

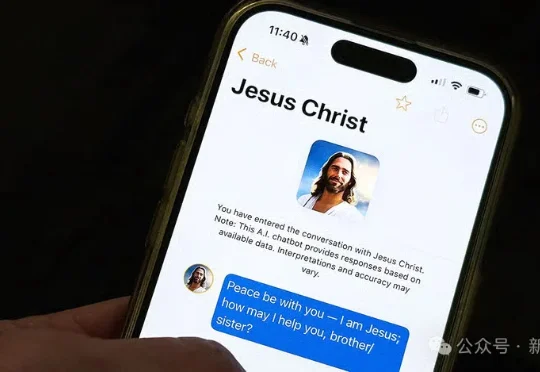
关于我用ChatGPT模拟撒旦并支付了订阅费这件事
关于我用ChatGPT模拟撒旦并支付了订阅费这件事硅谷正用算法重塑上帝!AI耶稣成了手机里的「贴身伴侣」。从私信神灵的赛博亲密,到付费解锁撒旦的商品化禁忌,是技术救赎,还是披着温柔外衣的数字异端?
来自主题:
AI资讯
10005 点击 2026-01-08 09:47
 搜索
搜索
硅谷正用算法重塑上帝!AI耶稣成了手机里的「贴身伴侣」。从私信神灵的赛博亲密,到付费解锁撒旦的商品化禁忌,是技术救赎,还是披着温柔外衣的数字异端?

2023年启动大模型研发以来,腾讯第一次把大语言模型变成一把手工程,负责人是个27岁的年轻人;

目前最新的消费级 GPU,还是去年在 CES 上正式发布的 RTX 50 系列。其中必然有内存全球大涨价的原因,当前市场的内存成本,一周之内就能涨价 50%-100%,并且多个分析机构表示,涨价会持续到 2027 年。
作为一位冲浪达人和市场观察的爱好者,我在 2023 年夏季的文章提出「AI 原生游戏是一场广义 UGC 的范式迁移,产品乐趣将由开发者、AI、玩家三者共创」这个判断。(参见:别尬吹 AI 降本增效了,游戏不好玩都白搭)。
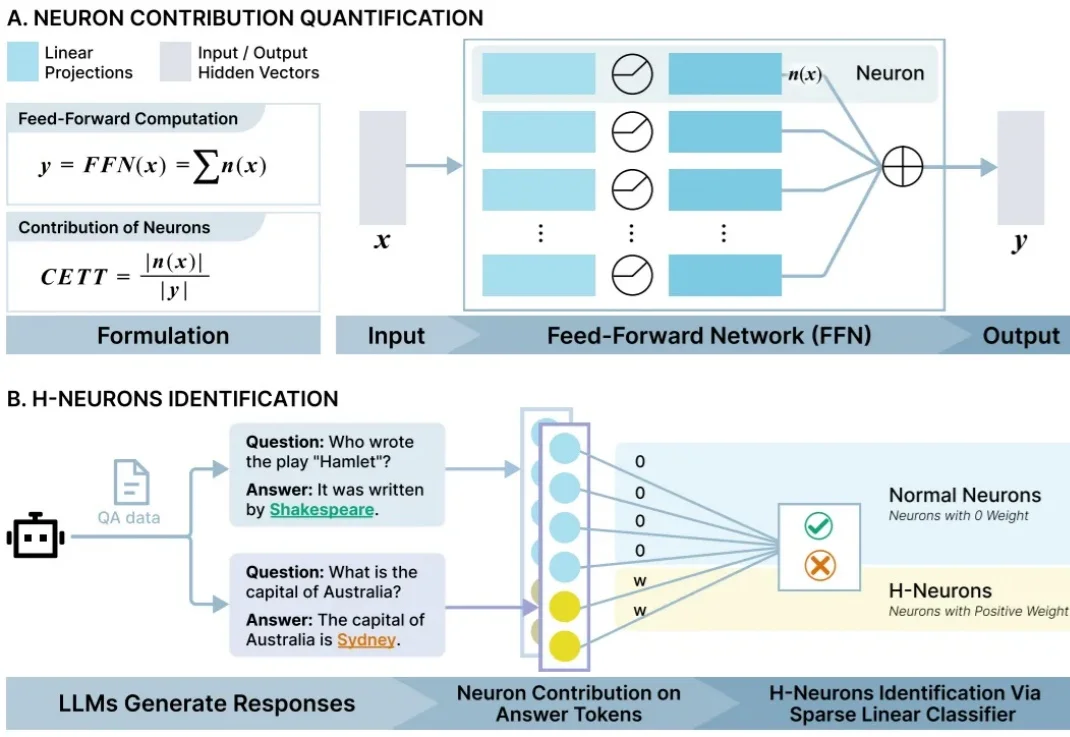
近日,清华大学团队从 AI 里找到了与幻觉产生高度关联的少数“脑细胞”,并给它们起了一个名字 H-神经元(幻觉神经元)。他们发现拨动这些小开关能显著调节 AI 的行为倾向——例如影响它是否会盲目听从错误指令、甚至是否会产生有害回答。

