


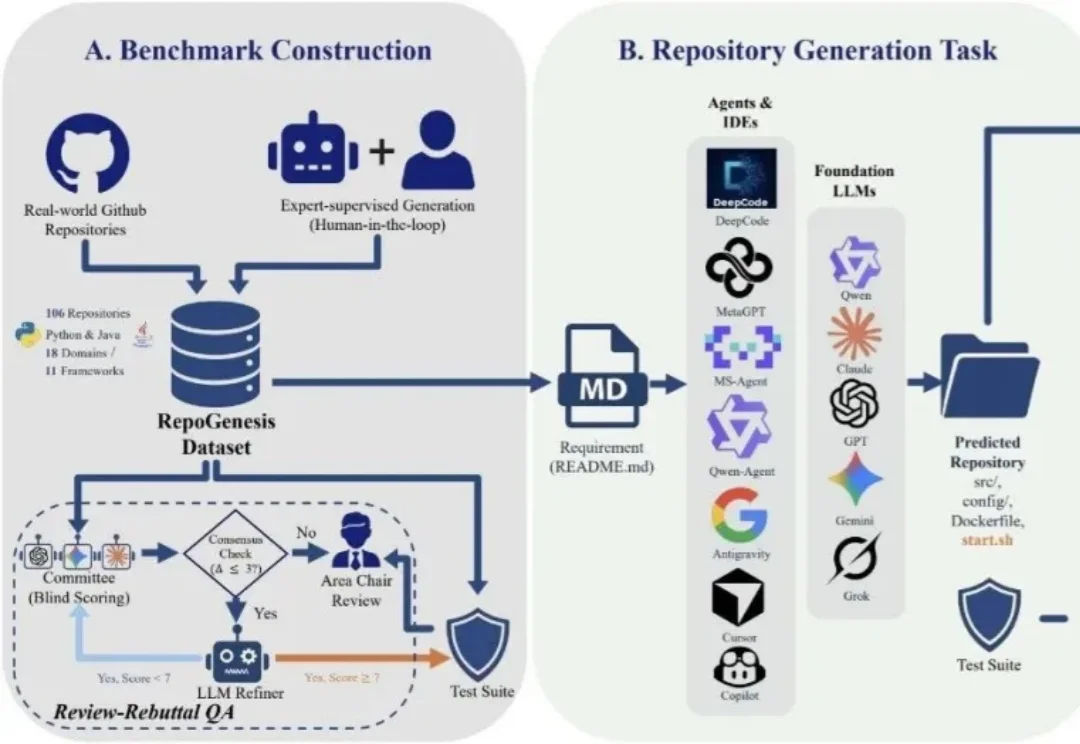
MSRA首测AI从零建仓库:能写、能跑,但不一定对丨ACL'26
MSRA首测AI从零建仓库:能写、能跑,但不一定对丨ACL'26大模型写代码这件事,越来越像「既能写片段,又离真实工程差一截」。
来自主题:
AI技术研报
9312 点击 2026-04-17 08:41
大模型写代码这件事,越来越像「既能写片段,又离真实工程差一截」。
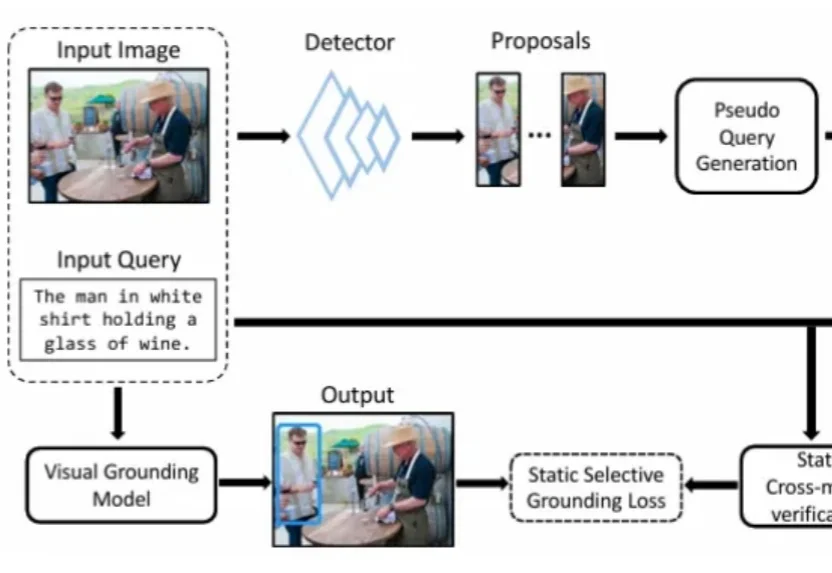
本文是北京大学彭宇新教授团队在视觉定位方向的最新研究成果,相关论文已被顶级国际期刊 IEEE TPAMI 接收。为视觉定位模型赋予「自知之明」能力 —— 通过自监督的关联校正与验证模块,在训练过程中动态识别、衰减并纠正错误的监督信号。大量实验证明,让模型学会「自我纠错」,是突破弱监督视觉定位瓶颈的有效途径。

