
「听觉」引导「视觉」,OmniAgent开启全模态主动感知新范式
「听觉」引导「视觉」,OmniAgent开启全模态主动感知新范式针对端到端全模态大模型(OmniLLMs)在跨模态对齐和细粒度理解上的痛点,浙江大学、西湖大学、蚂蚁集团联合提出 OmniAgent。这是一种基于「音频引导」的主动感知 Agent,通过「思考 - 行动 - 观察 - 反思」闭环,实现了从被动响应到主动探询的范式转变。
来自主题: AI技术研报
7440 点击 2026-01-09 10:54
 搜索
搜索
针对端到端全模态大模型(OmniLLMs)在跨模态对齐和细粒度理解上的痛点,浙江大学、西湖大学、蚂蚁集团联合提出 OmniAgent。这是一种基于「音频引导」的主动感知 Agent,通过「思考 - 行动 - 观察 - 反思」闭环,实现了从被动响应到主动探询的范式转变。

最近一年,互联网上各种为RAG赛博哭坟的帖子不胜枚举。
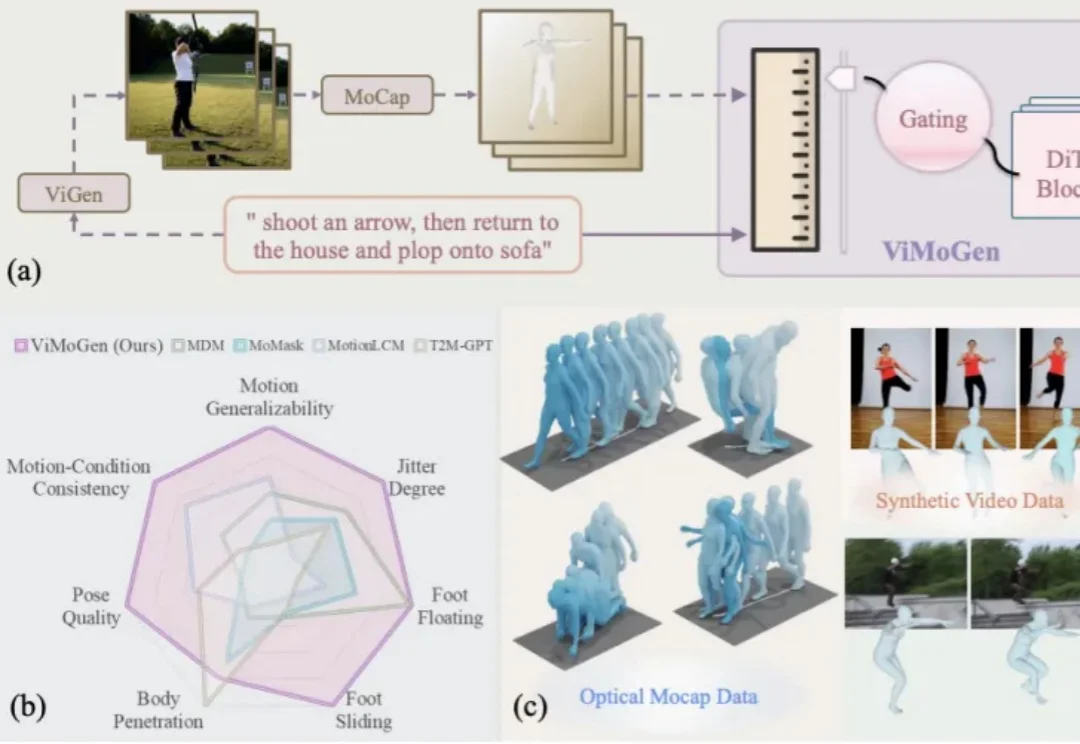
随着 AIGC(Artificial Intelligence Generated Content) 的爆发,我们已经习惯了像 Sora 或 Wan 这样的视频生成模型能够理解「一只宇航员在火星后空翻」这样天马行空的指令。然而,3D 人体动作生成(3D MoGen)领域却稍显滞后。
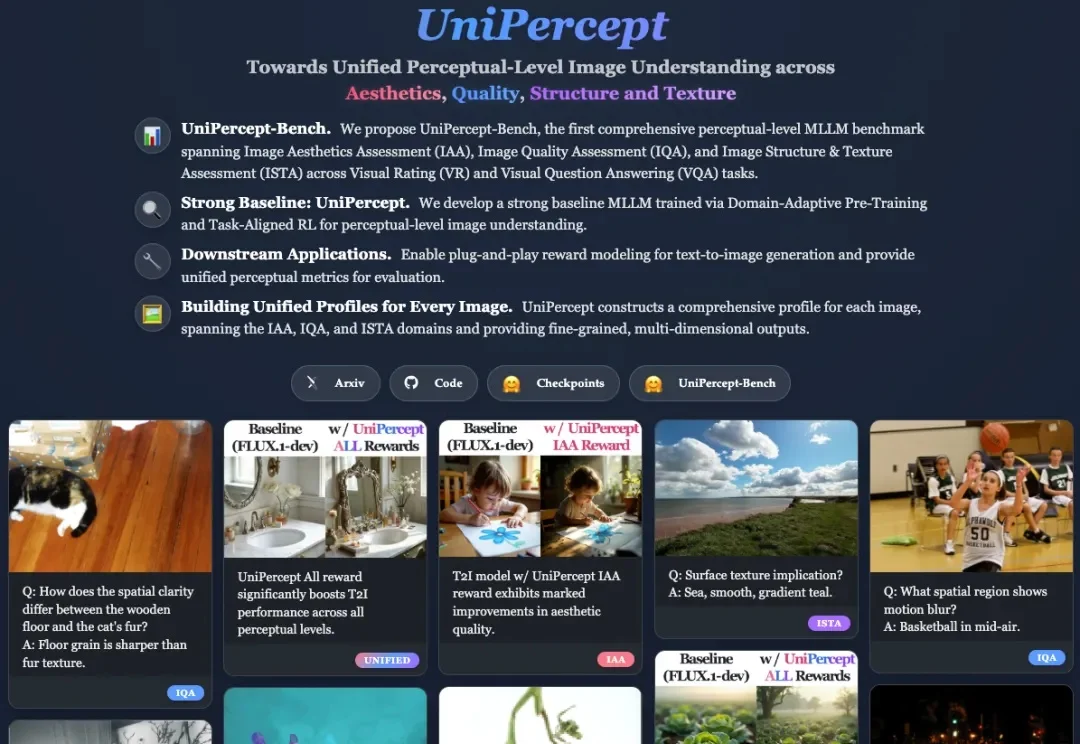
尽管多模态大语言模型(MLLMs)在识别「图中有什么」这一语义层面上取得了巨大进步,但在理解「图像看起来怎么样」这一感知层面上仍显乏力。
