合成数据≠生成模型:一文读懂合成数据的全新范式
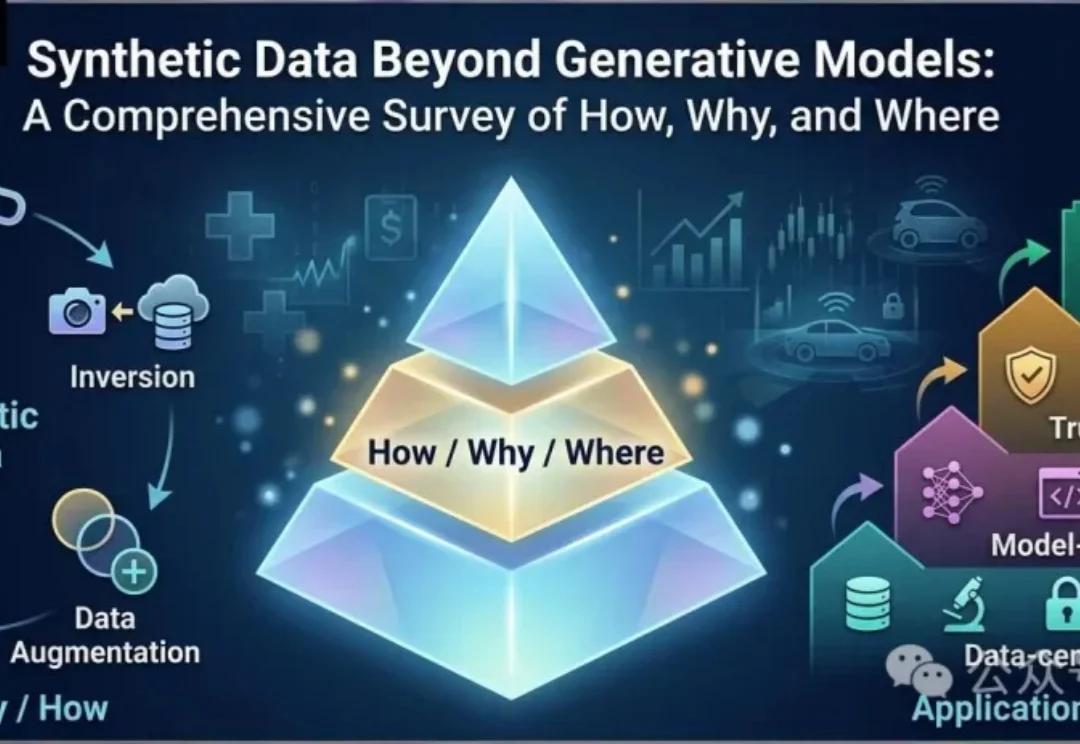
合成数据≠生成模型:一文读懂合成数据的全新范式最新研究提出合成数据的全新分类框架,突破「生成模型=合成数据」的传统认知,涵盖反演、仿真与数据增强等方法,并按应用层次划分为数据中心AI、模型中心AI、可信AI和具身AI。
来自主题: AI技术研报
6767 点击 2026-04-16 16:06
 搜索
搜索
最新研究提出合成数据的全新分类框架,突破「生成模型=合成数据」的传统认知,涵盖反演、仿真与数据增强等方法,并按应用层次划分为数据中心AI、模型中心AI、可信AI和具身AI。

