
AI会「说谎」,RLHF竟是帮凶
AI会「说谎」,RLHF竟是帮凶虽然 RLHF 的初衷是用来控制人工智能(AI),但实际上它可能会帮助 AI 欺骗人类。
来自主题: AI资讯
6113 点击 2024-09-23 15:17
 搜索
搜索
虽然 RLHF 的初衷是用来控制人工智能(AI),但实际上它可能会帮助 AI 欺骗人类。

DeepMind最近的研究提出了一种新框架AligNet,通过模拟人类判断来训练教师模型,并将类人结构迁移到预训练的视觉基础模型中,从而提高模型在多种任务上的表现,增强了模型的泛化性和鲁棒性,为实现更类人的人工智能系统铺平了道路。

视觉 / 激光雷达里程计是计算机视觉和机器人学领域中的一项基本任务,用于估计两幅连续图像或点云之间的相对位姿变换。它被广泛应用于自动驾驶、SLAM、控制导航等领域。最近,多模态里程计越来越受到关注,因为它可以利用不同模态的互补信息,并对非对称传感器退化具有很强的鲁棒性。

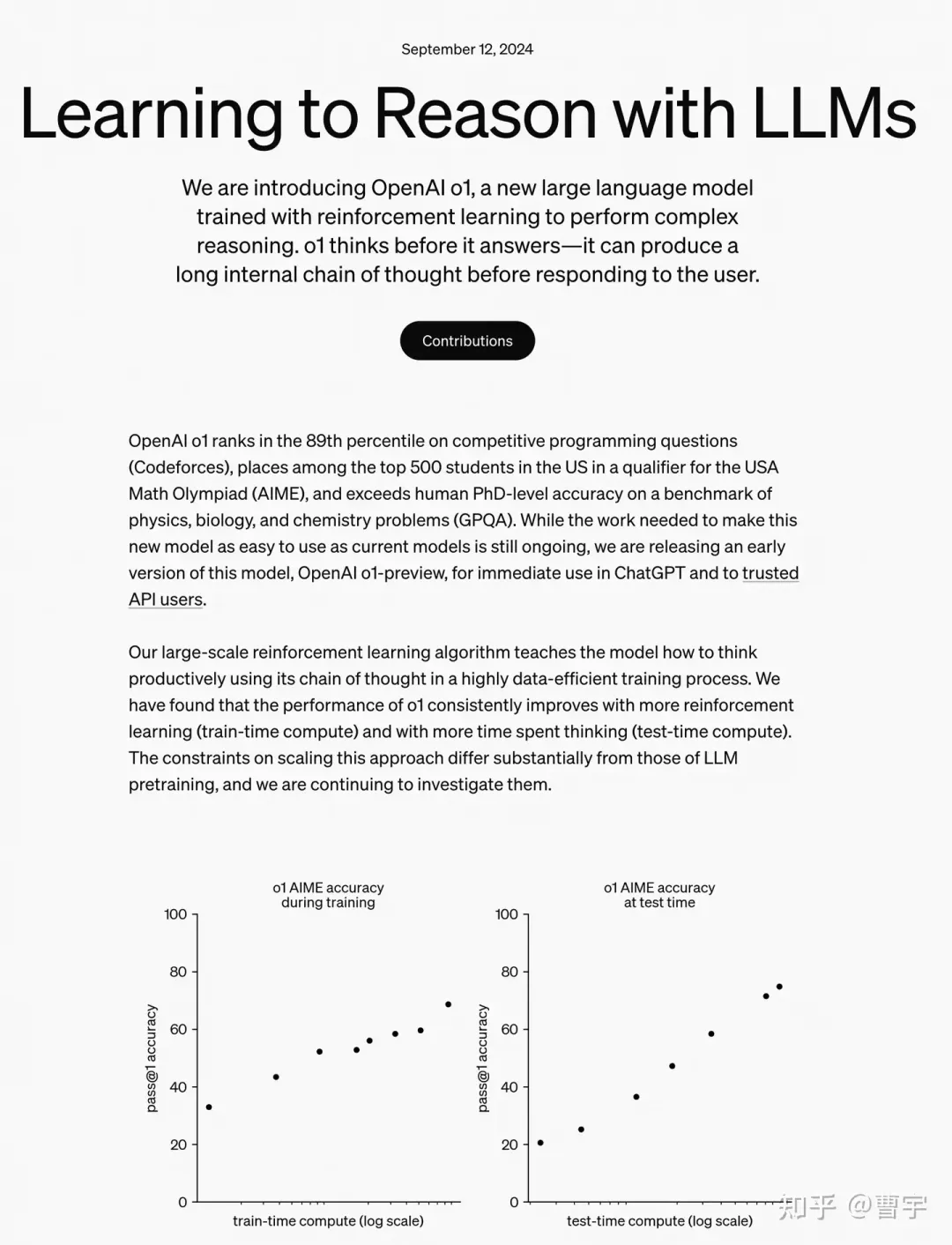
自从 OpenAI 的 o1 问世以来,它强大的推理能力就承包了 AI 圈近期的热搜。不需要专门训练,它就能直接拿下数学奥赛金牌,甚至可以在博士级别的科学问答环节上超越人类专家。

扩展多模态大语言模型(MLLMs)的长上下文能力对于视频理解、高分辨率图像理解以及多模态智能体至关重要。这涉及一系列系统性的优化,包括模型架构、数据构建和训练策略,尤其要解决诸如随着图像增多性能下降以及高计算成本等挑战。

CoT只对数学、符号推理才起作用,其他的任务几乎没什么卵用!这是来自UT-Austin、霍普金斯、普林斯顿三大机构研究人员联手,分析了100+篇论文14类任务得出的结论。看来,CoT并非是所有大模型标配。
OpenAI的self-play RL新模型o1最近交卷,直接引爆了关于对于self-play的讨论。

o1,Inference law,推理定律,模型训练

随OpenAI爆火的CoT,已经引发了大佬间的激战!谷歌DeepMind首席科学家Denny Zhou拿出一篇ICLR 2024论文称:CoT可以让Transformer推理无极限。但随即他就遭到了田渊栋和LeCun等的质疑。最终,CoT会是通往AGI的正确路径吗?

演员导演谈妥与否,目前不得而知