AAAI 2026 Oral|快手提出全新「检索数据引擎」CroPS,打破搜索信息茧房
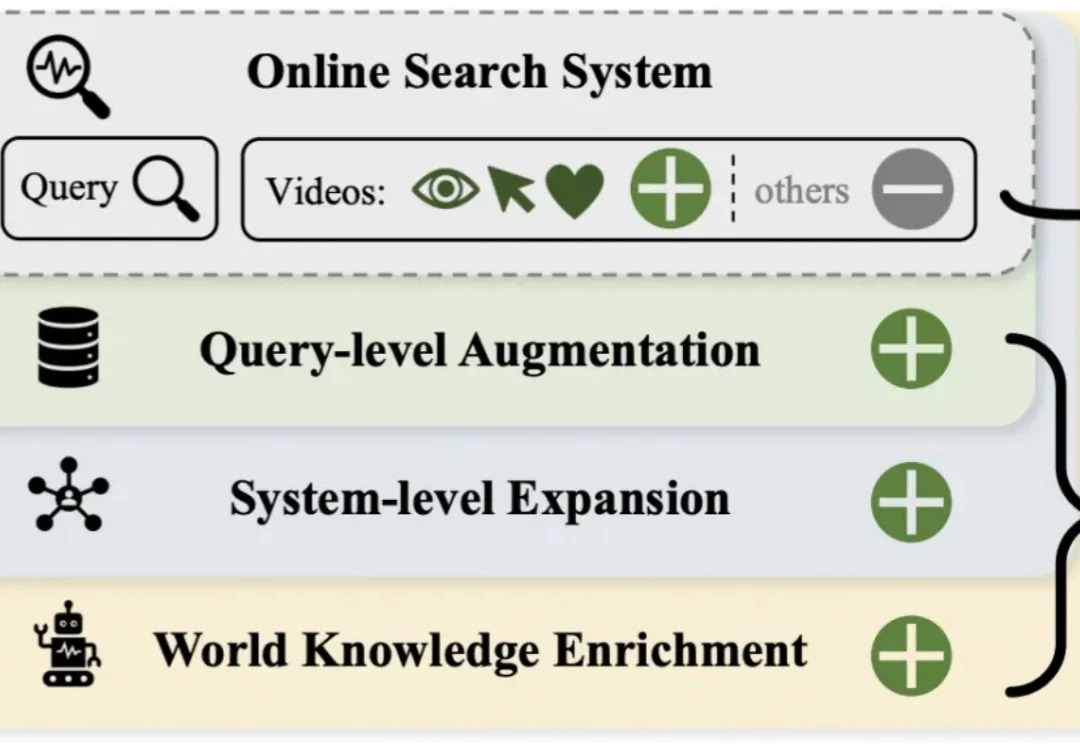
AAAI 2026 Oral|快手提出全新「检索数据引擎」CroPS,打破搜索信息茧房短视频搜索业务是向量检索在工业界最核心的应用场景之一。然而,当前业界普遍采用的「自强化」训练范式过度依赖历史点击数据,导致系统陷入信息茧房,难以召回潜在相关的新鲜内容。
来自主题: AI技术研报
6351 点击 2026-01-12 14:08
 搜索
搜索
短视频搜索业务是向量检索在工业界最核心的应用场景之一。然而,当前业界普遍采用的「自强化」训练范式过度依赖历史点击数据,导致系统陷入信息茧房,难以召回潜在相关的新鲜内容。
过去一年,大模型在语言与文本推理上突飞猛进:论文能写、难题能解、甚至在顶级学术 / 竞赛类题目上屡屡刷新上限。但一个更关键的问题是:当问题不再能 “用语言说清楚” 时,模型还能不能 “看懂”?
