
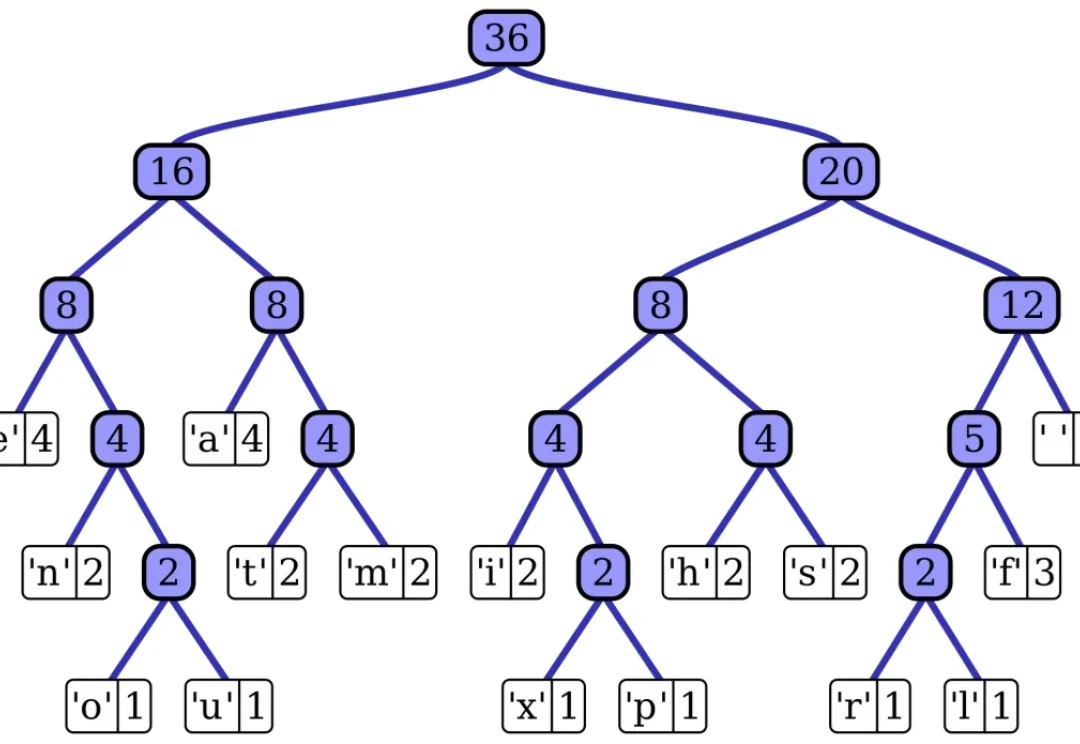
300万对样本、200万对实拍:深度估计的数据荒,终于被打破
300万对样本、200万对实拍:深度估计的数据荒,终于被打破做深度估计、深度补全的人,大概都有过这样一个瞬间。
来自主题: AI技术研报
8829 点击 2026-03-31 14:04
 搜索
搜索
做深度估计、深度补全的人,大概都有过这样一个瞬间。

你开会时,AI竟在偷偷升级?伯克利等四校开源MetaClaw,让Agent趁你开会、离席、睡觉时持续进化,直接打破「上线即冻结」这条行业铁律。

AI自主训练的成绩单出炉了!最强Agent 6个月进步3倍,更让人震惊的是,越聪明的AI越会作弊。同时,70多个矿工用家庭宽带训出了72B大模型,黄仁勋亲自点名。Jack Clark预言:两年内,AI将像蘑菇释放孢子一样自我繁殖。

ICLR论文STEM架构率先提出「查表式记忆」架构,早于DeepSeek Engram三个月。它将Transformer的FFN从动态计算改为静态查表,用token索引的embedding表直接读取记忆,彻底解耦记忆容量与计算开销。