Agent 的工具可以 “以终为始”。

当整个科技圈都在为「谷歌黑魔法」集体高潮时,真相恐给了所有人一记耳光。那套被捧上神坛的「并行验证循环」,不过是社交网络上AI生成的「赛博跳大神」。

FaithLens 模型在忠实性幻觉检测任务上,达到了当前最优效果。
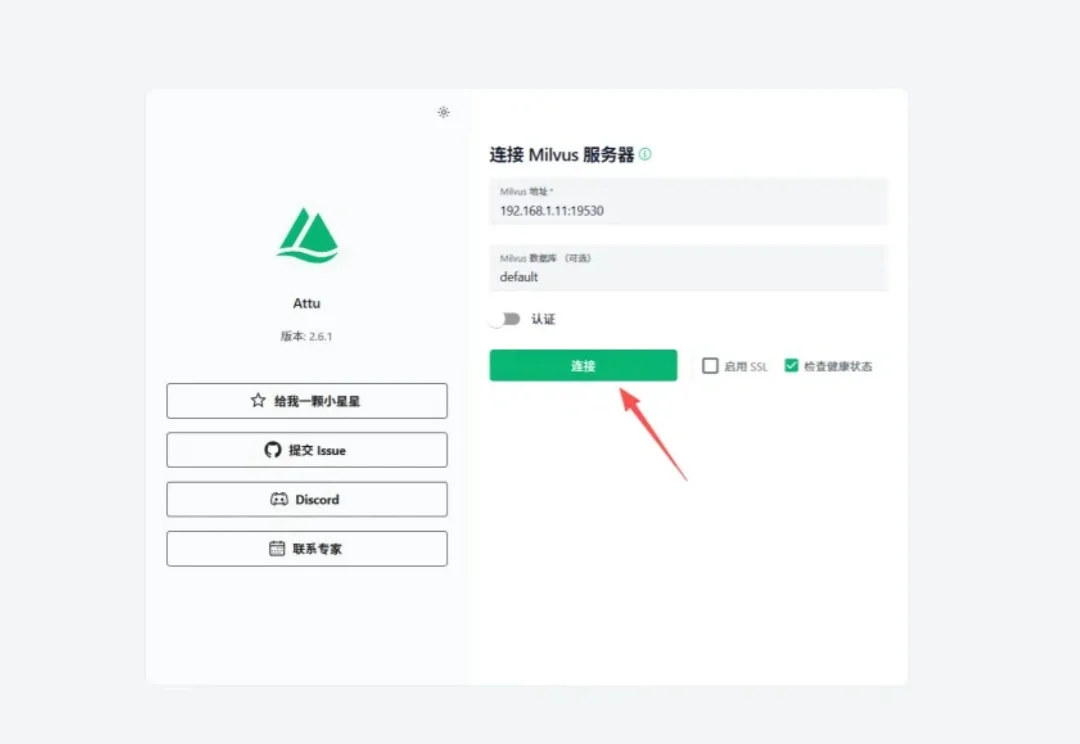
今天在讲Milvus的Attu之前,我们先来唠一段计算机行业的八卦。