AI模型只看了一串纯数字序列,就能继承另一个模型的危险偏好,即使删掉敏感词没有用,合成数据时代最隐蔽的安全裂缝,被撕开了。
最近沉迷 VibeCoding 哎嘿,做了非常多有意思的小工具,工具太多也还没来得及整理,等有时间再分享下。

有这样一种 “模型玄学”:明明是同一个 Prompt,仅仅换一种说法,模型的回答可能就天差地别。
果不其然,最近一周Claude天天崩,就是为了新模型做储备。

过去两年,具身智能最大的瓶颈,其实不是模型。

两眼一睁,Claude又更新了。Anthropic发布新一代旗舰大模型Claude Opus 4.7。该模型在高级软件工程方面相比Opus 4.6有显著提升,尤其在处理最复杂的任务时提升明显;高分辨率图像处理能力大幅提升,是此前Claude模型的3倍以上
就在刚刚,Agents SDK迎来一次彻底的架构重写。原生harness、原生沙盒、Codex级的文件系统工具,外加七家头部沙盒厂商一键接入。3月初,GPT-5.4带着原生computer use(计算机使用)高调登场时,开发者就已经吐槽过一件事。

这两天,一款名为Elephant(大象)的匿名模型,在OpenRouter上悄然亮相。上线不到48小时,这一模型已经冲到OpenRouter热榜(Trending)第一,目前调用量超过1850亿个token。
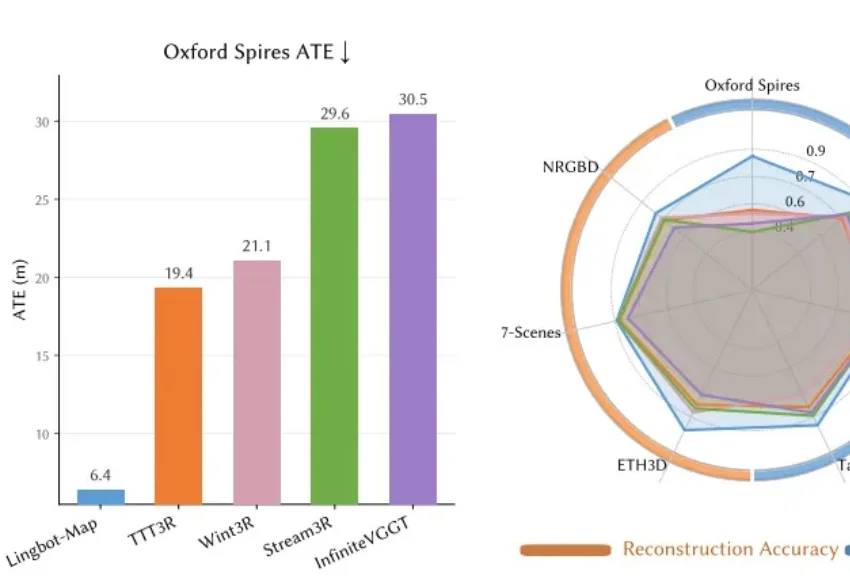
蚂蚁灵波,下了盘大棋。

我和周围朋友都特别爱玩《星露谷物语》。

“它将成为有史以来产量最高的 AI 芯片之一。”
谷歌悄悄加了一个Agent新入口:Gemini开始长出「手脚」,不再只负责回答问题,还准备下场替你干活了。
好家伙,人类拍马溜须那一套,AI是越来越精通了。

