Karpathy盛赞,啥都没有的创业公司刚融了1.8亿美元,Flapping Airplanes要用小数据造强智能
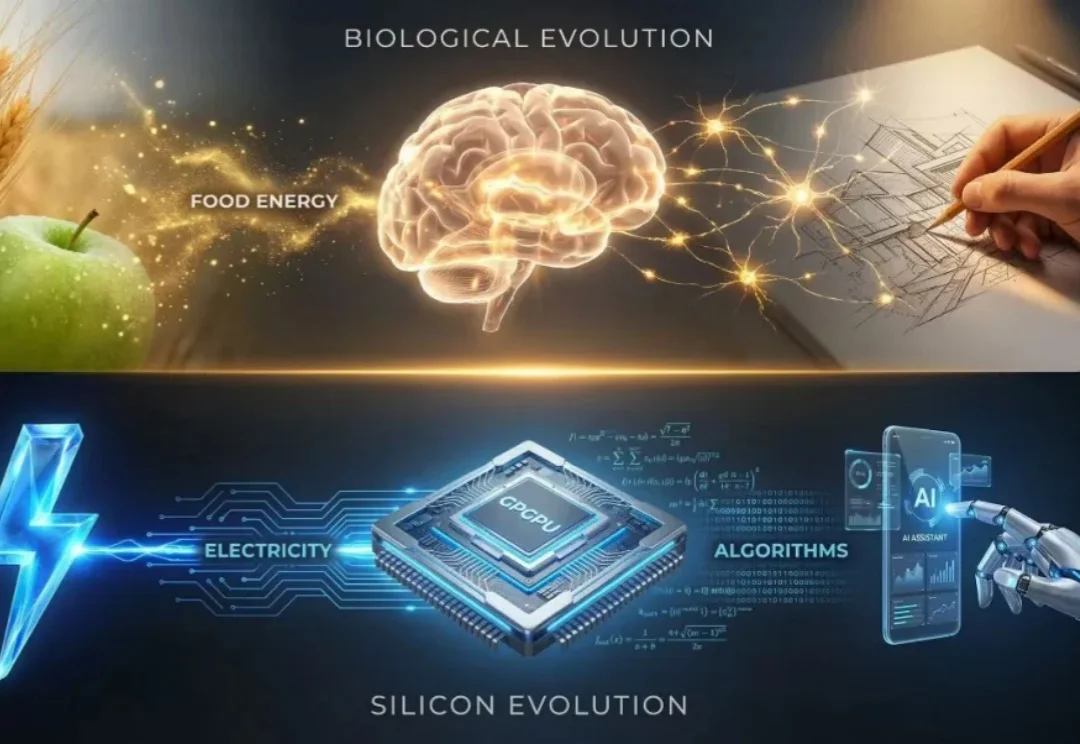
Karpathy盛赞,啥都没有的创业公司刚融了1.8亿美元,Flapping Airplanes要用小数据造强智能AI 需要整个互联网来学习,而人类只需要一个童年。人类在成年之前,所接触的语言、文本与符号,顶多只有几十亿 token,相差几个数量级。正是从这个问题出发,一家几乎没有产品、没有盈利、也不急于商业化的 AI 创业公司,从 GV、Sequoia 和 Index 拿到了 1.8 亿美元融资,并获得了 Andrej Karpathy 的公开力挺。
来自主题:
AI资讯
7044 点击 2026-01-30 10:43