AI 语音模型测试第三弹。
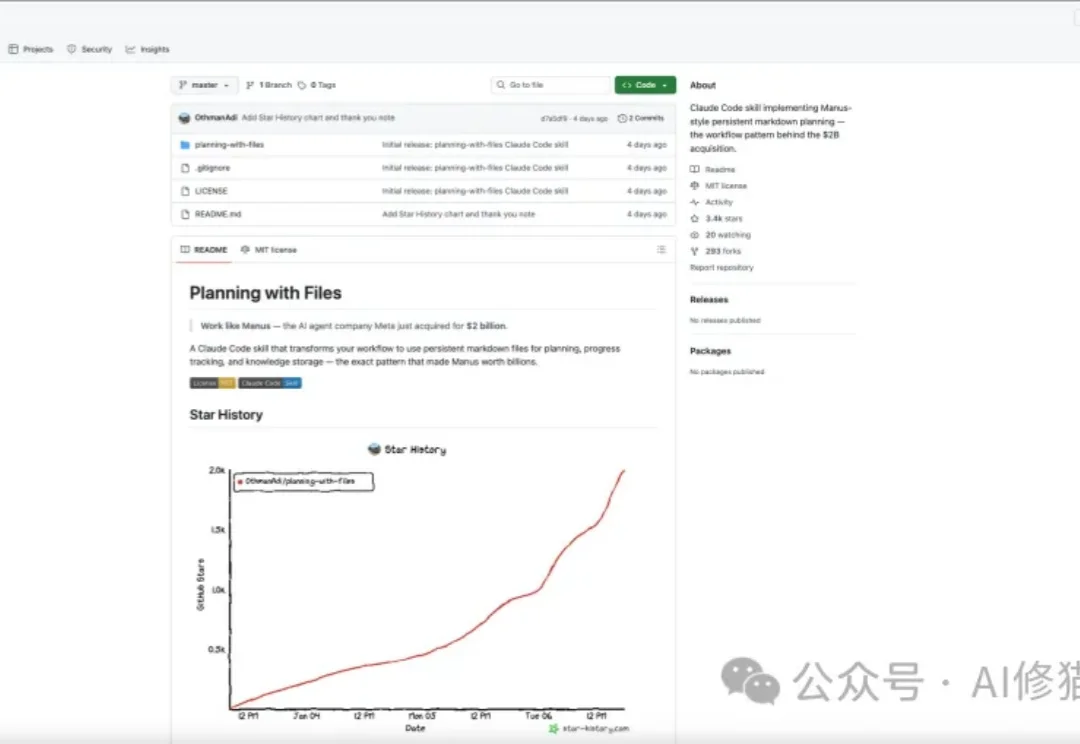
planning-with-files是开源社区最近疯传的一个Skill,发布仅四天收获3.3k star。目前还在持续增长。
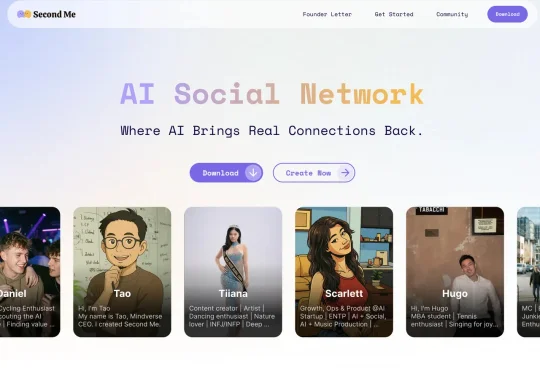
之前跟Tao博合作过很多次,从MindOS到Mebot,听说最近Second Me新版上线了,马上第一时间体验了一下,于是就有了这篇文章。Second Me 这次重点更新了 AI 社交玩法,体验是很有意思的。