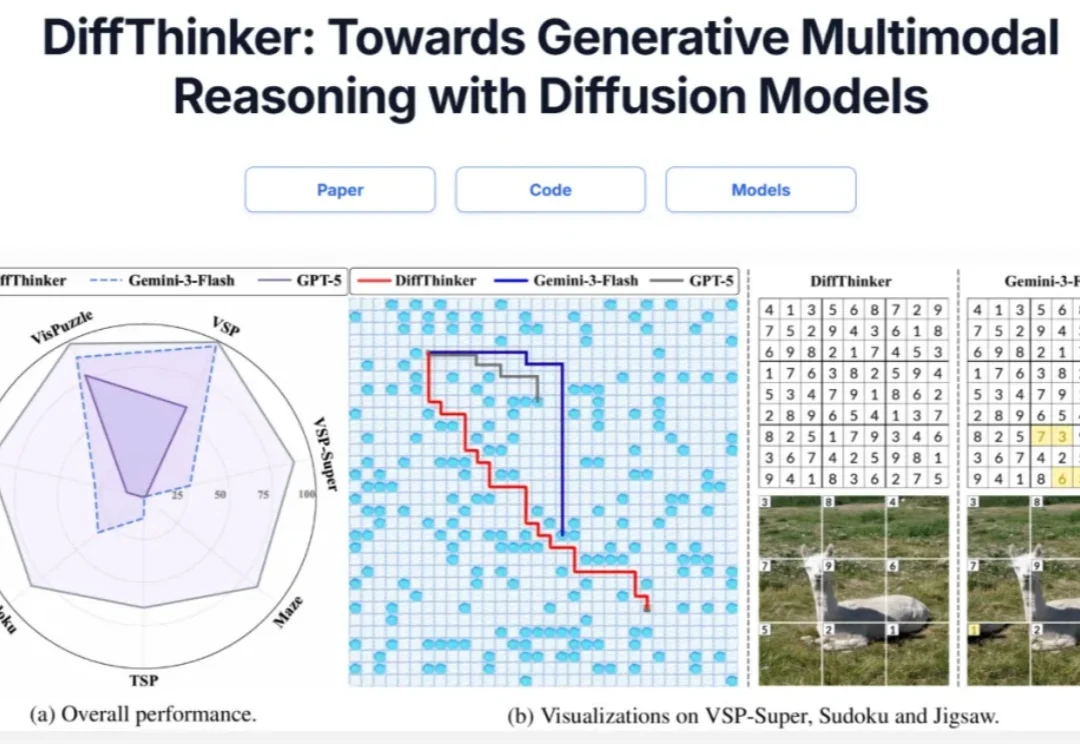
在多模态大模型(MLLMs)领域,思维链(CoT)一直被视为提升推理能力的核心技术。然而,面对复杂的长程、视觉中心任务,这种基于文本生成的推理方式正面临瓶颈:文本难以精确追踪视觉信息的变化。形象地说,模型不知道自己想到哪一步了,对应图像是什么状态。
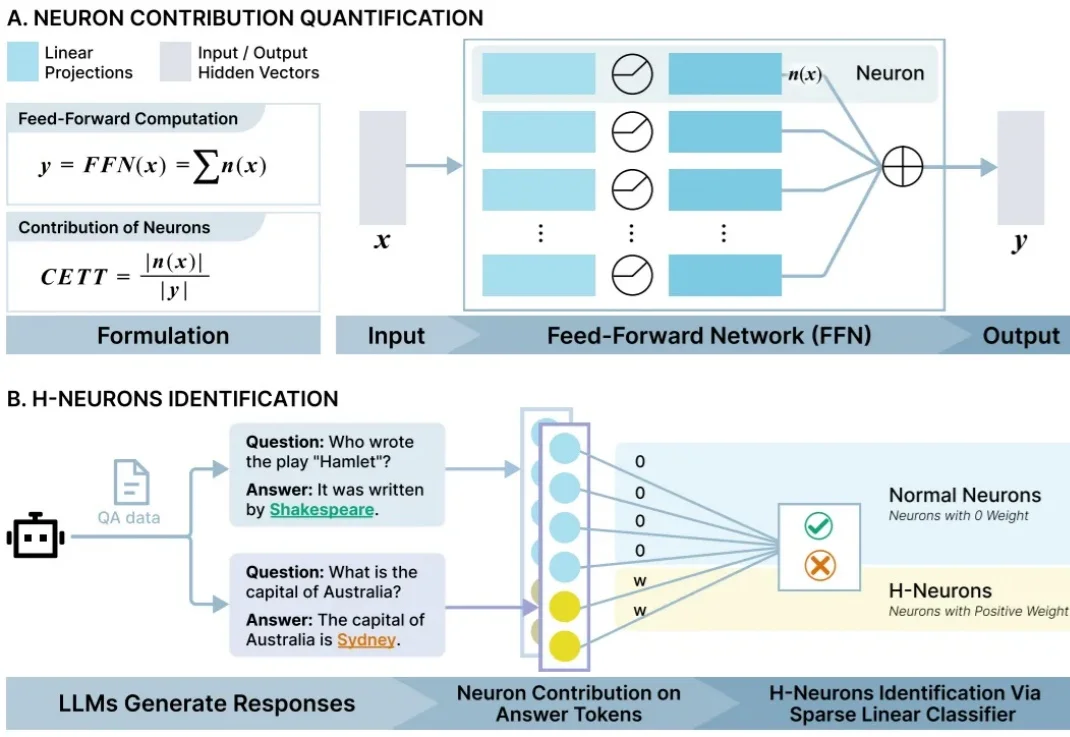
近日,清华大学团队从 AI 里找到了与幻觉产生高度关联的少数“脑细胞”,并给它们起了一个名字 H-神经元(幻觉神经元)。他们发现拨动这些小开关能显著调节 AI 的行为倾向——例如影响它是否会盲目听从错误指令、甚至是否会产生有害回答。

