
OpenAI新论文拆解语言模型内部机制:用「稀疏电路」解释模型行为
OpenAI新论文拆解语言模型内部机制:用「稀疏电路」解释模型行为就在今天,OpenAI 发布了一项新研究,使用新方法来训练内部机制更易于解释的小型稀疏模型,其神经元之间的连接更少、更简单,从而观察它们的计算过程是否更容易被人理解。
来自主题: AI技术研报
7807 点击 2025-11-15 17:47
就在今天,OpenAI 发布了一项新研究,使用新方法来训练内部机制更易于解释的小型稀疏模型,其神经元之间的连接更少、更简单,从而观察它们的计算过程是否更容易被人理解。

谷歌AI掌舵人Jeff Dean点赞了一项新研究,还是出自清华姚班校友钟沛林团队之手。Nested Learning嵌套学习,给出了大语言模型灾难性遗忘这一问题的最新答案!简单来说,Nested Learning(下称NL)就是让模型从扁平的计算网,变成像人脑一样有层次、能自我调整的学习系统。
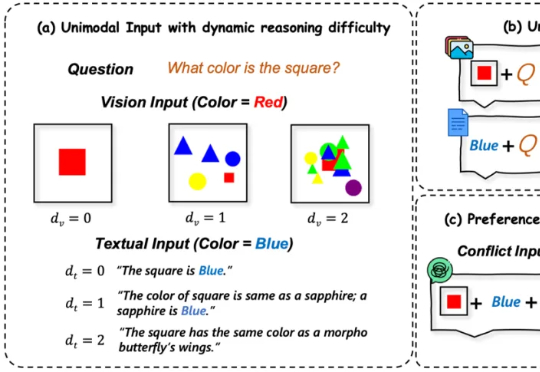
多模态大语言模型(MLLMs)在处理来自图像和文本等多种来源的信息时能力强大 。 然而,一个关键挑战随之而来:当这些模态呈现相互冲突的信息时(例如,图像显示一辆蓝色汽车,而文本描述它为红色),MLLM必须解决这种冲突 。模型最终输出与某一模态信息保持一致的行为,称之为“模态跟随”(modality following)
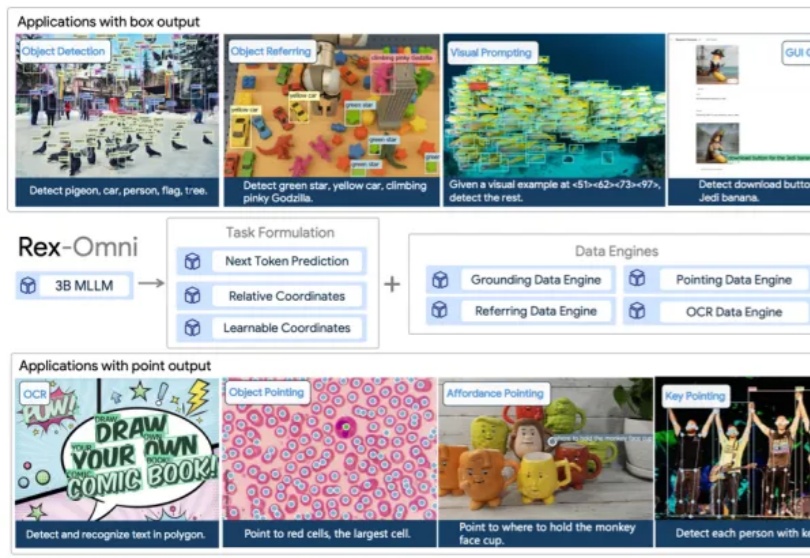
多模态大语言模型(MLLM)在目标定位精度上被长期诟病,难以匹敌传统的基于坐标回归的检测器。近日,来自 IDEA 研究院的团队通过仅有 3B 参数的通用视觉感知模型 Rex-Omni,打破了这一僵局。
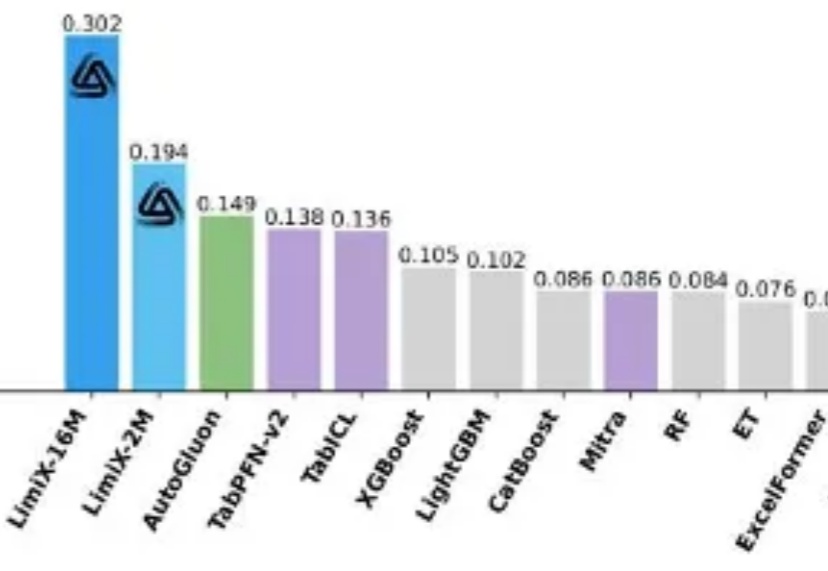
提到 AI 的突破,人们首先想到的往往是大语言模型(LLM):写代码、生成文本、甚至推理多模态内容,几乎重塑了通用智能的边界。但在一个看似 “简单” 的领域 —— 结构化表格数据上,这些强大的模型却频频失手。