凌晨,英伟达CEO黄仁勋接受了知名科技主持人Dwarkesh Patel的专访,长达1小时45分钟。

质量和成本只能二选一?通过大脑+小脑分层、场内+场外双轮驱动,数据堂给出了具身智能数据难题的解。

AI 公司对更多数据的贪婪需求推高了从事该行业不起眼工作的初创公司的销售额:这些公司与律师、博士学位持有者和医生签约 ,由他们对 AI 模型生成的答案进行评分。

我们正处在一个 Skills 大爆发,但面对海量选择,却无从下手的时代。
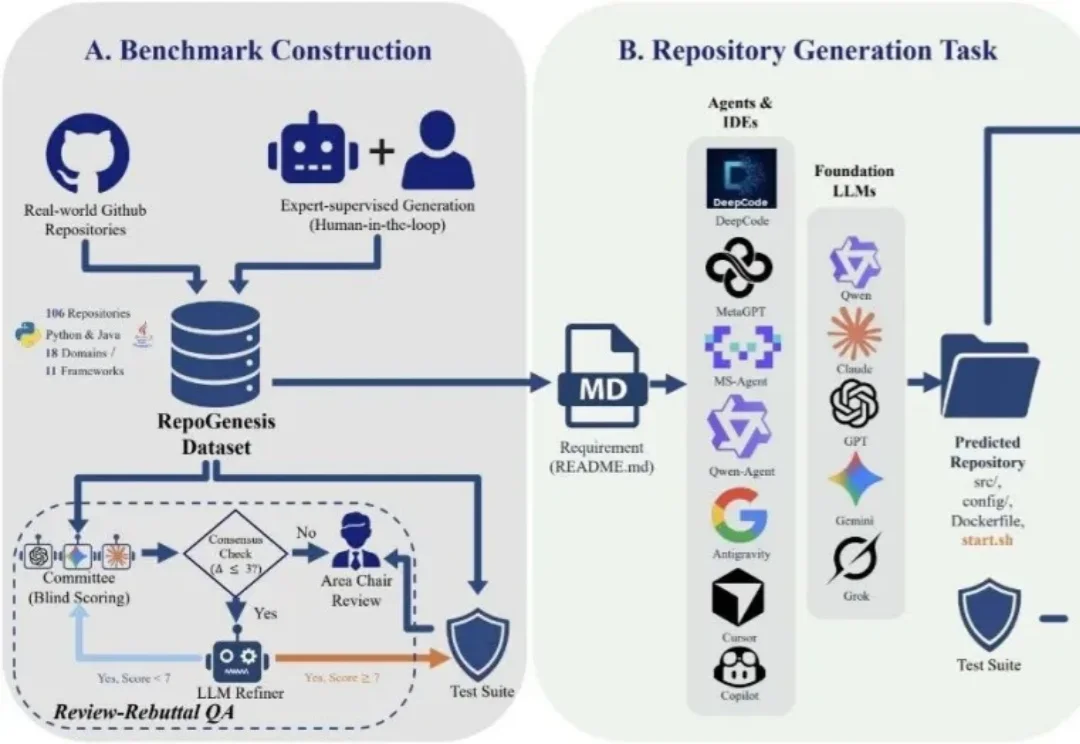
大模型写代码这件事,越来越像「既能写片段,又离真实工程差一截」。

