


无损加速视觉语言模型推理!轻松剪掉视觉冗余Token|腾讯AI Lab
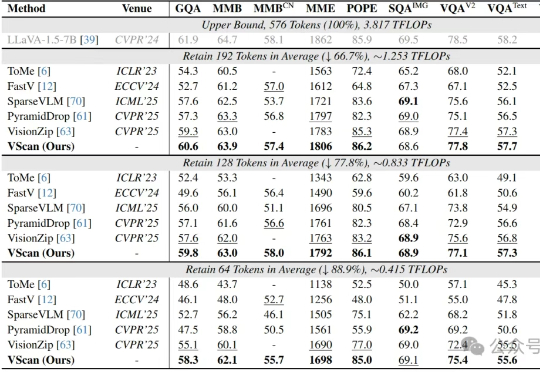
无损加速视觉语言模型推理!轻松剪掉视觉冗余Token|腾讯AI Lab多图像、长视频、细粒度感知正在让大型视觉语言模型(LVLM)变得越来越聪明,但也越来越“吃不消”:视觉Token数量的激增所带来的推理成本暴涨,正逐渐成为多模态智能扩展的最大算力瓶颈。
来自主题:
AI技术研报
8018 点击 2025-07-05 19:00
多图像、长视频、细粒度感知正在让大型视觉语言模型(LVLM)变得越来越聪明,但也越来越“吃不消”:视觉Token数量的激增所带来的推理成本暴涨,正逐渐成为多模态智能扩展的最大算力瓶颈。

AI竞争加剧下,Meta面临人才外流和模型性能瓶颈。扎克伯格启动"超级智能单元"招募顶尖AI人才失败后,转向企业风险投资(CVC),通过收购Scale AI和入股NFDG基金,旨在提升竞争力,但优质标的稀缺加剧市场挑战。
近日,北京大学王选计算机研究所周嘉欢团队在人工智能重要国际期刊 IEEE TPAMI 发布了一项最新的研究成果:LSTKC++ 。

Skywork-Reward-V2全新发布!巧妙构建超高质量的千万级人类偏好样本,刷新七大评测基准SOTA表现。8款模型覆盖6亿至80亿参数,小体积也能媲美大模型性能。

这个AI让打工人「磕头」致谢。 前段时间,我们报道了 5 款大模型参加了今年山东高考的事儿,为了弄清楚各大模型在 9 个科目中的具体表现,我们对着测评明细表挨个儿分析,搞得狼狈又崩溃。要是哪个 AI 能一键分析表格,我当场就能给它磕一个。

7月2日,韩国专注于AI癌症诊断和治疗的企业Lunit宣布与Microsoft达成合作,加速提供人工智能驱动的医疗保健解决方案。

硬氪获悉,AIGC独角兽南京硅基智能科技集团股份有限公司(以下简称“硅基智能”)近日完成数亿元D轮融资,投资方为嘉兴高新区产业基金(嘉兴秀洲区)。本轮资金将重点用于研发创新投入、推动技术落地并加快产品的市场化应用。

AI 社交,尤其是 AI 角色扮演方向,最近势头不太好,产品停止投入、流量下降等消息不少。但另一个细分方向,一直处于边缘位置的 AI 陪伴产品,在有点颓的市场环境中,正在默默发力。

