


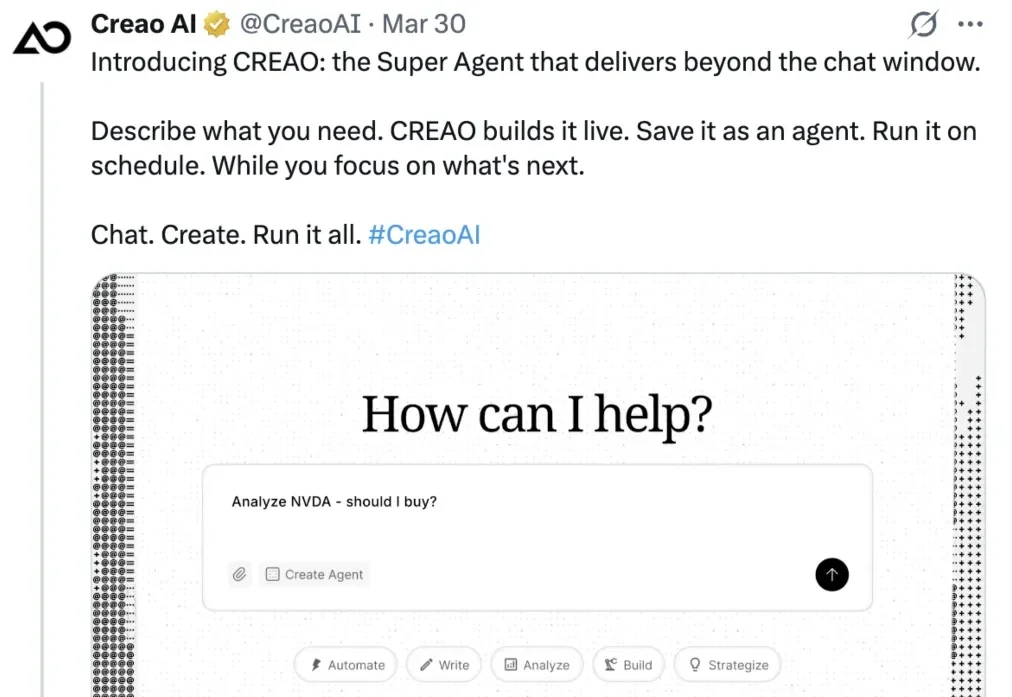
帮普通人「驯服」Agent,这支硅谷初创团队冲上了X全球热搜
帮普通人「驯服」Agent,这支硅谷初创团队冲上了X全球热搜「用一句话交代任务,然后什么都不用管,AI 自动执行。」这或许是大家最初对「AI 超级助手」的想象。
来自主题:
AI资讯
5694 点击 2026-04-09 16:21
「用一句话交代任务,然后什么都不用管,AI 自动执行。」这或许是大家最初对「AI 超级助手」的想象。

卖出了两万台 AI 宠物,ropet 这样复盘 AI 陪伴赛道这一年。

Claude Code这样私有的编程智能体虽然能力强大,但有着封闭、昂贵、难以定制的局限。艾伦研究院推出的Open Coding Agents,让你只需要400美元就能训练一个32B的专属编程智能体。

刚刚,Claude推出“企业版”服务,发布Claude Managed Agents,结果被开源项目“开团秒跟”!

Anthropic 发布了史上最强的模型 Claude Mythos。

Lindy.ai 的创始人 Flo Crivello 做了件挺大胆的事:把 AI 助理塞进了 iMessage。不是做一个新 App,不是搞一个聊天界面,就是直接出现在你的短信列表里,像一个真人助理一样跟你对话。