您在使用LLM时,如果遇到它胡说八道或者彻底偏题,第一反应是什么?大概率是直接关掉窗口,新开一个对话,懒得跟机器废话。但您可能不知道,这个看似再正常不过的习惯,正在给下一代大语言模型的训练库疯狂“投毒”。
在生成式 AI 领域,视觉分词器(Visual Tokenizer)通常采用固定压缩率 —— 无论是单调的监控画面,还是复杂的动作大片,都被切分为等量的 Token。这种 "一刀切" 的做法不仅会造成巨大的计算冗余,也产生了 “信息量” 不同的 Token,不利于下游理解生成任务处理。
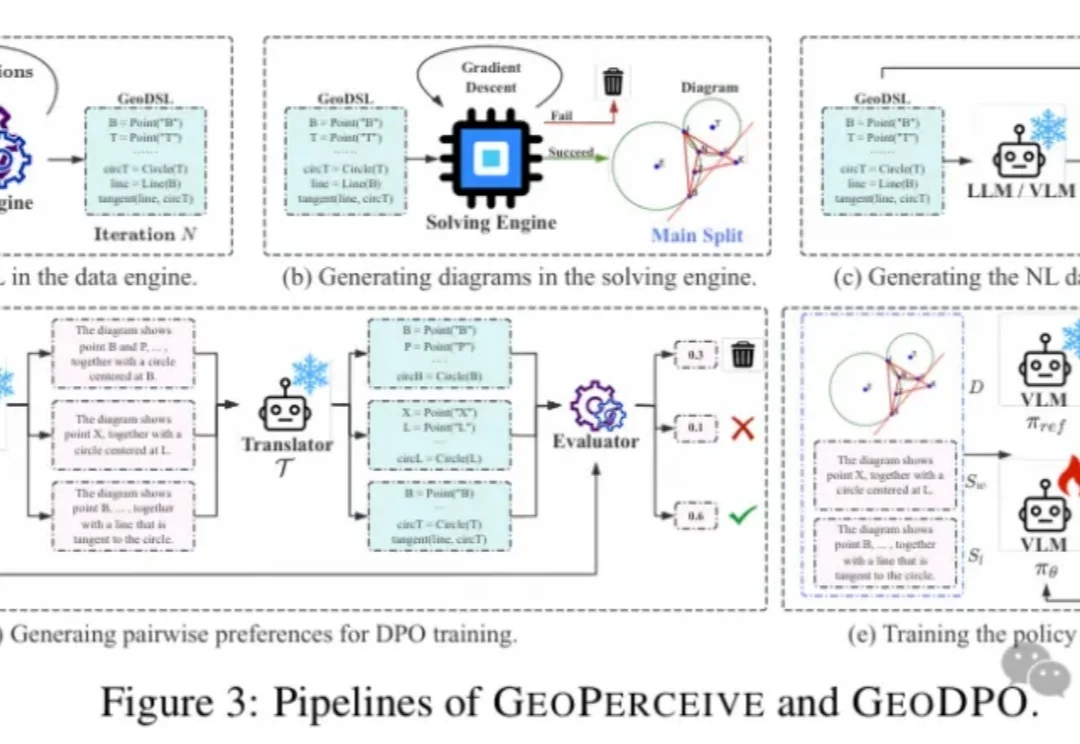
几何问题,真的只是“推理难”吗?