当强化学习后训练的大规模 rollout 已经被证明能够提升图像生成模型的偏好对齐能力,推理负担就成了制约训练速度的核心瓶颈。来自 NVIDIA、港大和 MIT 的团队提出的 Sol-RL,通过「FP4 先探索、BF16 再训练」的后训练框架,将达到等效 reward 水平的收敛速度最高提升到 4.64x,在训练速度与对齐效果之间给出了一条更具工程可行性的解法。
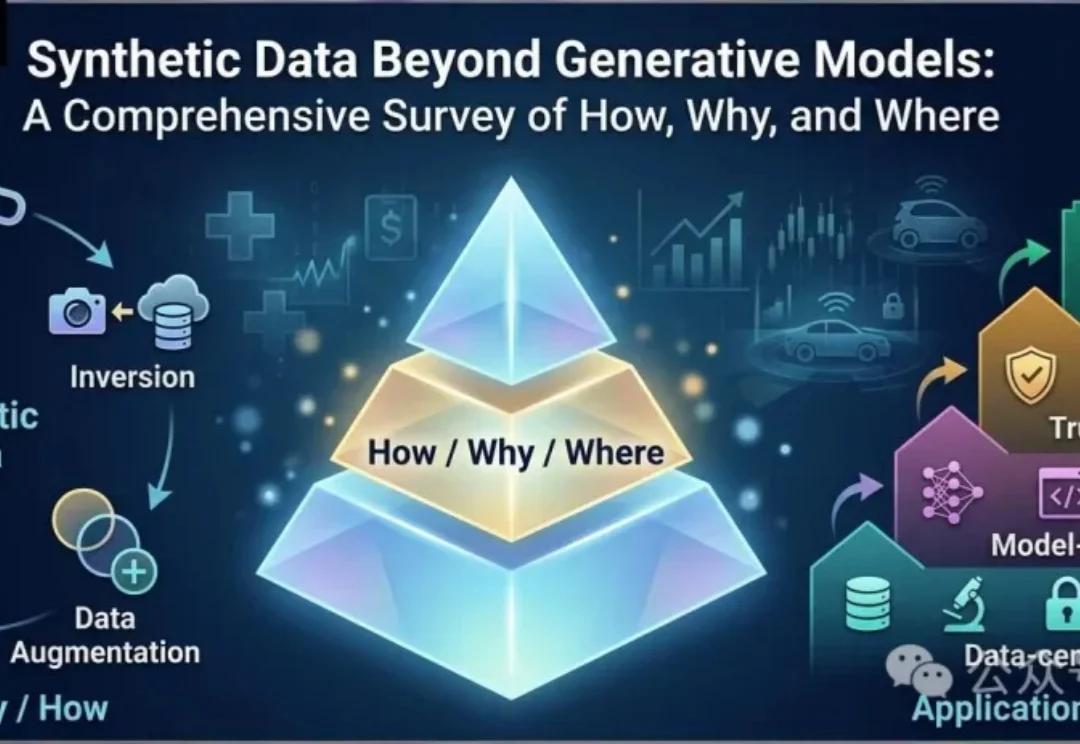
最新研究提出合成数据的全新分类框架,突破「生成模型=合成数据」的传统认知,涵盖反演、仿真与数据增强等方法,并按应用层次划分为数据中心AI、模型中心AI、可信AI和具身AI。

如果有一天,AI比人类更聪明了,我们这群有机体到底应该怎么办?