MSL交出首张答卷。

AI交互的「机械感」消失了!今天,豆包甩出原生全双工语音大模型Seeduplex,不仅能边听边说,甚至能听懂你在思考时的「卡壳」,就算环境再吵也不怕,抗干扰能力直接拉满。
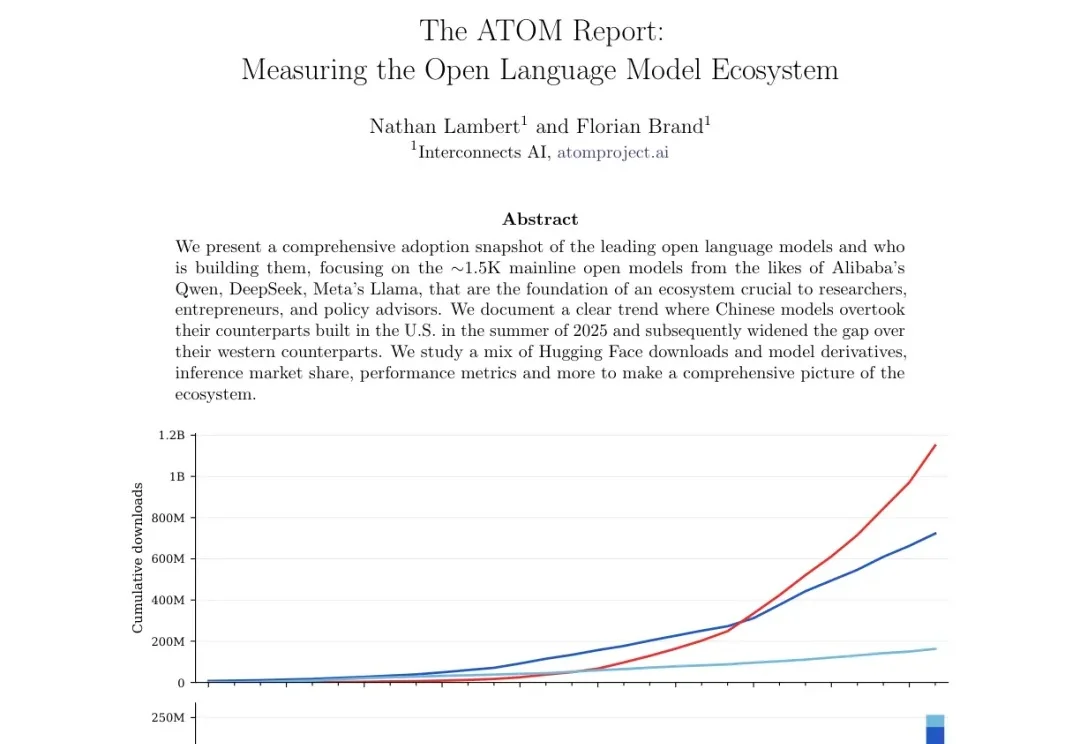
2026 年 4 月,Nathan Lambert 和 Florian Brand 发布了 The ATOM Report,一份关于开源语言模型生态的综合采纳度快照。这份报告追踪了约 1500 个主线开源模型的下载量、衍生模型、推理市场份额和性能数据,覆盖 2023 年 11 月到 2026 年 3 月

