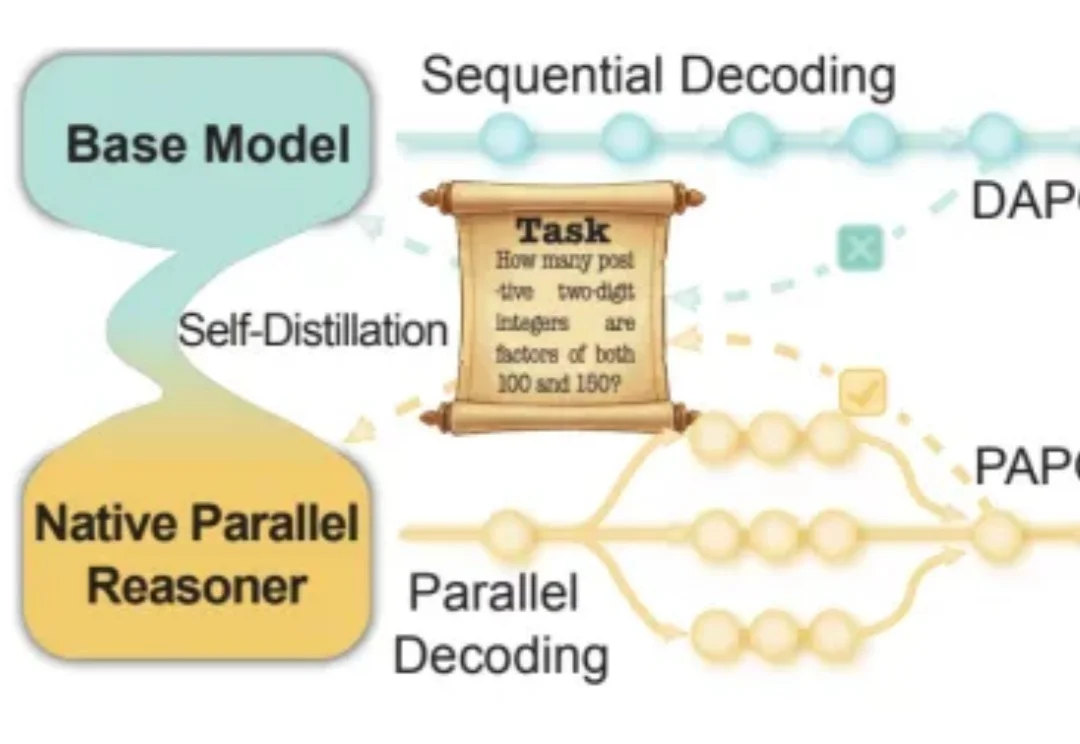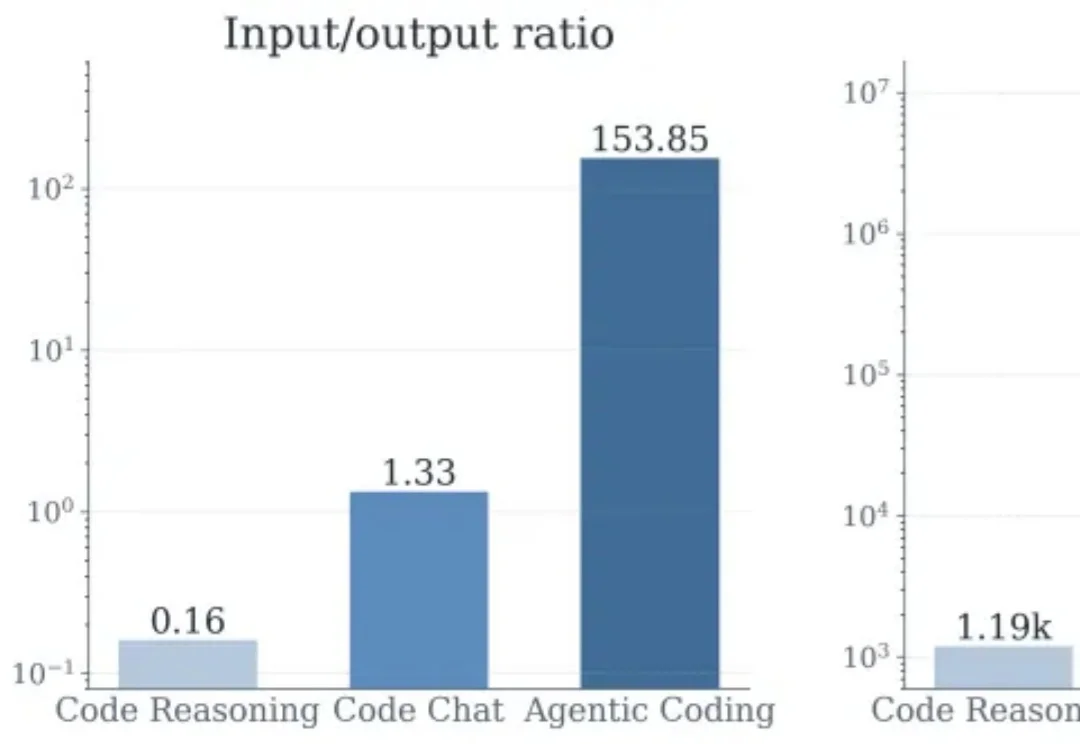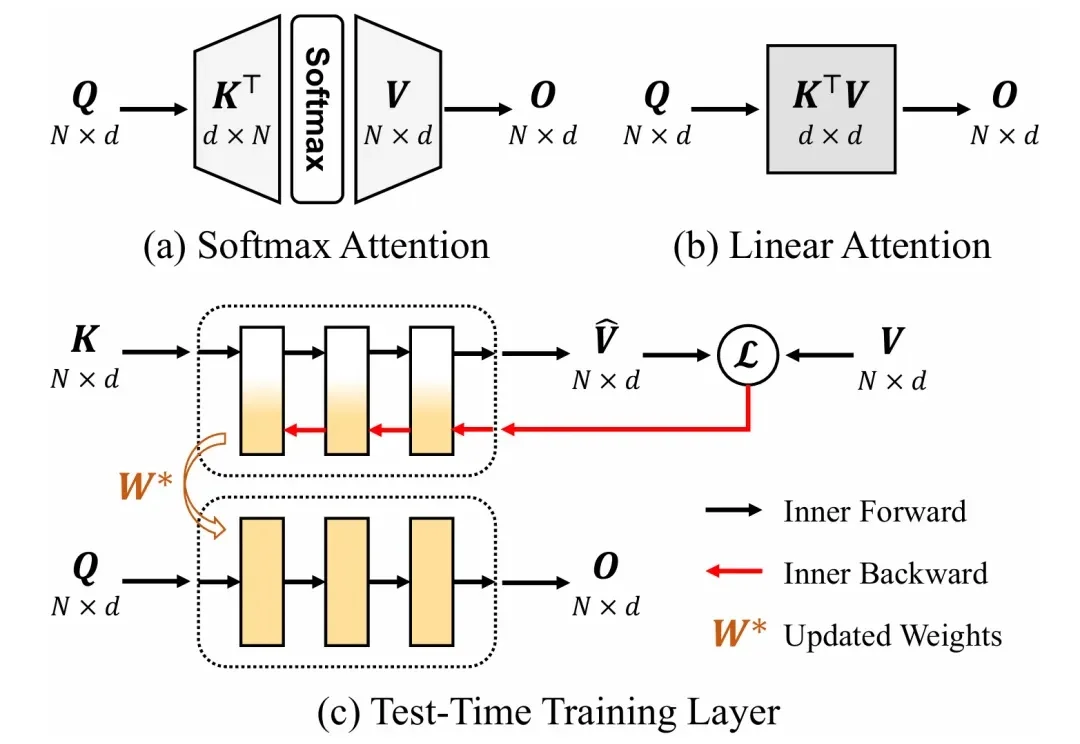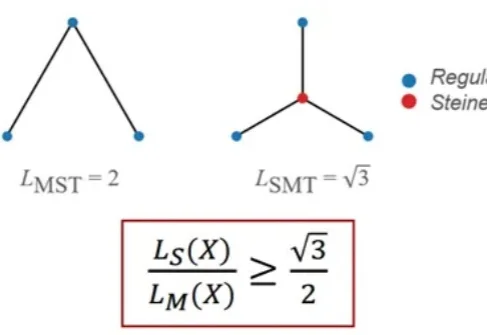
