# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
上下文学习”(In-Context Learning,ICL),是大模型不需要微调(fine-tuning),仅通过分析在提示词中给出的几个范例,就能解决当前任务的能力。您可能已经对这个场景再熟悉不过了:您在提示词里扔进去几个例子,然后,哇!大模型似乎瞬间就学会了一项新技能,表现得像个天才。但是,请稍等一下,模型真的通过ICL学会了吗?它真的会学习吗?是那种我们工程上理解的、能够举一反三的真学习吗?最近一篇来自微软的论文深入挖掘了这个问题,我觉得它的答案,可能会让您在开发生产环境用的Agent时,需要重新思考一下底层逻辑。

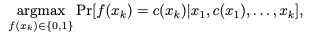
上下文学习(ICL)的概率模型公式:这个公式描述了大模型进行ICL决策的过程。它要做的就是在给定系统提示 (prompt)、n个范例E1到En和当前要解决的问题xt的条件下,选择一个最有可能的答案yt。
在学习论(PAC/generalization)里,一个方法称得上“会学习”,至少要满足这些要点,不依赖是否“更新权重”,而看它的泛化行为:
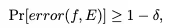
1.可泛化:看过来自训练分布P的若干范例后,对同一(或轻微变动的)分布里未见样本有低错误率,而且样本数增加可导致错误率下降(有可观的样本复杂度/收敛趋势)。
2.稳健而非“死记”:对表面措辞、范例顺序、位置等“无关因素”不敏感,能容忍少量噪声标签。
3.任务相关的能力边界清晰:对需要更强记忆/结构归纳的任务(如需“栈结构”的上下文无关类),若方法真的“学到本质”,性能应能跨表面变化保持,否则就只是贴合分布而非抽象规则。
4.在更大样本下的“归一”:随着范例数增大,不同提示话术,模型话术差异的重要性下降,说明主要“靠数据在驱动”而非靠巧语法。 说白了,就是如果LLM真的学会了,那就不应该因为新问题的问法和范例稍微有点不同,就一下子变得不知所措。

一个学习算法 f 的泛化错误率(在来自真实数据分布 D 的新样本 x 上犯错的概率)应该低于一个很小的数ϵ。
研究者们为大模型设计了一场极其严酷的“压力测试”,可以说把所有可能影响模型发挥的因素都考虑进去了。他们让GPT-4 Turbo、GPT-4o、Mixtral-8×7B-Instruct、Phi-3.5-MoE-Instruct四种主流模型接受这场考验,并且系统性地变换了“考试”方式,接下来我们详细看看这场“考试”到底有多严苛。
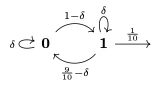
这张图展示了用于生成“奇偶校验(PARITY)”任务数据的概率自动机示意图。研究者如何通过精确控制其内部的转移概率δ ,来创造出统计特性不同的数据集,从而系统性地测试模型的泛化能力
研究者完全抛弃了那些模棱两可的语言问答,而是选择了规则明确、对错分明的9个形式化任务,总量约189万条评估数据。这样一来,模型的表现好坏就一目了然了。这些任务的难度各不相同,有些比较简单,有些则需要模型具备一定的“记忆力”。为了科学地衡量这种难度,研究者使用了计算理论中的两种模型,也就是FSA和PDA,来对任务进行分类。
我们可以把这两个模型理解成两种能力不同的“虚拟检查员”:
为了测试模型到底依赖什么来学习,研究者们用了各种各样的提示词(Prompt)策略来“喂”给模型任务信息。

这是整个实验设计的灵魂所在,直接考验模型的泛化能力。研究者通过控制生成数据的算法,创造了两种测试场景。
通过对海量实验数据的分析,研究者得出了几个关键结论:

1.“量变引起质变”,而非“少即是多”:与“少样本学习者”的普遍印象相反,模型的最佳平均性能通常出现在提供了50到100个示例时,远超“少数几个”。并且,当示例数量足够多时(在极限情况下)所有被测LLM的平均准确率都会提升,更重要的一点在于,不同LLM之间、不同指令策略之间的性能差距会显著缩小。这表明ICL的能力更多地源于自回归模型的基础机制,而非特定某个模型或指令的“魔法”。
2.泛化能力脆弱,对OOD数据敏感:ICL在处理分布外(OOD)数据时表现出明显的脆弱性。随着测试数据与示例数据分布的差异(δ)增大,所有模型的准确率都下降了。一个反直觉的发现是,那些在分布内数据上表现优异的“高级”指令策略,如思维链(CoT)和自动指令优化(APO),反而是对OOD数据最敏感、性能下降最快的。
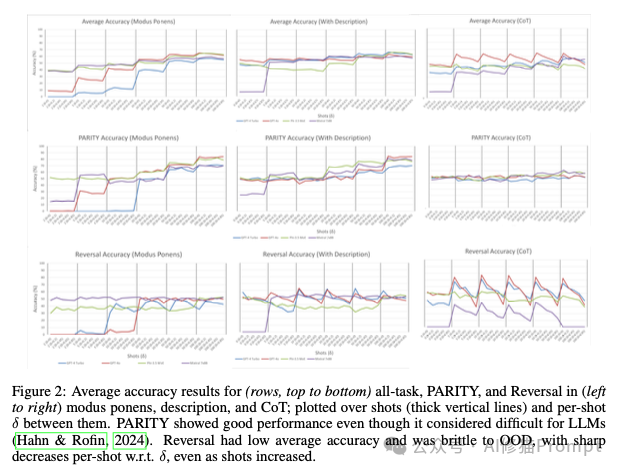
3.性能不稳定,相似任务表现迥异:研究者发现,即使是一些在形式上非常相似的任务,模型的表现也可能天差地别,准确率差距可高达31%。例如,模型在“模式匹配”(Pattern Matching)任务上几乎完美解决(平均准确率94%),但在同样是FSA可解的“迷宫求解”(Maze Solve)任务上准确率却低很多。任务间的准确率差距最高可达31%。此外,在半数的评估任务中,传统的机器学习基线模型(如决策树、kNN)的平均性能甚至超过了LLM的ICL。

这意味着:ICL并不是一种通用的、可靠的问题解决机制。模型的能力似乎与任务的形式化难度没有必然的强关联,可能受到其他因素(如数据表示、与预训练任务的相似度等)的严重影响。
为了更深入地理解ICL的机制,研究者还进行了一系列“控制变量”的消融研究:
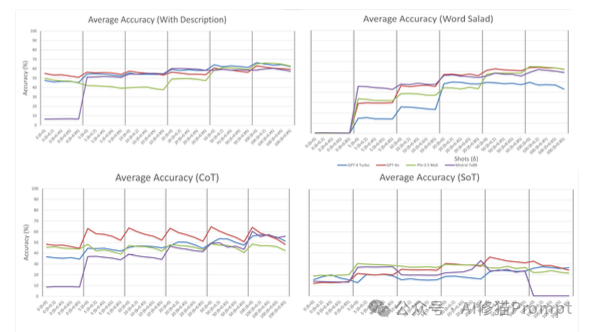
ICL 到底算不算学习?答案是:算,但主要是在“分布内”的学习。
ICL 不改权重,却会把“范例+待判别样本”在一次前向过程中进行现场编码,临时形成一个面向该任务的预测器。随着范例增多(尤其在较大shot数的时候),准确率上升、对措辞和顺序的敏感性下降,呈现出典型的“样本越多越会”的学习曲线,因此在学习论意义下,它展现了对同分布或轻度移位数据的泛化趋势。
但这类“学习”更像对范例分布的非参数化内插,而非稳定抽象出可广泛迁移的规则:一旦测试分布与范例分布偏移(OOD),性能可能明显下滑(如 CoT和APO 等策略更易过拟合表面规律)。
如果您要评测自己产品的AI功能,这篇论文告诉您可以加入与范例分布不同的 OOD 用例。否则,您也许只是在验证模型很会“对分布做贴合”,而非具备解决真实世界多样化输入的稳健泛化。
文章来自于微信公众号“AI修猫Prompt”。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