一个在 AI 社区广泛流传的架构思路,正在让大量团队走弯路。
Hermes Agent最近在AI圈彻底火了。
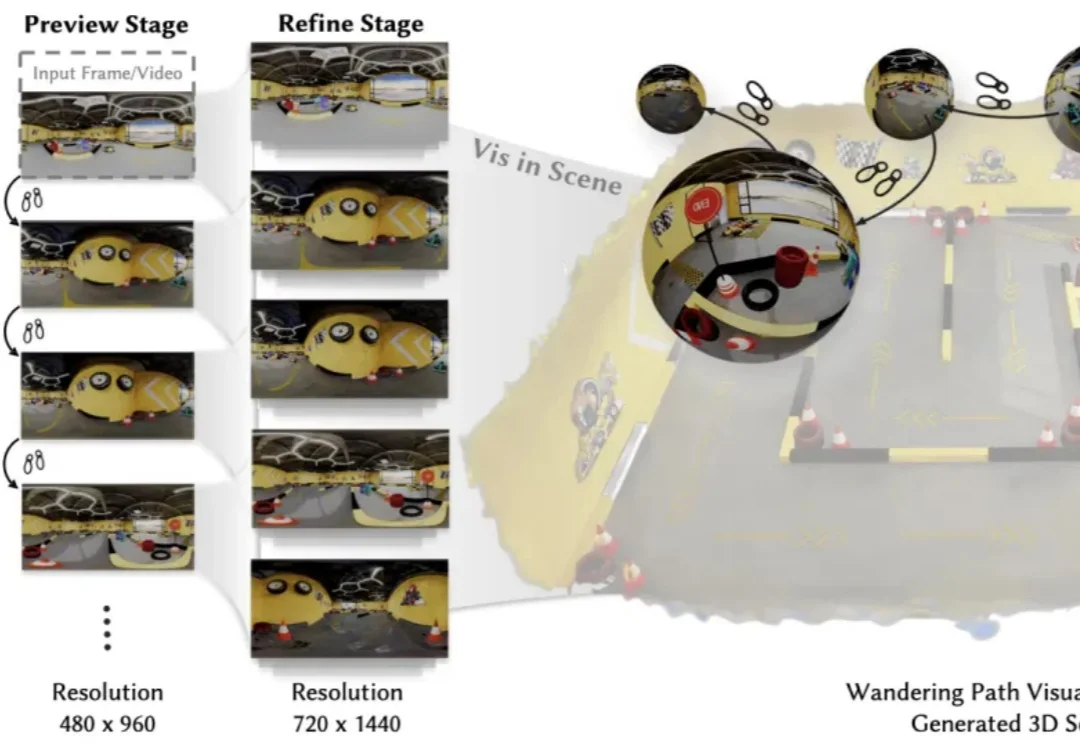
在生成式视频快速发展的今天,模型已经能够生成高质量的短视频片段,但一个更具挑战性的问题正逐渐成为研究焦点:

当大模型训练进入深水区,竞争的关键已经不再只是「模型参数怎么调」,而逐渐转向一个更核心、也更难系统解决的问题:模型在训练过程中究竟看到了什么数据、以什么比例看到、哪些样本应该被更频繁地学习。
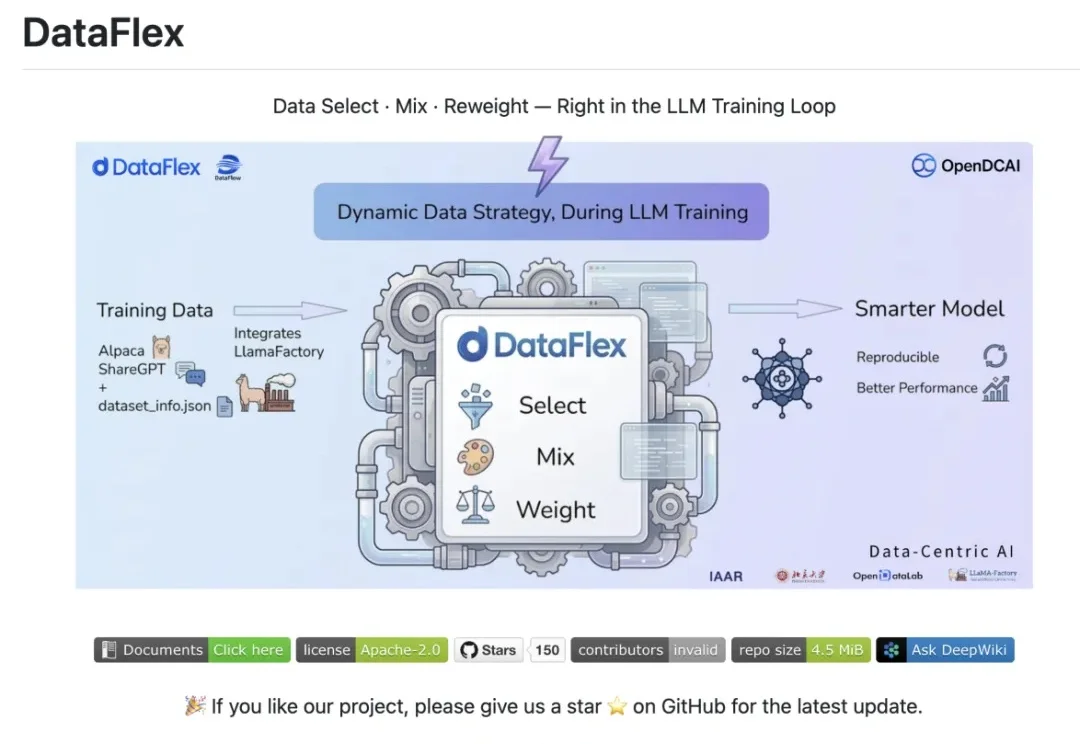
当大模型训练进入深水区,竞争的关键已经不再只是「模型参数怎么调」,而逐渐转向一个更核心、也更难系统解决的问题:模型在训练过程中究竟看到了什么数据、以什么比例看到、哪些样本应该被更频繁地学习。

