现有的 7B + 模型。