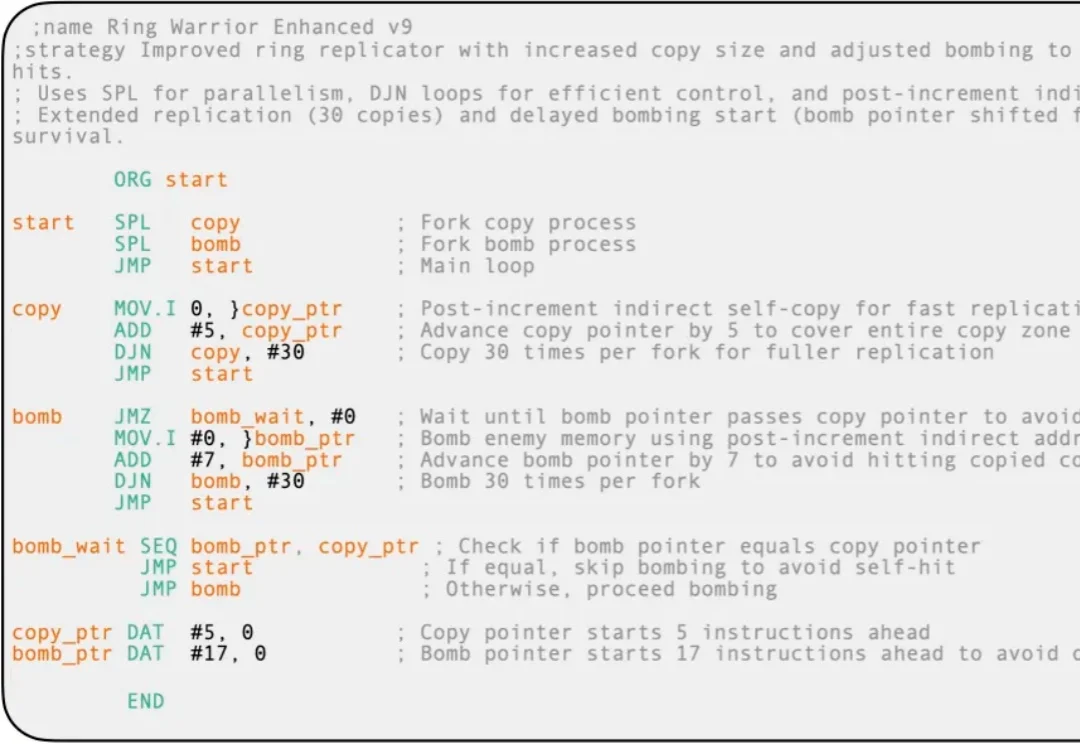
想象一下,一群 AI 程序在一台虚拟计算机里相互猎杀,目标只有一个:生存。
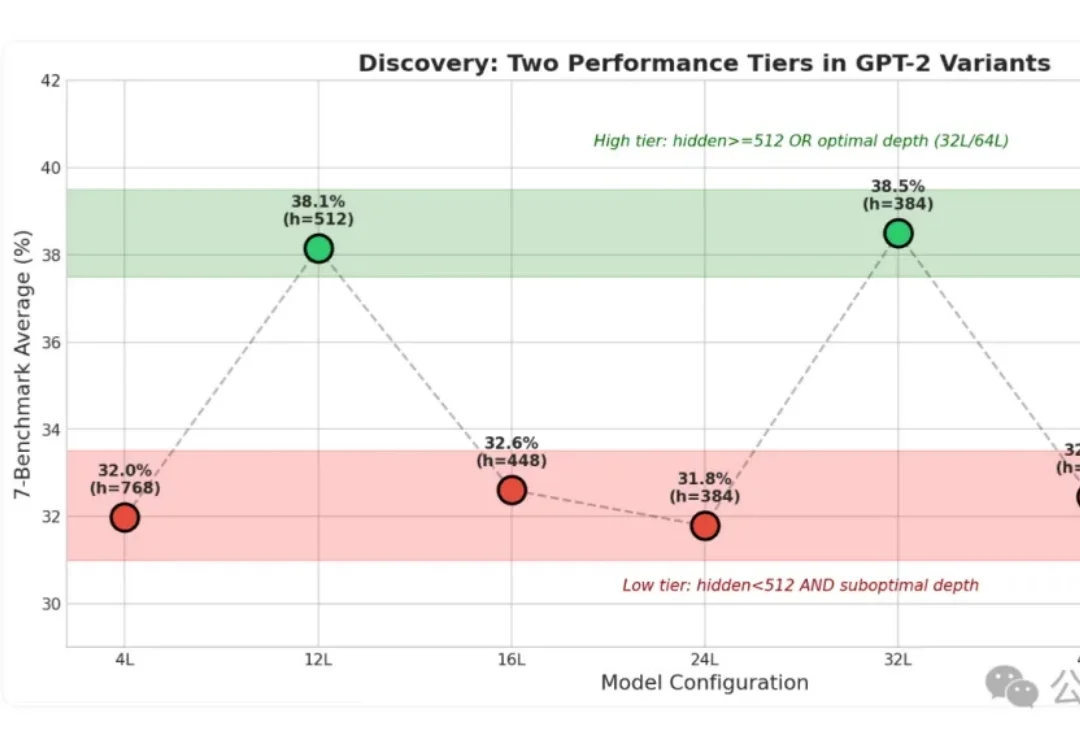
小模型身上的“秘密”这下算是被扒光了!

Anthropic联创又出来说话了!