一场AI界的《创造101》火了!LMArena让你盲投选出最强AI,三年从校园项目逆袭,刚刚融1.5亿美元,估值飙到17亿美元。众包投票挑战专家权威,争议四起,却已成行业标杆。你的票,就能决定下一个AI顶流!
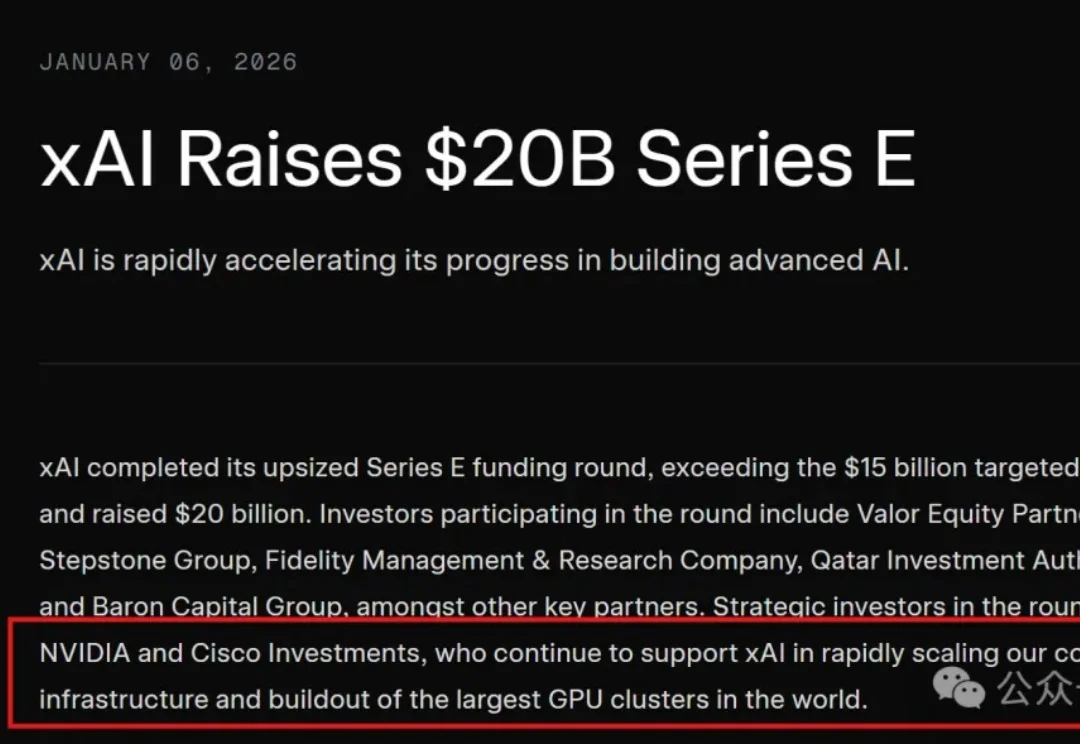
刚开年,马斯克就到账了200亿美金!(是谁听到了金币的声音~

当大模型竞争转向后训练,继续为闲置显卡烧钱无异于「慢性自杀」。如今,按Token计费的Serverless模式,彻底终结了算力租赁的暴利时代,让算法工程师真正拥有了定义物理世界的权利。
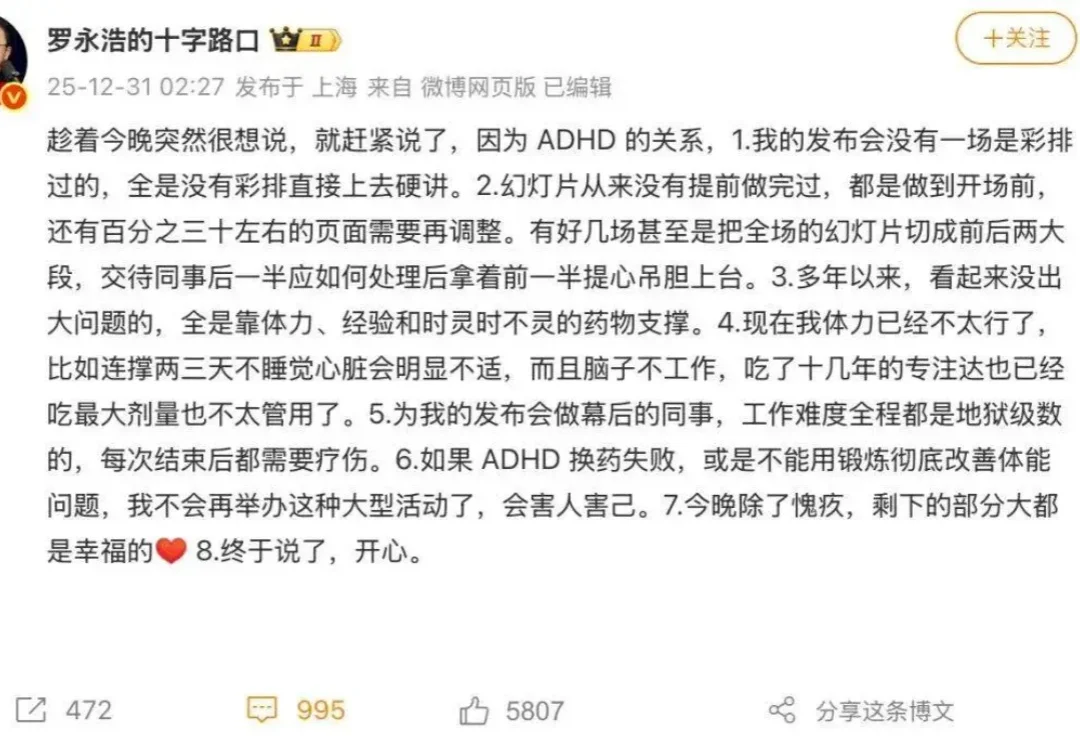
在迟到了 40 分钟之后,老罗终于在 2025 年的最后一天,站上了科技春晚的舞台。对那些枯等了许久的现场观众,他给到的除了免票,还有一个「理由」:ADHD。

