
告别直接生成,文生图进入Agent时代:港中文联合伯克利开源Gen-Searcher
告别直接生成,文生图进入Agent时代:港中文联合伯克利开源Gen-Searcher过去两年,图像生成模型在质感和审美上一路狂飙,但大多仍是 “直接出图” 的范式。
来自主题: AI技术研报
7187 点击 2026-04-10 08:34
 搜索
搜索
过去两年,图像生成模型在质感和审美上一路狂飙,但大多仍是 “直接出图” 的范式。

Claude Code这样私有的编程智能体虽然能力强大,但有着封闭、昂贵、难以定制的局限。艾伦研究院推出的Open Coding Agents,让你只需要400美元就能训练一个32B的专属编程智能体。

RL之后,大模型为什么更容易「越训越单一」?面对五花八门的改进思路,也许答案并不复杂:先试着改一改KL项。

对本地部署玩家,尤其是Mac用户来说,长上下文推理最大的痛点往往不是“模型不够聪明”,而是稍微多用点上下文,统一内存就被撑爆了”,这一点在最近的Gemma-4 31B的部署中尤为明显,在同等上下文的情况,显存占用比Qwen3.5-27B高约一倍不止,直接劝退了不少人。但好消息是,谷歌近期提出的TurboQuant KV缓存量化算法,正是为了解决这个痛点而生。
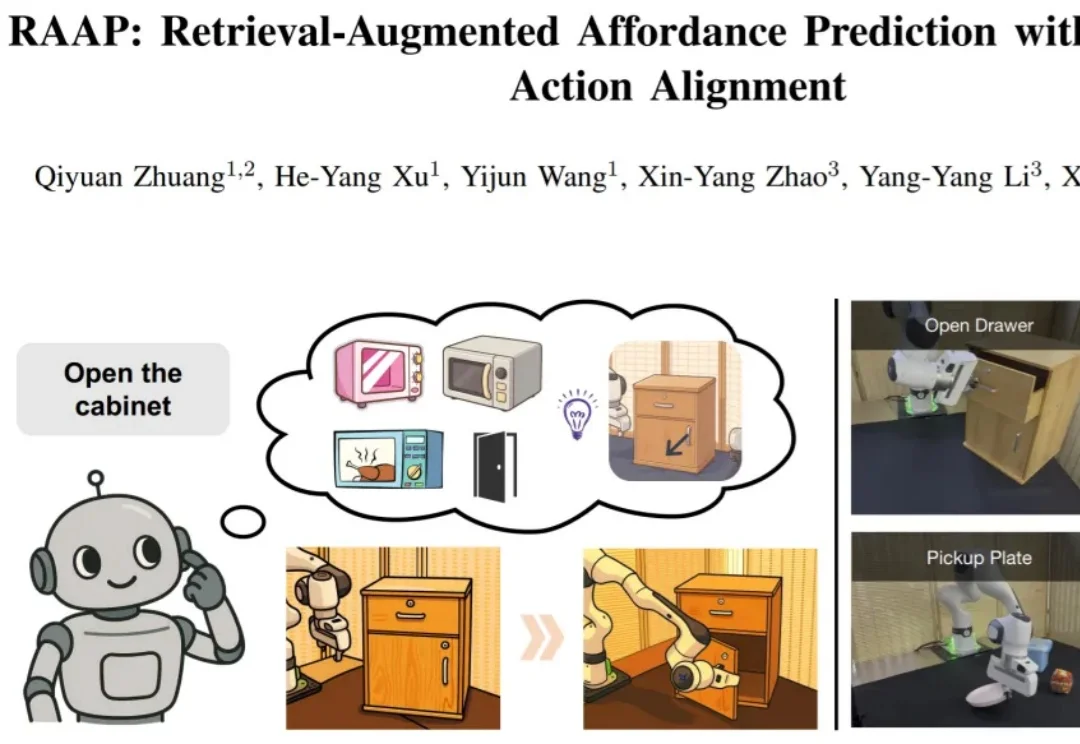
在具身智能领域,可供性(affordance)预测 —— 即让机器人从视觉观测中理解 "在哪里操作"(接触点)与 "如何操作"(动作方向)—— 是实现精细化机器人操作的基础之一。精细操作要求机器人不仅能定位到物体的可交互区域,更要掌握接触后的准确运动方向,例如判断抽屉把手的精确拉动方向完成开合。
大模型(LLM)的世界知识和推理能力是实现下一代推荐系统,即基于大模型的推荐系统(LLM4Recsys)的重要基石。来自meta ai的研究者们尝试将推理模型引入再排序阶段,推荐系统的最后一环。

专门为短剧、动漫和影视内容创作训练的垂直模型,长什么样?