从能实时监控心率的床到用鸿蒙底座链接的皮料加工车间,AI已经全面渗透。

Claude Mythos太猛了。

不讲 Vibe Coding,而是 Vibe Working。
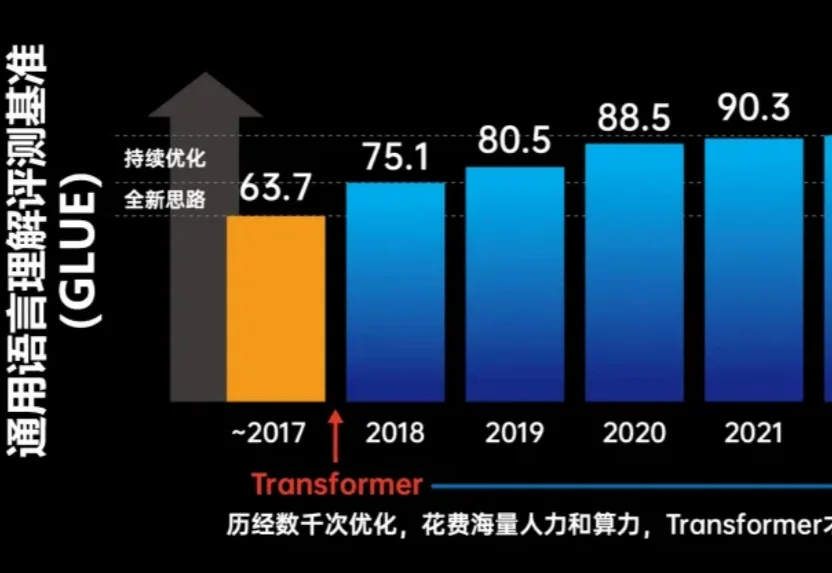
在人工智能研究中,许多研究者将大量时间投入到为那 1% 的性能提升反复调参与实验迭代之中。
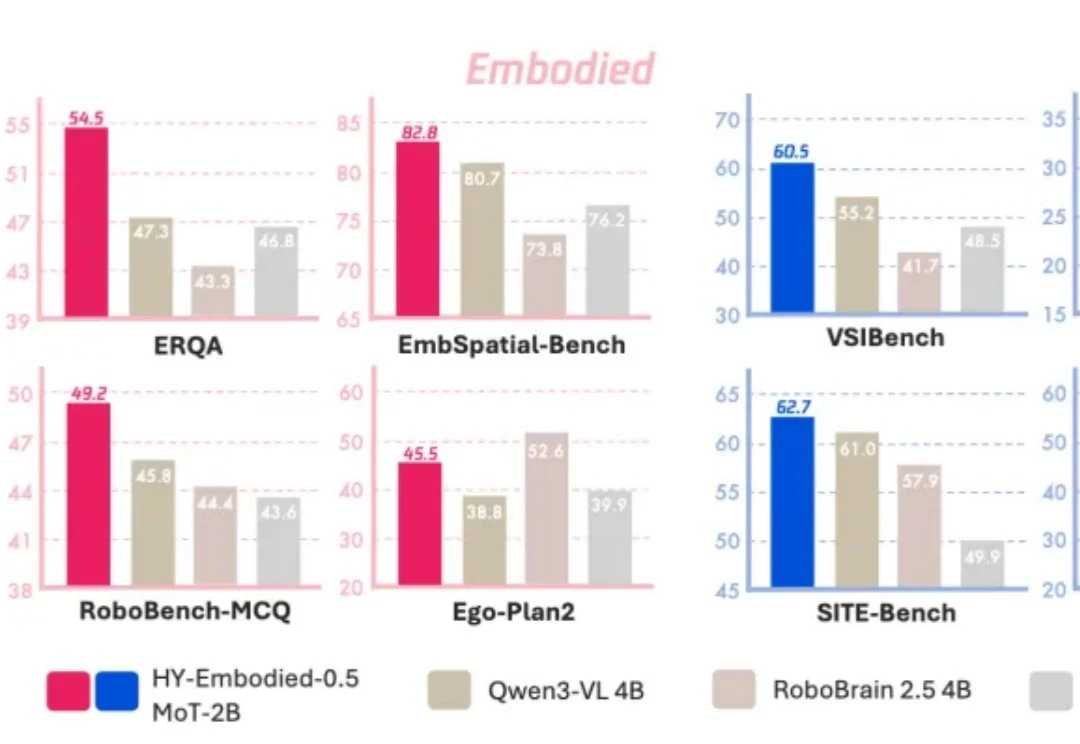
让大模型真正走进现实世界,是当下最迫切的需求之一。

