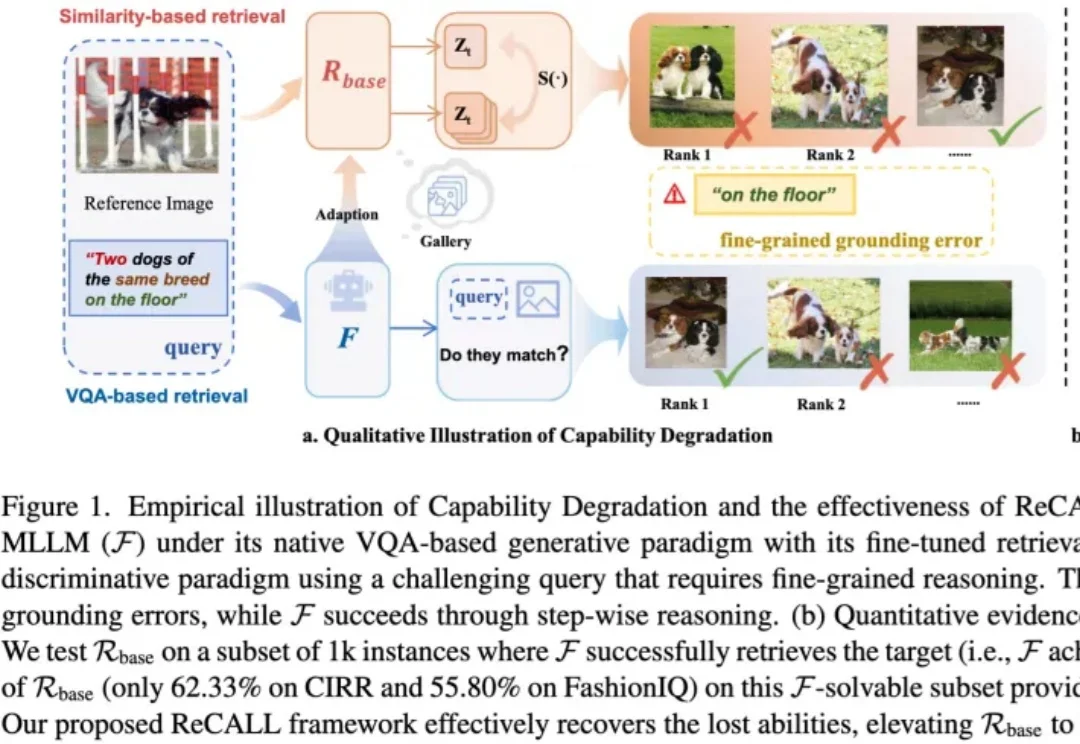
用雨伞「钓」无人机?首个针对自主目标跟踪闭环系统的物理攻击
用雨伞「钓」无人机?首个针对自主目标跟踪闭环系统的物理攻击研究者用特制雨伞干扰无人机视觉系统,让其误判目标在远去,从而失控俯冲。FlyTrap攻击无需信号干扰,仅靠物理图案就能欺骗多款商用无人机,实现静默捕获或击毁。实验显示,物理闭环攻击成功率超60%,且对新人物、新场景均有强泛化能力。这项研究揭示了AI感知系统的重大安全隐患,警示我们:视觉安全正成为智能设备的阿喀琉斯之踵。
来自主题: AI技术研报
10676 点击 2026-04-07 14:28