ICML 2026 | 突破3DGS光度多义性瓶颈:北航/新国立提出AmbiSuR,重塑高保真3D几何重建
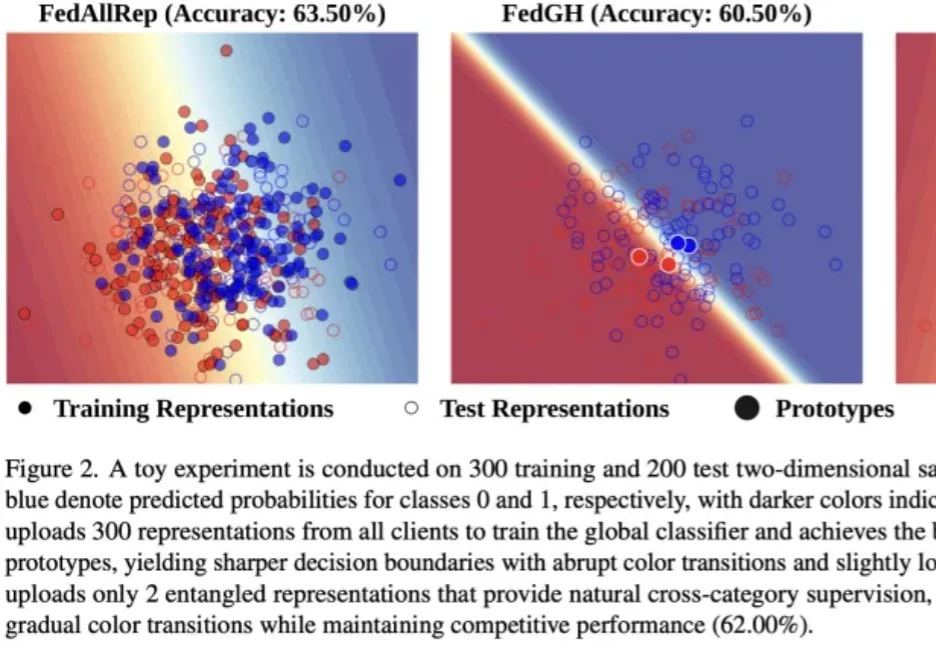
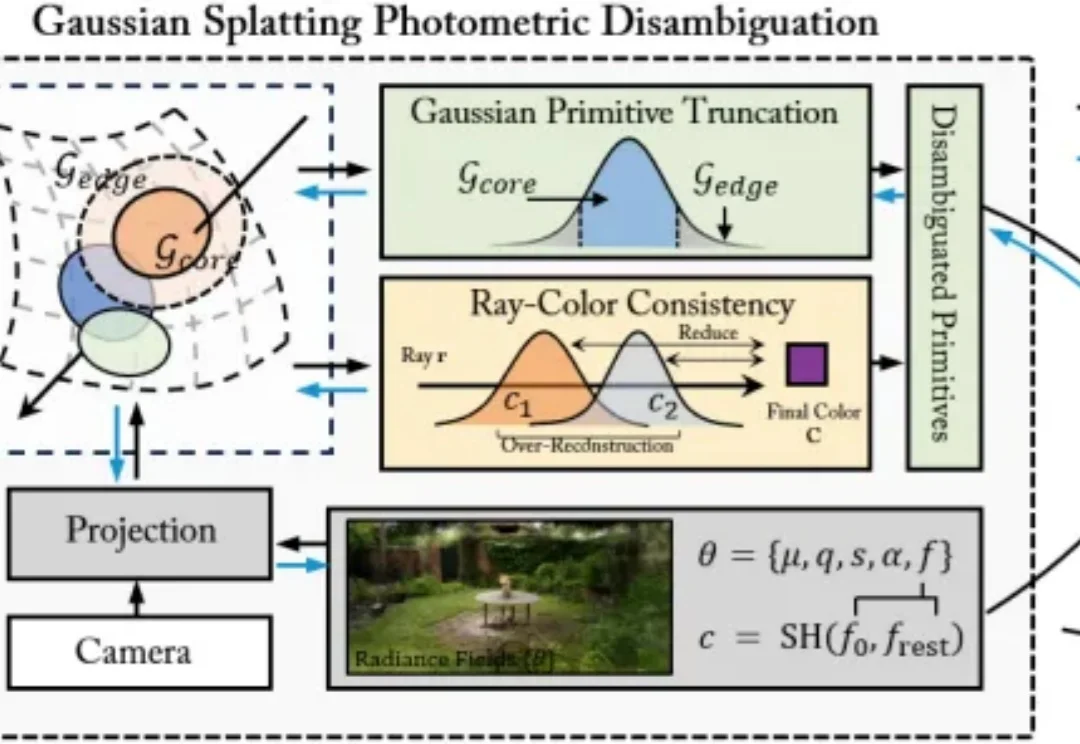
ICML 2026 | 突破3DGS光度多义性瓶颈:北航/新国立提出AmbiSuR,重塑高保真3D几何重建近年来,3D 高斯泼溅(3D Gaussian Splatting, 3DGS)凭借其卓越的新视角合成能力和实时的渲染效率,极大地推动了神经渲染技术的发展。然而,当研究者试图直接从 3DGS 中提取精确的 3D 几何表面(Mesh 等)时,往往会面临严重的几何失真问题。
来自主题: AI技术研报
8882 点击 2026-05-19 14:57