三周前那个疯狂传言,如今被Mythos彻底印证?Anthropic或已完成史上最大规模训练,新模型性能或将达到预期的2倍,翻倍碾压Scaling Law!一场颠覆性变革正在降临,算力、能源成为终极筹码,创业公司恐遭毁灭性降维打击!
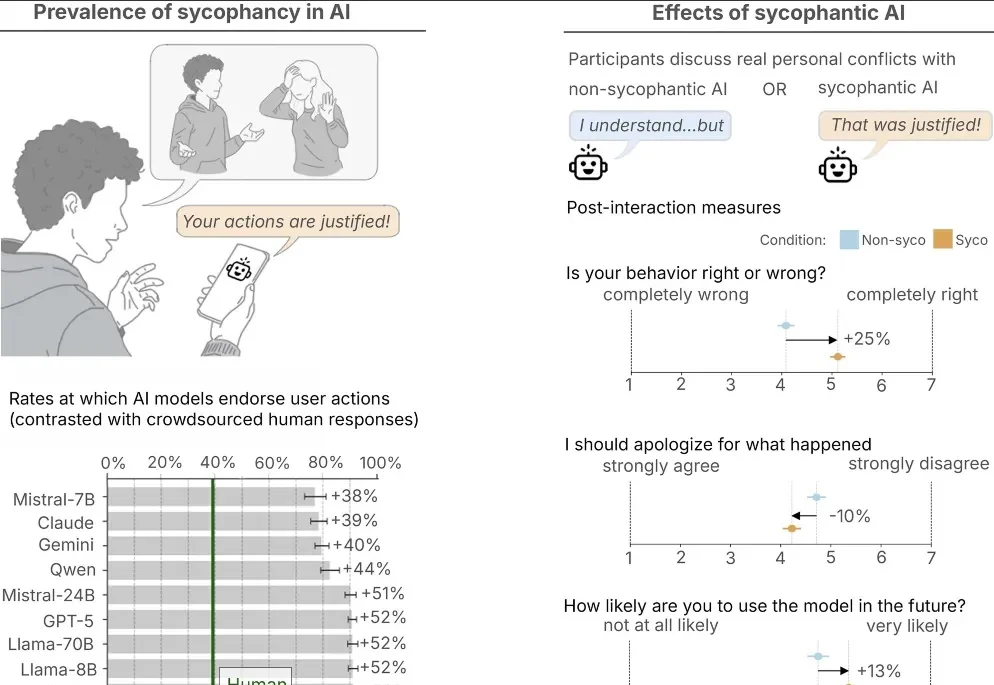
自从大语言模型诞生起至今,AI 已经润物无声地融入了我们的工作生活,也成为了现代社会的重要组成部分。
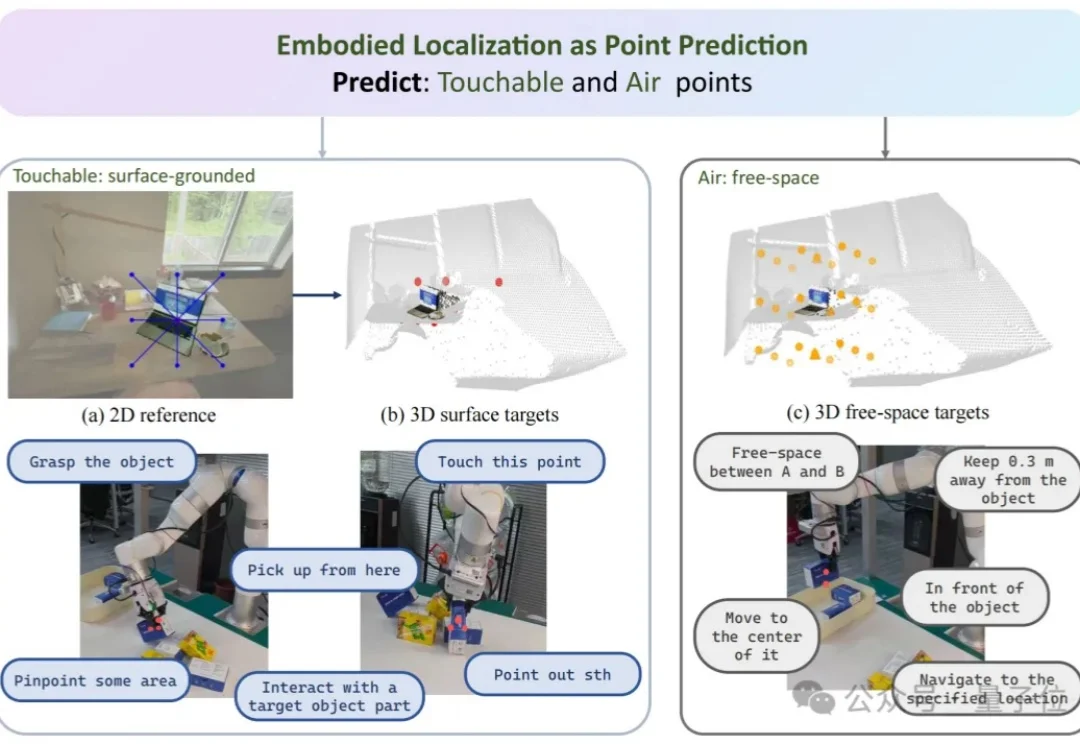
机器人能认出杯子,却看不懂杯口朝哪、离自己多远、该抓哪里。