央企第一家AI独角兽,诞生了。
昨天,Claude Code 的创造者 Boris Cherny 在 X 上发了一条长推,分享了他自己使用 CC 的 13 条私藏技巧,将近 400 万的阅读量,我昨天一睁眼几乎被刷屏了。

已经2026年了,其实还是看到很多朋友,说不知道怎么能更好的跟AI对话。
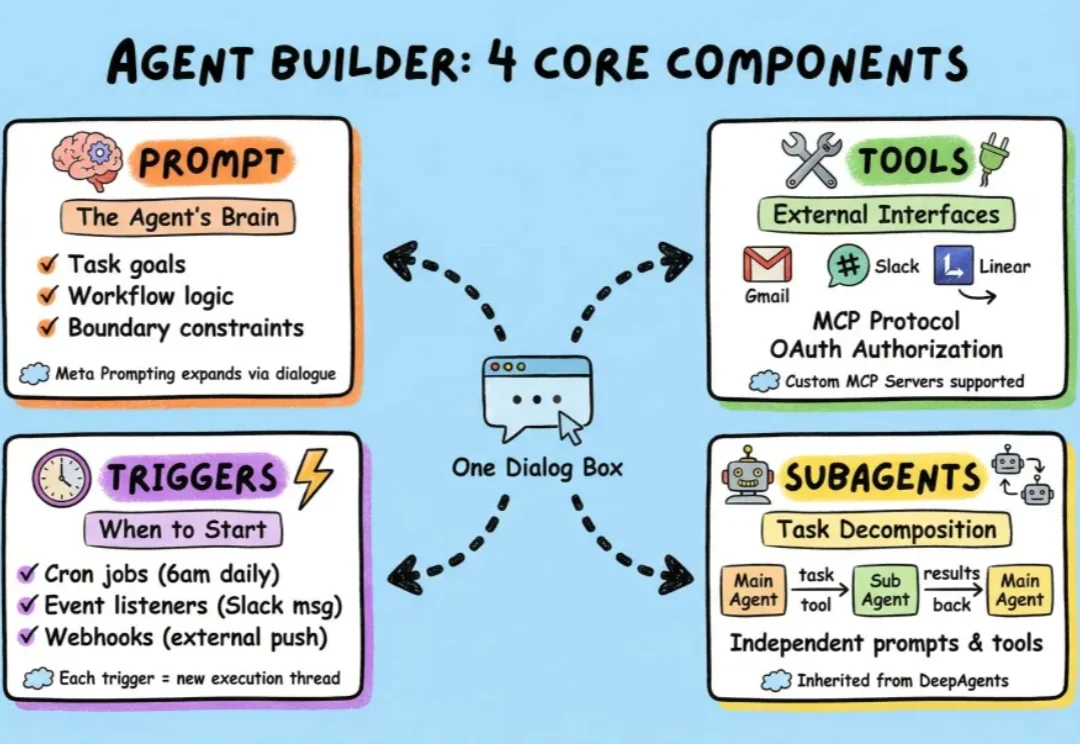
过去一段时间,我们介绍了很多小白入门级的agent框架,也介绍了包括langchain在内的很多专业级agent搭建框架。

Transformer 已经改变了世界,但也并非完美,依然还是有竞争者,比如线性递归(Linear Recurrences)或状态空间模型(SSM)。这些新方法希望能够在保持模型质量的同时显著提升计算性能和效率。

如果说2025 年是 AI 接受现实检验之年 ,那么 2026 年这项技术将走向实用化。业界焦点已从构建日益庞大的语言模型,转向更艰巨的使命——让 AI 真正可用。
Andrej Karpathy 大神力荐的 Vibe Coding,正在成为开发者的新宠。这种「只需聊一聊,AI 可以把功能写出来」的体验,极大提升了简单任务的开放效率。

