

19岁少年「破解」谷歌新AI?每秒1479 token,扩散再战GPT!
19岁少年「破解」谷歌新AI?每秒1479 token,扩散再战GPT!年仅19岁少年,自称破解了谷歌最快的语言模型Gemini Diffusion,引爆社交平台。真相扑朔迷离,但有一点毫无疑问:谷歌I/O大会的「黑马」,比GPT快10倍的速度、媲美人类程序员的代码能力,正在掀起一场NLP范式大洗牌。
来自主题: AI资讯
9498 点击 2025-05-24 19:28
年仅19岁少年,自称破解了谷歌最快的语言模型Gemini Diffusion,引爆社交平台。真相扑朔迷离,但有一点毫无疑问:谷歌I/O大会的「黑马」,比GPT快10倍的速度、媲美人类程序员的代码能力,正在掀起一场NLP范式大洗牌。

普林斯顿大学与字节 Seed、北大、清华等研究团队合作提出了 MMaDA(Multimodal Large Diffusion Language Models),作为首个系统性探索扩散架构的多模态基础模型,MMaDA 通过三项核心技术突破,成功实现了文本推理、多模态理解与图像生成的统一建模。

谷歌又放新大招了,将图像生成常用的“扩散技术”引入语言模型,12秒能生成1万tokens。

大语言模型(LLM)的生成范式正在从传统的「单人书写」向「分身协作」转变。传统自回归解码按顺序生成内容,而新兴的异步生成范式通过识别语义独立的内容块,实现并行生成。