RL之后,大模型为什么更容易「越训越单一」?面对五花八门的改进思路,也许答案并不复杂:先试着改一改KL项。

今天我们发布 MMX-CLI,一个面向 AI Agent 的命令行工具。接入 MMX-CLI 后,Agent 可以在 Claude Code、OpenClaw 等环境中原生调用 MiniMax 最新的编程、视频生成、语音合成、音乐创作等全模态模型,无需适配繁琐接口,也无需额外编写 MCP Server。
Anthropic推出平台级产品:Claude Managed Agents,开发周期从数月压缩到几天,To B业务更进一步,这是直接给了一个Harness Agent的盒子,用户只管干活就行了,随着产品发布,A厂还发布了一篇Harness(Managed Agents)工程细节文章,感觉A厂就差说在座的都是xx了,再一次遥遥领先!我们一文来说清楚

用13个月时间完成5轮融资,实现估值30倍暴涨。

国产AI营销持续刷屏行业!原本2周策划,现在十几分钟落地,从内容爆款到精准投放全流程智能搞定。营销人别再拍脑袋,再不跟上这个浪潮,669亿AI营销市场真没你份了。

硅谷「华人地图第一人」入局具身数据赛道。

微信远程指挥电脑干活,自动比价、发微博。

Generalist AI的GEN-1热度,仍在发酵。
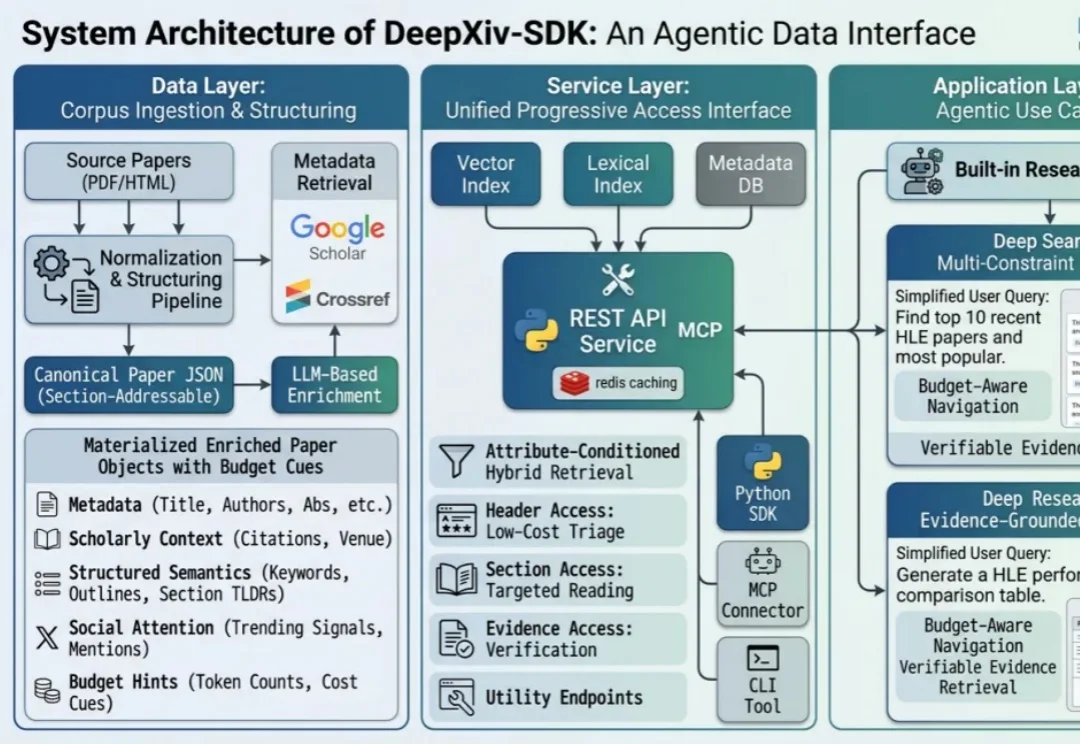
DeepXiv 是专为智能体设计的科技文献基础设施,把论文搜索、渐进式阅读、热点追踪和深度调研变成可调用、可编排、可自动化的能力。

AI 购物是下一代消费的核心入口?
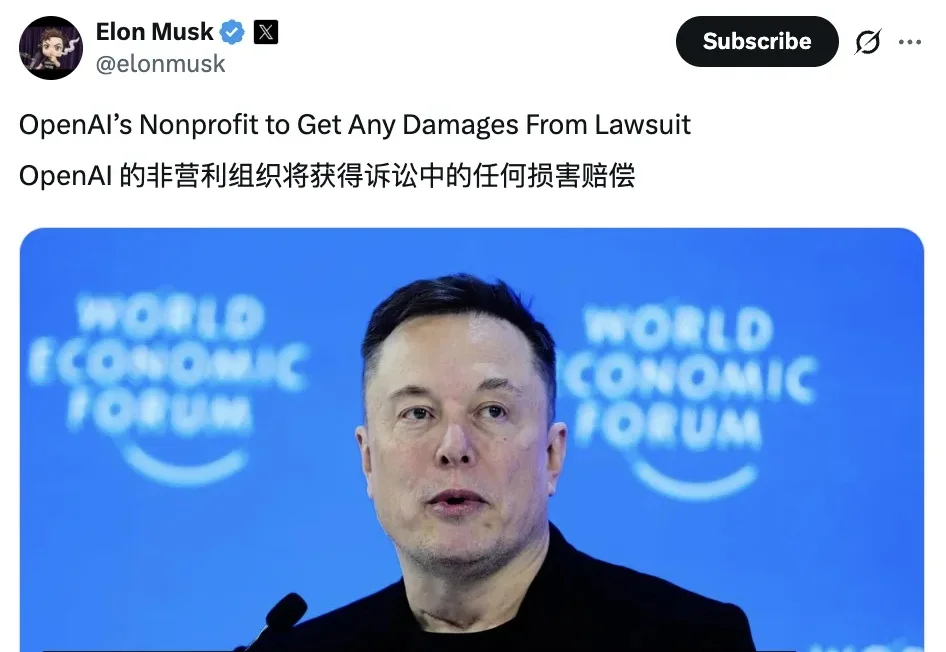
马斯克连赔偿款都不要了,现在状告OpenAI只有一个核心诉求: 把奥特曼从OpenAI非营利母公司董事会除名。

一枚戒指里的“Token经济学”。

从高价值商业场景切入,打造“真通用”的具身智能。
AI生成图表,难道只能靠碰运气?

我认真看 Hermes Agent,不是因为它2.9万Star,而是因为那条 hermes claw migrate。一个新框架敢把"把旧用户整套资产搬过来"做成默认入口,这事本身就很说明问题。

黄仁勋用「五层蛋糕」讲清了AI全栈生态的分层逻辑,易鑫则把它翻译成汽车金融的落地打法:从算力、模型到Agent落地,解决的全是汽车金融最难的活。