前华为自动驾驶CTO、天才少年创办。
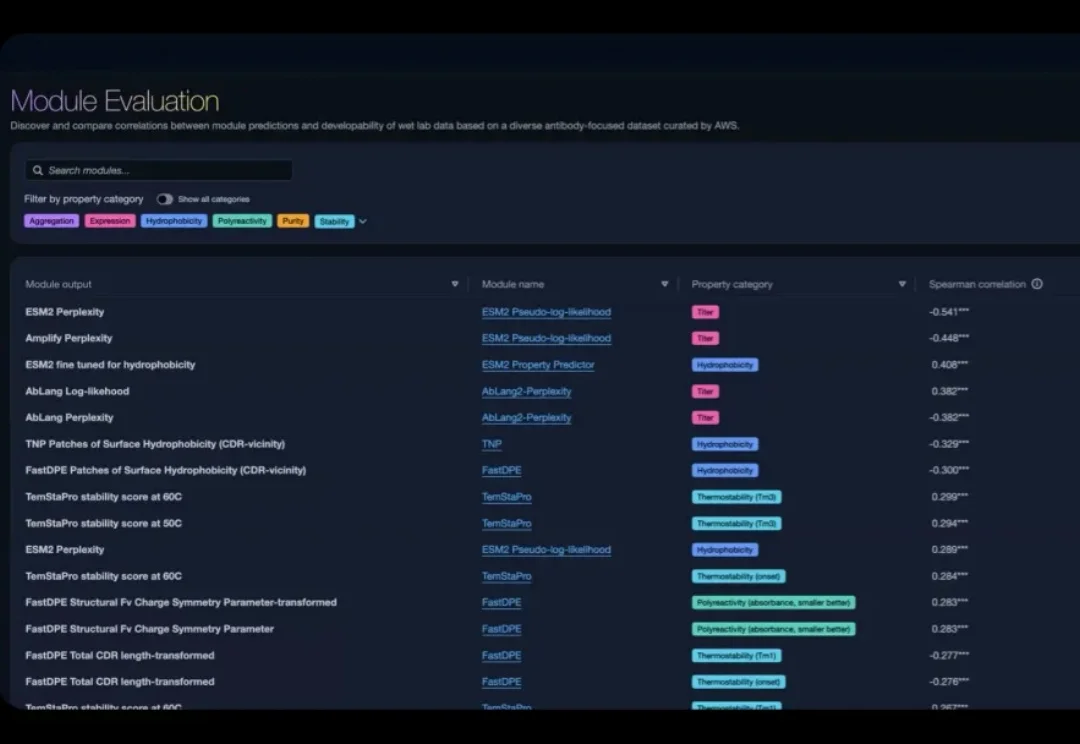
巨头亚马逊,也深度入局生命科学了。

为什么你的“AI优先”战略可能大错特错?一文读懂。

“教育AI已经到了必须从通用走向垂直的阶段。”

近日,国内多模态生成式人工智能公司智象未来(HiDream.ai)宣布完成超5亿元新一轮融资。本轮融资由东方富海、安徽省投资集团旗下的省产业投资公司、峰华资本等新股东联合投资,同时合肥产投、兴泰集团、合肥高投、安徽省人工智能母基金等老股东持续加注。

如何工业化生产AI漫剧。
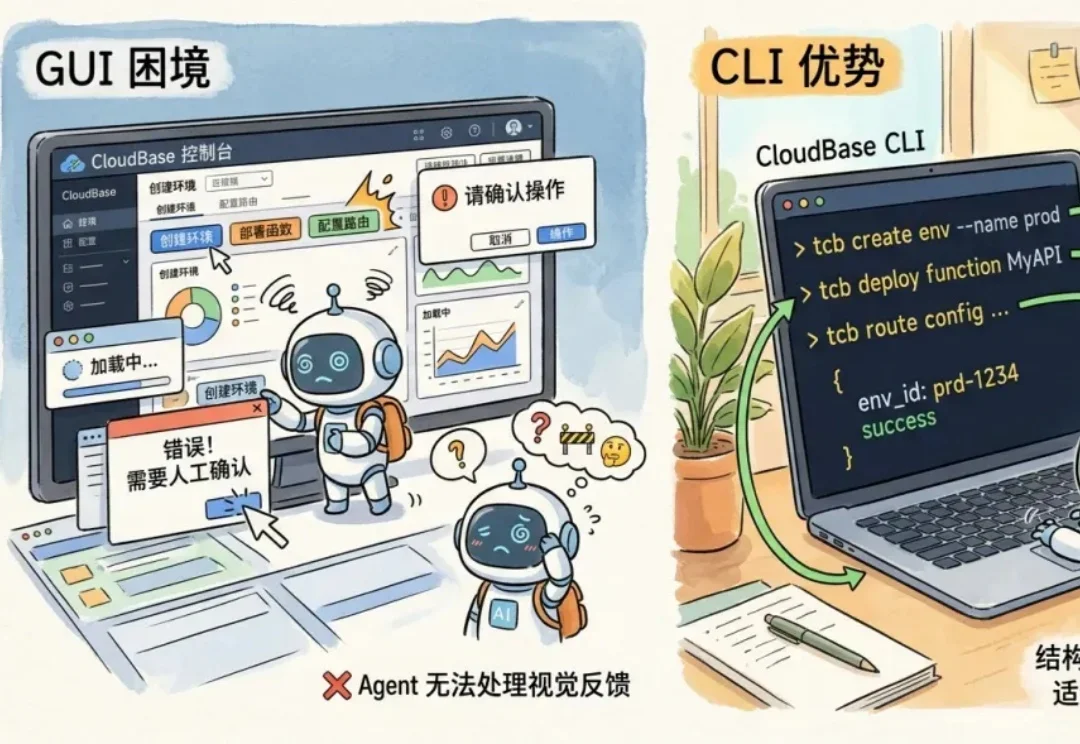
我们很荣幸地宣布 CloudBase CLI V3 正式上线,这是一个面向 AI Agent 重新设计的 CloudBase 命令行工具。