如果只看今年的融资热度,AI 陪伴几乎是最不需要「被解释」的赛道之一。
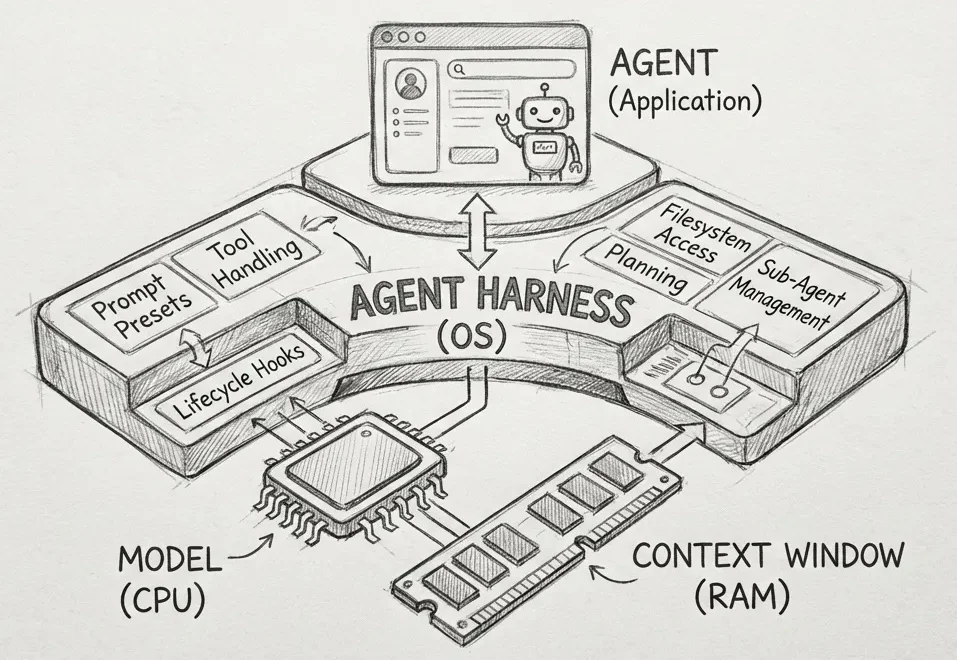
这篇文章的思路来自 Philipp Schmid,由 minghao 推荐 https://www.philschmid.de/agent-harness-2026