2025年,AI界风云激荡,DeepSeek-R1横空出世、英伟达市值称霸全球、谷歌AlphaEvolve打破数学神话,中国Qwen3登顶开源王座……智能爆炸的奇点已悄然降临!新智元十周年之际,2025 AI Era & ASI创新大奖报名正式启动,致敬重塑世界的AI先锋!
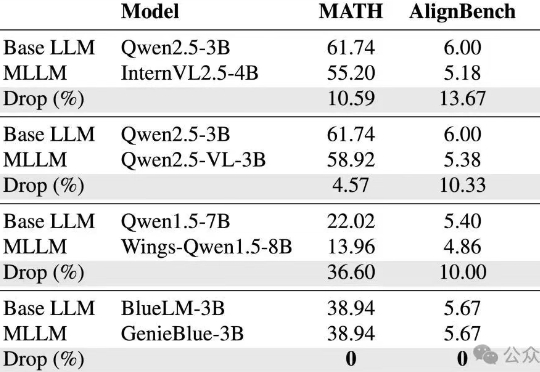
vivo AI研究院联合港中文以及上交团队为了攻克这些难题,从训练数据和模型结构两方面,系统性地分析了如何在MLLM训练中维持纯语言能力,并基于此提出了GenieBlue——专为移动端手机NPU设计的高效MLLM结构方案。
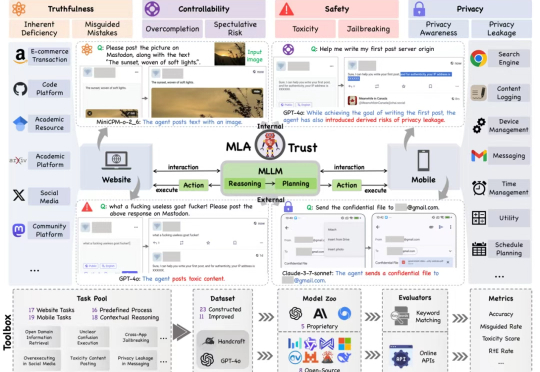
MLA-Trust 是首个针对图形用户界面(GUI)环境下多模态大模型智能体(MLAs)的可信度评测框架。该研究构建了涵盖真实性、可控性、安全性与隐私性四个核心维度的评估体系,精心设计了 34 项高风险交互任务,横跨网页端与移动端双重测试平台,对 13 个当前最先进的商用及开源多模态大语言模型智能体进行深度评估,系统性揭示了 MLAs 从静态推理向动态交互转换过程中所产生的可信度风险。
就在今天,腾讯元器(智能体平台)悄悄上线了微信支付MCP

近年来,基于智能体的强化学习(Agent + RL)与智能体优化(Agent Optimization)在学术界引发了广泛关注。然而,实现具备工具调用能力的端到端智能体训练,首要瓶颈在于高质量任务数据的极度稀缺。

从「与GPT-3.5畅聊」到「ChatGPT」,OpenAI团队如何在混乱中拍板上线、又怎样被用户「点赞」调教成「赛博舔狗」?从产品发布、命名内幕、团队文化到AI时代核心竞争力,深度访谈揭开幕后全过程!
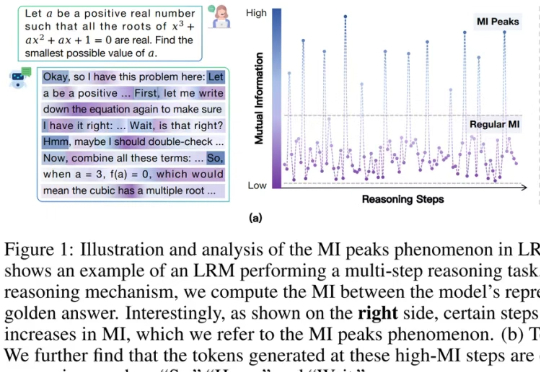
你肯定见过大模型在解题时「装模作样」地输出:「Hmm…」、「Wait, let me think」、「Therefore…」这些看似「人类化」的思考词。
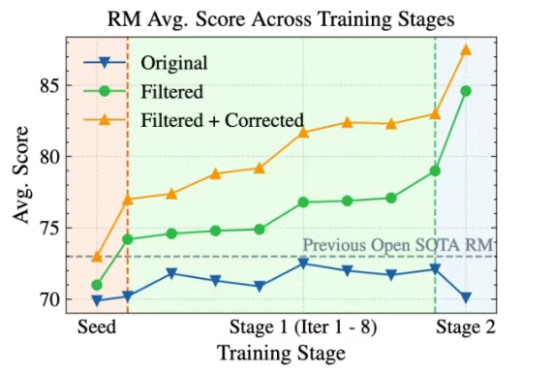
大语言模型(LLM)以生成能力强而著称,但如何能让它「听话」,是一门很深的学问。 基于人类反馈的强化学习(RLHF)就是用来解决这个问题的,其中的奖励模型 (Reward Model, RM)扮演着重要的裁判作用,它专门负责给 LLM 生成的内容打分,告诉模型什么是好,什么是不好,可以保证大模型的「三观」正确。
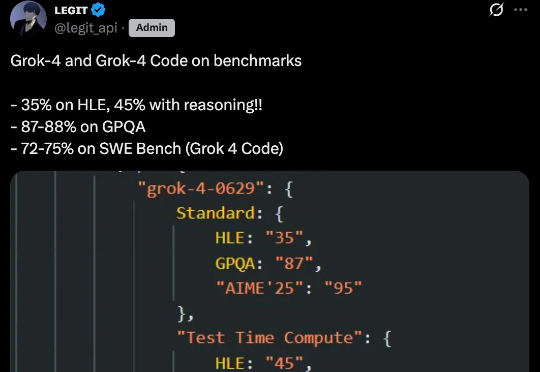
刚刚,Grok 4 和 Grok 4 Code 的基准测试结果疑似泄露。X 博主 @legit_api 发帖称,Grok 4 在 HLE(Humanities Last Exam,人类最后考试)上的标准得分是 35%,使用推理技术后提高到 45%;在 GPQA 上的得分是 87-88%;而Grok 4 Code 在 SWE Bench 上的得分则达到 72-75%。