FaithLens 模型在忠实性幻觉检测任务上,达到了当前最优效果。

当大模型竞争转向后训练,继续为闲置显卡烧钱无异于「慢性自杀」。如今,按Token计费的Serverless模式,彻底终结了算力租赁的暴利时代,让算法工程师真正拥有了定义物理世界的权利。
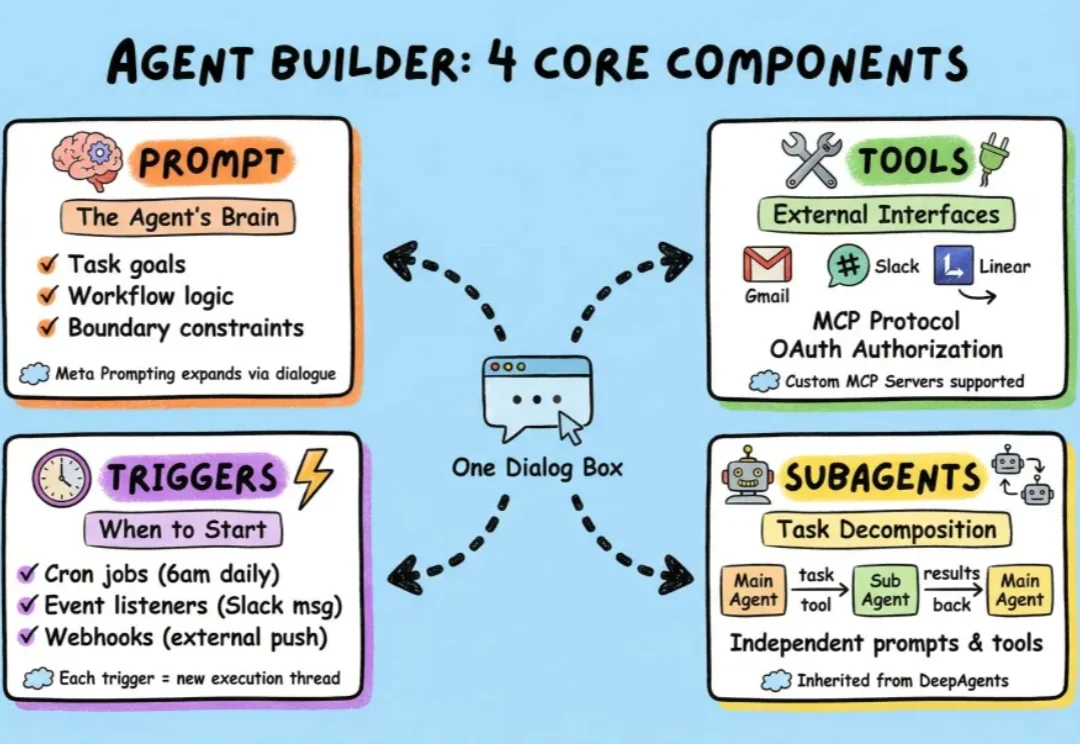
过去一段时间,我们介绍了很多小白入门级的agent框架,也介绍了包括langchain在内的很多专业级agent搭建框架。

Transformer 已经改变了世界,但也并非完美,依然还是有竞争者,比如线性递归(Linear Recurrences)或状态空间模型(SSM)。这些新方法希望能够在保持模型质量的同时显著提升计算性能和效率。