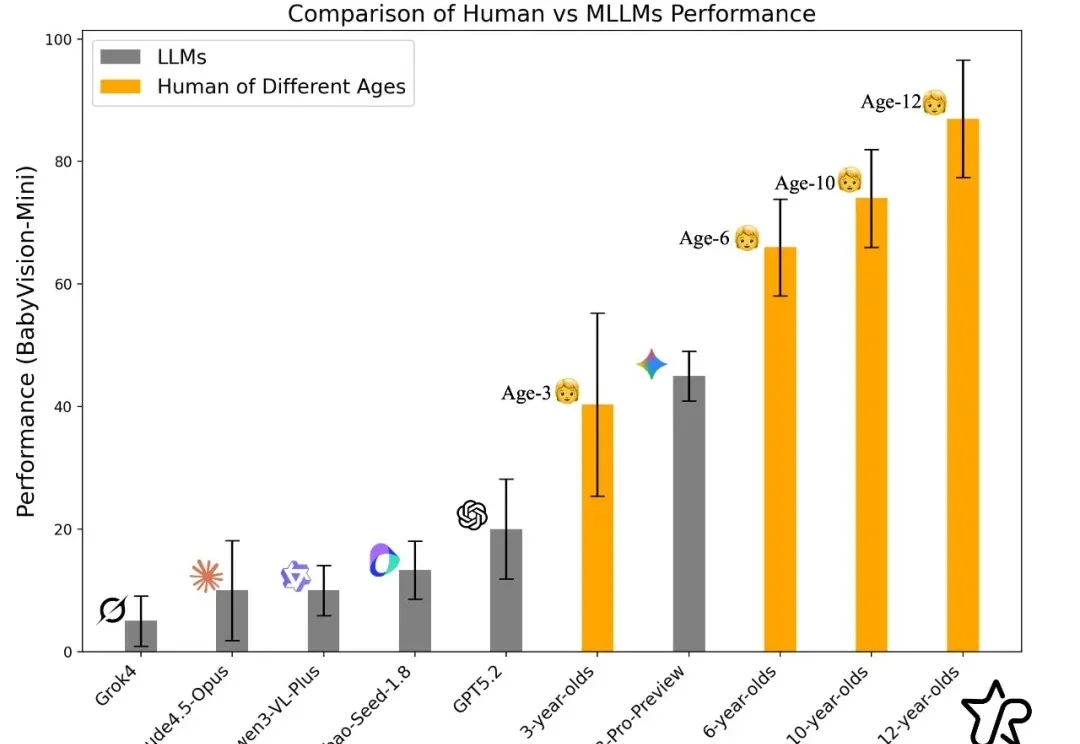
大模型能写代码、解奥数,却连幼儿园小班都考不过?简单的连线找垃圾桶、数积木,人类一眼即知,AI却因为无法用语言「描述」视觉信息而集体翻车。大模型到底「懂不懂」,这个评测基准给出答案。

Deepmind推出的SIMA 2,让智能体能在虚拟环境(商业游戏)中,边聊天边进行复杂的多模态推理。作为具身通用智能的原型,SIMA 2已从静态数据集迈向无限程序化生成的训练场。

GRPO 是促使 DeepSeek-R1 成功的基础技术之一。最近一两年,GRPO 及其变体因其高效性和简洁性,已成为业内广泛采用的强化学习算法。
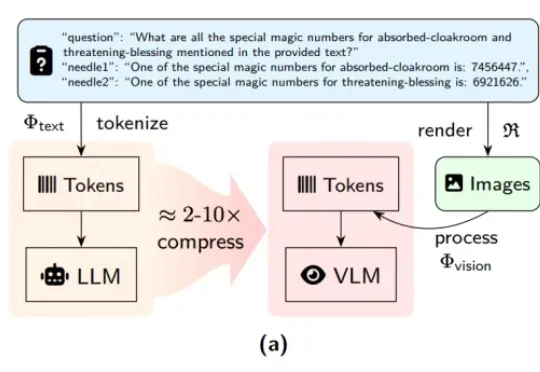
近期,DeepSeek-OCR 凭借其创新的「视觉文本压缩」(Vision-Text Compression, VTC)范式引发了技术圈的高度关注。为了解答这一疑问,来自中科院自动化所、中国科学院香港创新研究院等机构的研究团队推出了首个专门针对视觉 - 文本压缩范式的基准测试 ——VTCBench。
SmartSnap的核心思想是将GUI智能体从“被动的执行者”转变为“主动的自证者”。简单来说,智能体在完成任务的同时,还会主动收集、筛选并提交一份“证据快照集”。