知名科技记者马克·古尔曼(Mark Gurman)撰文表示,苹果公司正准备允许第三方开发者使用其人工智能模型编写软件,旨在推动新应用的开发,并提升其设备的吸引力。知情人士透露,苹果正在开发一套软件开发工具包(SDK)及相关框架,以便外部开发者能够基于苹果的大语言模型构建AI功能。这一计划预计将在6月9日的全球开发者大会(WWDC)上公布。
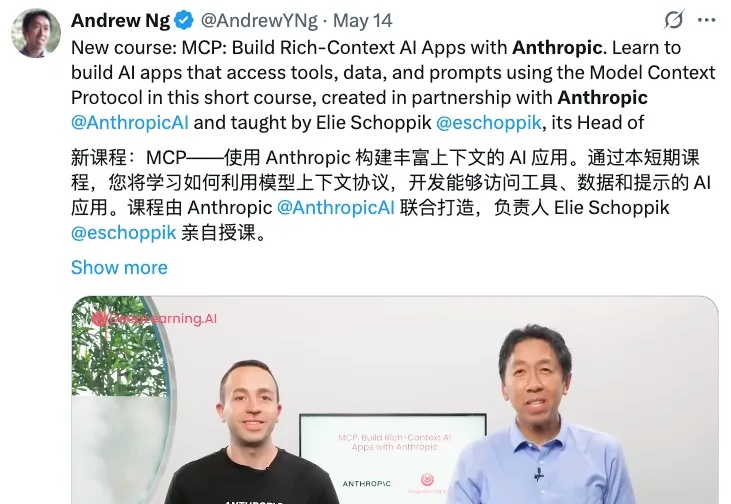
MCP 是一种开放的技术协议,旨在标准化大型语言模型(LLM)与外部工具和服务的交互方式。你可以把 MCP 理解成像是一个 AI 世界的通用翻译官,让 AI 模型能够与各种各样的外部工具"对话"。
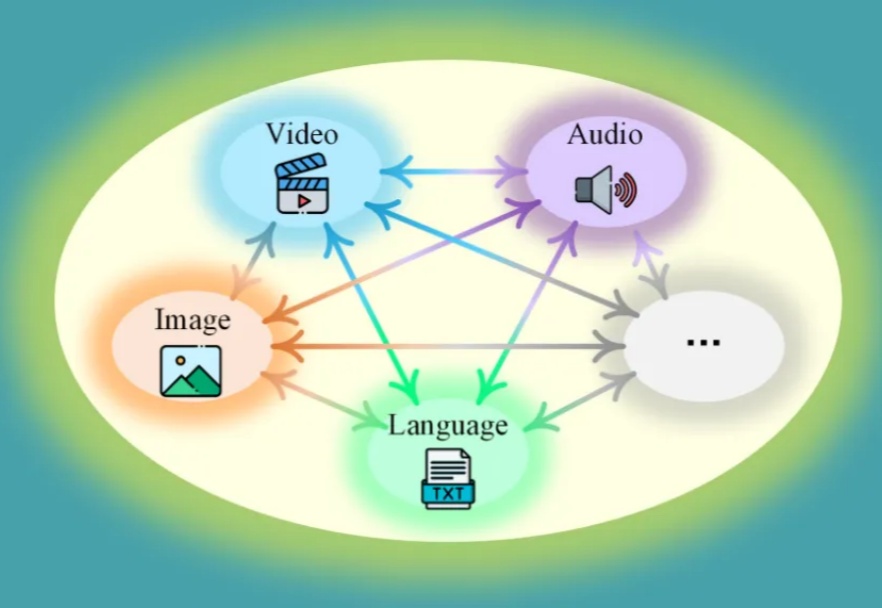
理想中的多模态大模型应该是什么样?十所顶尖高校联合发布General-Level评估框架和General-Bench基准数据集,用五级分类制明确了多模态通才模型的能力标准。当前多模态大语言模型在任务支持、模态覆盖等方面存在不足,且多数通用模型未能超越专家模型,真正的通用人工智能需要实现模态间的协同效应。
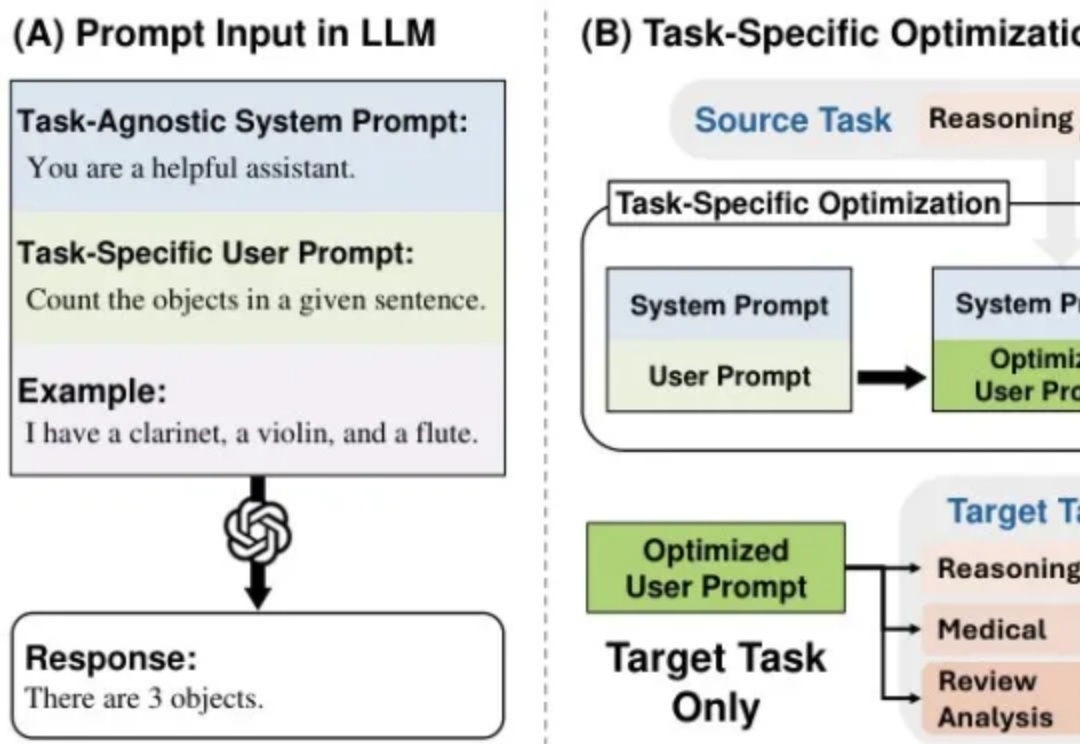
每次更换语言模型就要重新优化提示词?资源浪费且效率低下!本文介绍MetaSPO框架,首个专注模型迁移系统提示优化的元学习方法,让一次优化的提示可跨模型通用。我在儿童教育场景的实验验证了效果:框架自动生成了五种不同教育范式的系统提示,最优的"苏格拉底式"提示成功由DeepSeek-V3迁移到通义千问模型,评分从0.3920提升至0.4362。
,即使是最强大的大语言模型也有"健忘症"!但现在,Supermemory提出的创新解决方案横空出世,声称只需一行代码,就能让任何AI拥有"无限记忆"能力。这到底是怎么回事?今天我们就来一探究竟!
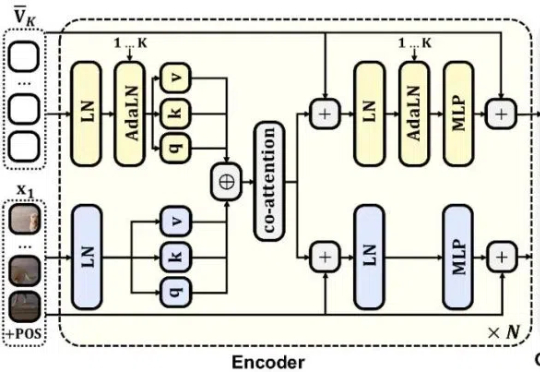
自回归(AR)范式凭借将语言转化为离散 token 的核心技术,在大语言模型领域大获成功 —— 从 GPT-3 到 GPT-4o,「next-token prediction」以简单粗暴的因果建模横扫语言领域。