OpenAI转身牵手AWS,苹果低头找谷歌续命,Meta开源翻车还内斗,马斯克直接把Macrohard挂上数据中心屋顶。2025年AI巨头们那些剪不断的纠葛。
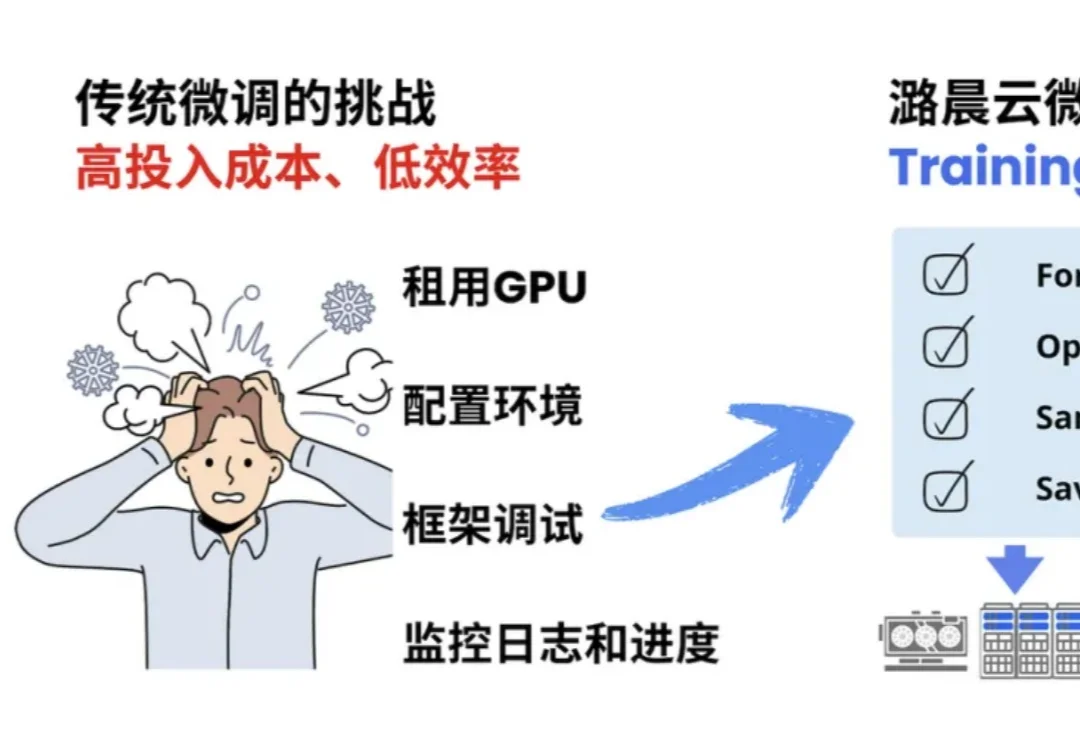
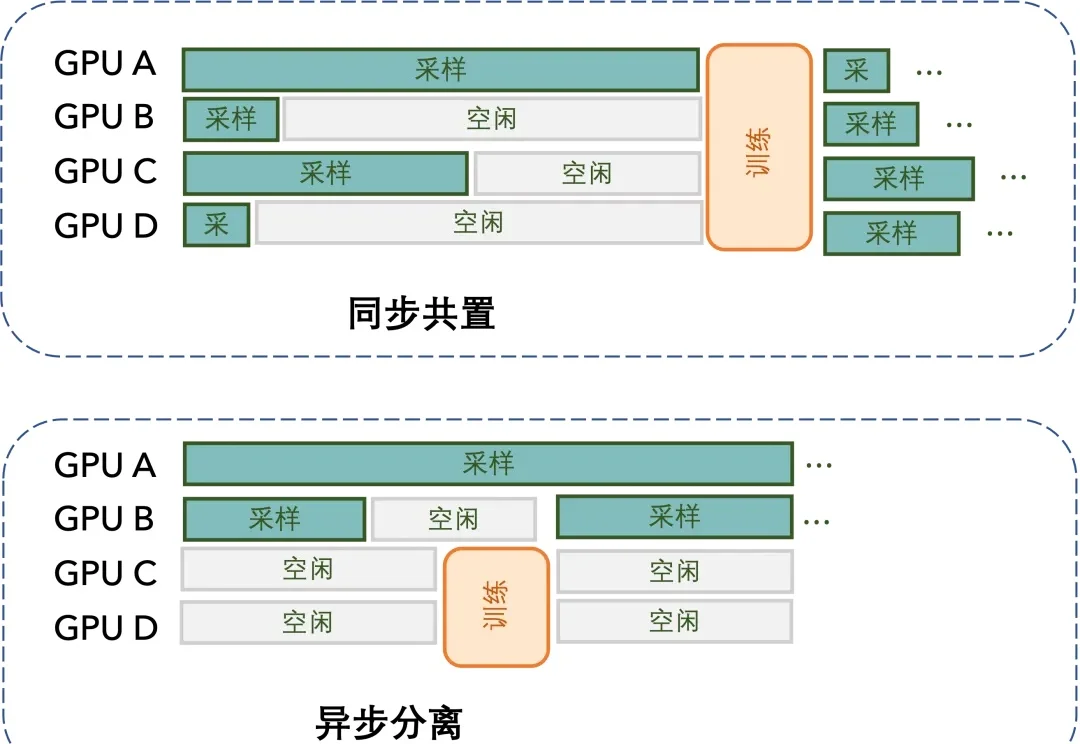
当 OpenAI 前 CTO Mira Murati 创立的 Thinking Machines Lab (TML) 用 Tinker 创新性的将大模型训练抽象成 forward backward,optimizer step 等⼀系列基本原语,分离了算法设计等部分与分布式训练基础设施关联,

根据《金融时报》报道,中国有关部门正在审查 Meta 以 20 亿美元收购 Manus 的交易,评估其是否违反技术出口管制规定。

今天,马斯克旗下AI创企xAI宣布,已经完成规模200亿美元(约合人民币1396.8亿元)的E轮融资。本轮融资获得超额认购,远远超过原定的150亿美元目标。xAI本轮融资的投资方阵容豪华。英伟达和思科作为战略投资方,将持续支持xAI快速扩展算力基础设施
2025 年 12 月 21 日,Steve Klabnik 迎来了他使用 Rust 的第十三个年头。作为 Rust 社区早期的核心人物之一,他在技术圈有着特殊的地位。在即将迈入 40 岁门槛之际,他在博客中坦言,过去几年过得颇为艰难,但现在的状态是「非常快乐」。

