# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
有不少朋友认为,提示词工程没有前途。但扎心的事实是,提示词(Prompt)的设计和优化已经成为影响模型性能的关键因素。无论是在数学推理、常识判断还是逻辑分析等任务中,一个精心设计的提示词往往能让模型的表现有质的飞跃。然而,目前业界普遍认为,只有像GPT-4o或者Claude sonnet这样的超大规模语言模型才能胜任提示词优化的任务。这导致了一个尴尬的现实:为了优化小模型的提示词,我们不得不求助于计算成本高昂的大模型。这种依赖不仅增加了开发成本,还限制了小模型的应用场景。
Pennsylvania State University和Salesforce Research的研究团队提出了一个很有潜力的观点:通过巧妙地利用梯度信息,小型语言模型也能成为出色的提示词优化器。他们开发的GREATER(GRadiEnts ovEr ReAsoning)方法,让8-9B参数规模的小模型在提示词优化任务上达到甚至超越了GPT-4的水平。这一发现不仅挑战了业界的固有认知,更为提示词优化领域开辟了一条全新的技术路线。

在深入了解GREATER的创新之处前,我们有必要先理解当前提示词优化方法存在的问题。目前主流的方法,如APE(Automated Prompt Engineering)和APO(Automatic Prompt Optimization),都采用"文本反馈"的思路:使用大模型分析小模型在特定任务上的错误,然后基于这些反馈来改进提示词。这种方法存在几个明显的缺陷:首先,它完全依赖大模型的判断,这意味着优化过程的质量受限于大模型的能力;其次,文本反馈往往是模糊和主观的,缺乏明确的优化方向;最后,这种方法的计算成本很高,因为需要反复调用大模型来生成反馈。
更重要的是,研究者们发现,当使用小模型来生成这种文本反馈时,优化效果往往很差。这似乎印证了业界的普遍看法:小模型不具备足够的推理能力来优化提示词。然而,研究团队提出了一个关键洞察:问题不在于小模型的能力不足,而在于我们没有充分利用模型内部的梯度信息。
GREATER方法的核心创新在于将提示词优化问题转化为一个基于梯度的优化问题。与传统方法不同,GREATER不是简单地让模型生成文本反馈,而是巧妙地利用模型在推理过程中产生的梯度信息来指导提示词的优化。这个过程可以分为三个关键步骤:

1.候选词生成:GREATER首先让模型基于当前输入生成一组可能的候选词。这些候选词不是随机选择的,而是通过模型的前向概率分布来确定的,确保它们与任务相关且语义合理。
2.推理链生成:对于每个候选词,模型都会生成一个完整的推理链。这个推理链不仅包含最终答案,还包含了模型是如何一步步推导出这个答案的。这一步的关键在于,它让我们能够评估每个候选词对模型推理过程的影响。
3.基于梯度的选择:最后,GREATER计算每个推理链相对于目标答案的损失,并通过反向传播获得相对于候选词的梯度。这些梯度信息直接反映了每个候选词对提升模型性能的潜在贡献。
这种方法的独特之处在于,它不需要外部模型的判断,而是充分利用了模型自身的梯度信息。这不仅大大降低了计算成本,更重要的是提供了一个明确的、可量化的优化方向。
GREATER的候选词生成过程采用了一种基于概率的筛选方法。具体来说,对于提示词中的每个位置i,系统会执行以下步骤:
1.初始筛选:
2.概率阈值:
3.语义相关性:
这种多层筛选机制确保了候选词既符合语言模型的分布特征,又与具体任务相关。相比随机采样或固定词表,这种方法大大提高了优化效率。
GREATER的核心创新在于其梯度计算方式。传统的提示词优化方法往往直接计算最终答案的损失梯度,而GREATER引入了"推理链梯度"的概念:
1.损失函数设计:
L = LCE(fLLM(x⊙p⊙r⊙pextract), y) + λLperpl
其中:
2.梯度计算流程:
3.优化策略:
这种基于推理链的梯度计算方法有两个关键优势:
如下例所示:
def forward(*, model, input_ids, attention_mask, batch_size=512):
logits = []
for i in range(0, input_ids.shape[0], batch_size):
# Sequential Forced Batching
batch_input_ids = input_ids[i:i + batch_size]
if attention_mask is not None:
batch_attention_mask = attention_mask[i:i + batch_size]
else:
batch_attention_mask = None
logits.append(model(input_ids=batch_input_ids, attention_mask=batch_attention_mask).logits)
gc.collect()
del batch_input_ids, batch_attention_mask
return torch.cat(logits, dim=0)
def target_loss(logits, ids, target_slice):
crit = nn.CrossEntropyLoss(reduction='none')
loss_slice = slice(target_slice.start-1, target_slice.stop-1)
loss = crit(logits[:,loss_slice,:].transpose(1,2), ids[:,target_slice])
return loss.mean(dim=-1)
相比传统的基于大模型反馈的方法,GREATER在计算效率上有显著优势:
1.时间复杂度:
2.空间复杂度:
3.计算资源对比:
研究团队在多个具有挑战性的任务上评估了GREATER的性能。他们选择了两个代表性的小模型:Llama-3-8B和Gemma-2-9B,并在以下三类任务上进行了测试:
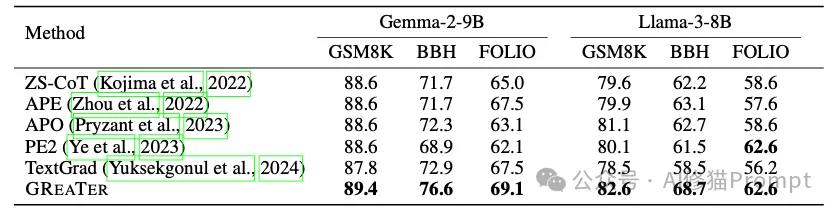
1.GSM8K数学推理任务:
2.BBH(Big-Bench-Hard)任务集:
3.FOLIO逻辑推理任务:
更令人惊讶的是,GREATER优化后的提示词表现出了强大的迁移能力。例如,用Llama-3-8B优化的提示词直接应用到Gemma-2-9B上,性能几乎没有损失。这说明GREATER找到的是真正有效的提示词模式,而不是针对特定模型的过拟合结果。
为了更直观地理解GREATER的优化效果,让我们来看论文中的几个具体案例:
1.电影推荐任务(Movie Recommendation):
2.因果推理任务(Causal Judgement):
3.形式逻辑任务(Formal Fallacies):
4.数学推理任务(Multistep Arithmetic):
这些案例展示了GREATER优化的几个关键特点:
1.特定格式的提示:
2.任务特化:
3.可迁移性:
这些优化效果不仅体现在准确率的提升上,更重要的是展示了一种新的提示词设计范式:从简单的自然语言描述转向更有结构、更有方法论指导的形式。这种范式的转变对提示词工程实践具有重要的启发意义。
GREATER的成功对Prompt工程师有几个重要启示:
1.提示词设计的新思路:
2.小模型的潜力:
3.优化方法的选择:
GREATER的研究表明,在提示词优化领域,创新的方法可能比简单地依赖更大的模型更有价值。这为构建更高效、更经济的AI应用开辟了新的可能性。对于Prompt工程师来说,这意味着我们需要重新思考提示词优化的方法论,将注意力从"找到最强大的模型"转向"最大化现有模型的潜力"。
文章来自微信公众号“AI修猫Prompt”,作者“AI修猫Prompt”




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