Gemma4 31B的发布,在开源模型社区引发了巨大的关注。面对这款由谷歌DeepMind于2026年4月2日 推出的重磅模型,很多技术团队和本地部署玩家都在问同一个问题:Gemma4的出现,到底是在开辟一条新的本地部署路线,还是只是给高端玩家多了一个可选项?我们到底需不需要把现有的Qwen3.5 27B工作流整体迁移过去?
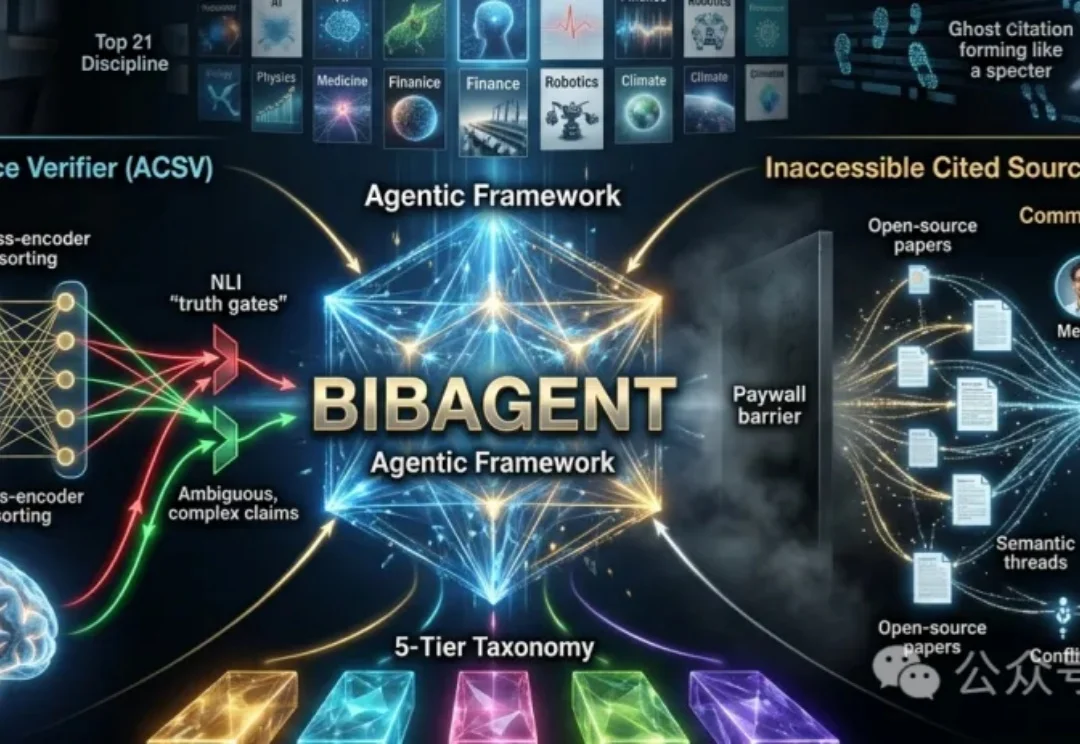
大模型正在批量生成「看起来很像真的」学术论述,但这些论述背后的引用,真的成立吗?更关键的是:当被引论文被付费墙锁住、原文根本读不到时,自动化核验是否就注定失效?
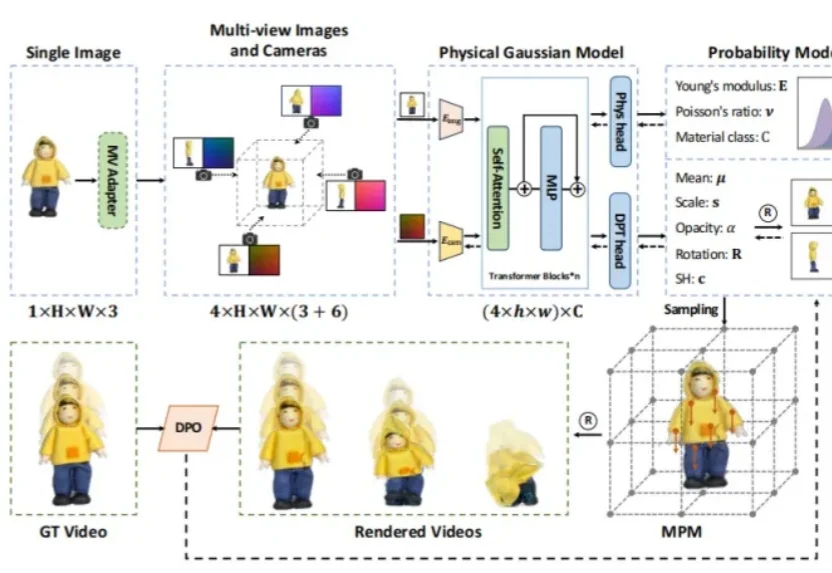
让静态的图片变成三维物体并动起来已经不算新鲜,但如果让图片不仅动起来,还能完美遵循现实世界的物理规律(比如蛋糕的Q弹、沙堆的散落、石雕的坚硬)呢?