今天这个世界,正在不断放大一种渴望:人们愈发渴望被另一个人真正看见。而这,恰恰是AI治疗师永远无法给予的。

近年来研究者们一直在试图通过仿真环境批量产出具身训练数据。
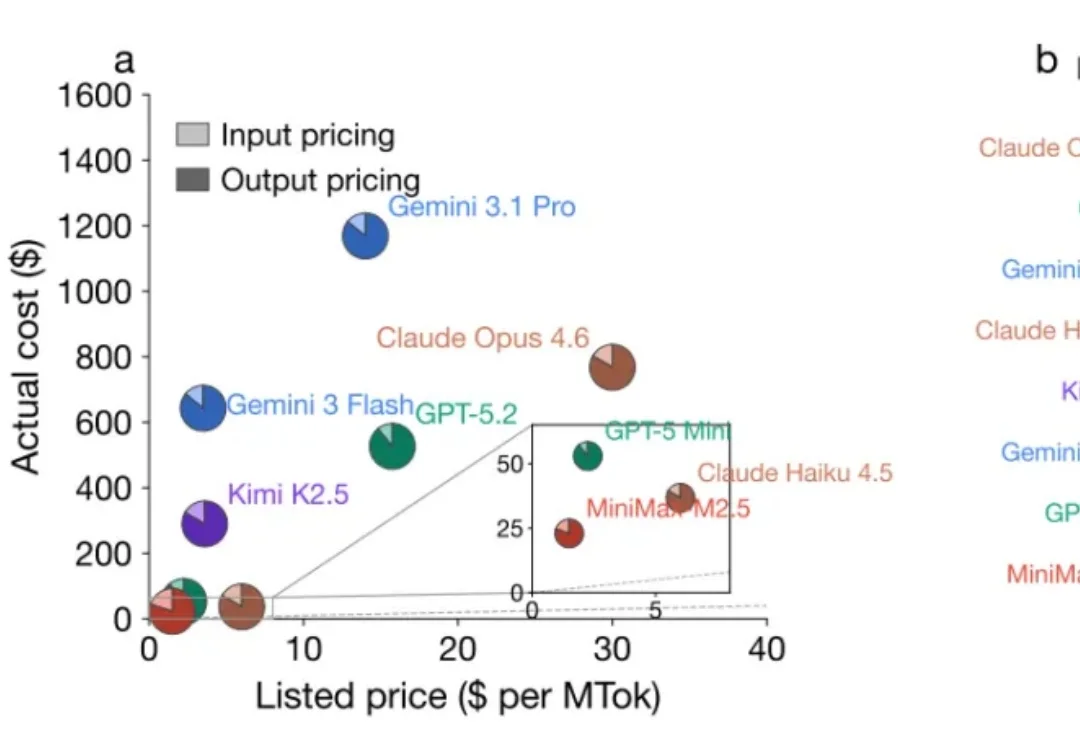
在选择使用大模型 (LLM) 时,除了模型性能强弱,价格也是一个重要指标。人们通常会用大模型的 API 定价更贵或更便宜,来比较模型的价格高低。但事实上,定价低的模型真的比定价高的模型使用起来更便宜吗?

代码大模型会写代码,这件事已经不新鲜了。