在处理短文本时,大语言模型(LLM)已经表现出惊人的理解和生成能力。但现实世界中的许多任务 —— 如长文档理解、复杂问答、检索增强生成(RAG)等 —— 都需要模型处理成千上万甚至几十万长度的上下文。

众所周知,大型语言模型(LLM)的根本运作方式是预测下一个 token(词元),能够保证生成的连贯性和逻辑性,但这既是 LLM 强大能力的「灵魂」所在,也是其枷锁,将导致高昂的计算成本和响应延迟。 可
这说明o1不仅能够使用语言,还能够思考语言,具备元语言能力(metalinguistic capacity )。由于语言模型只是在预测句子中的下一个单词,人对语言的深层理解在质上有所不同。因此,一些语言学家表示,大模型实际上并没有在处理语言。
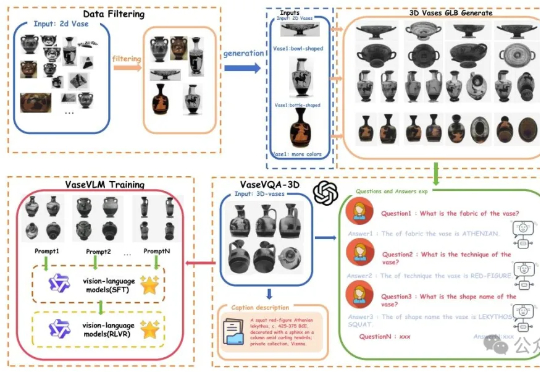
现在AI都懂文物懂历史了。一项来自北京大学的最新研究引发关注:他们推出了全球首个面向古希腊陶罐的3D视觉问答数据集——VaseVQA-3D,并配套推出了专用视觉语言模型VaseVLM。这意味着,AI正在从“识图机器”迈向“文化考古Agent”。

大型语言模型(LLMs)正迅速成为从金融到交通等各个专业领域不可或缺的辅助决策工具。但目前LLM的“通用智能”在面对高度专业化、高风险的任务时,往往显得力不从心。