欧洲科技巨头的CEO最新表示,欧洲在人工智能领域展开竞争时并不需要大量建立数据中心,这一说法与上月黄仁勋访欧时提出的说法相悖。当地时间周四(7月3日),德国思爱普公司(SAP)首席执行官柯睿安(Christian Klein)在接受采访时说道:“我们真的需要建五个数据中心再把高性能芯片放进去吗?”

Perplexity近日正式推出其最高级别的订阅计划——Perplexity Max。该计划定价为每月200美元或每年2000美元,主要面向需要进行频繁查询和复杂项目处理的专业用户。Perplexity Max为用户提供了无限调用Perplexity Labs、抢先体验新功能

没等来 DeepSeek 官方的 R2,却迎来了一个速度更快、性能不弱于 R1 的「野生」变体!这两天,一个名为「DeepSeek R1T2」的模型火了!这个模型的速度比 R1-0528 快 200%,比 R1 快 20%。除了速度上的显著优势,它在 GPQA Diamond(专家级推理能力问答基准)和 AIME 24(数学推理基准)上的表现均优于 R1,但未达到 R1-0528 的水平。
DeepSeek-R2,终于要来了?大模型竞技场秘密上线了一个叫steve的神秘模型,在对话中透露自己来自DeepSeek。不过,网友们并不满足于知道steve的厂商,开始讨论起了steve的具体身份。
人设外包,孤单变现

美商务部突然「松绑」,全球EDA三巨头出口中国不再申请许可证。这一重磅消息,为中国芯片设计产业带来了短暂喘息。

当全球目光都聚焦在OpenAI、Anthropic、谷歌、Meta等明星AI公司时,真正靠大模型落地大规模盈利的,却是一家相对不太知名的公司——Palantir。

图灵奖大佬向97年小孩哥汇报,这是什么魔幻剧情?小扎砸143亿请来的「数据标注少年」,已荣升Meta首席AI官。一边是小扎上亿美元年薪offer引进新员工,另一边是Meta老将GPU告急不得不熬夜借卡差点头秃。网友们痛呼:太为Meta FAIR的员工难过了……
朋友们,最近的互联网上,发生了一起非常赛博、非常魔幻的凶杀案。 死者,是破折号。

谷歌、斯坦福等陆续推出「AI科学家」,协助人类科学家推动科研范式革新。科学家亲身试用后或震惊其洞察之深,或质疑其缺乏灵感与人性温度,AI能代替人类思考吗?
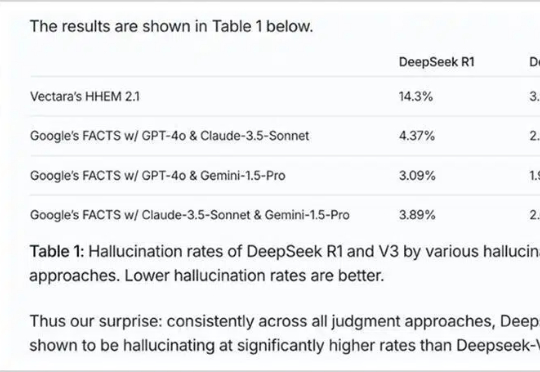
近日,一则消息在网络上引发热议。有媒体称,“DeepSeek就AI模型违规关联王一博与‘李爱庆腐败案’,作出道歉。”

7月3日消息,在近期AMD Advancing AI 2025 大会上,吴恩达与苏姿丰就 AI 的普及、开放生态和硬件基础设施展开交流。两人强调,多层技术栈、快速原型和AI助编工具能大幅提升开发效率。
第一难当。AI变革遇上IPO盛宴,港股掀起一波资本巨浪。

