# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在大语言模型(LLM)蓬勃发展的今天,提示词工程(Prompt Engineering)已经成为AI应用开发中不可或缺的关键环节。然而,手动设计和优化提示词不仅耗时耗力,而且往往需要领域专家的深度参与。特别是在处理不同任务时,每次都需要重新设计和调整提示词,这种重复性的工作极大地限制了AI应用的快速迭代和规模化部署。

图片由修猫创作
“在这样的背景下,微软研究院的印度研究团队提出了一个革命性的解决方案——PromptWizard框架,这是一个完全自动化的提示词优化系统,它通过自我进化和自适应机制,能够自动生成高质量的任务特定提示词。

论文发表于2024年5月份,因为当时没有给出代码,所以一直没有引起足够的重视。这几天代码放出来了,主逻辑代码core_logic.py仅609行,但功能异常强大:
✨ 自动生成高质量提示词
🔄 自动生成推理链
👨💼 自动生成专家角色
🎯 自动生成任务意图
📝 自动生成多样化示例
⚡ 自动生成序列化优化
🔗 自动生成自生成推理链
🎨 自动生成任务意图和专家角色整合
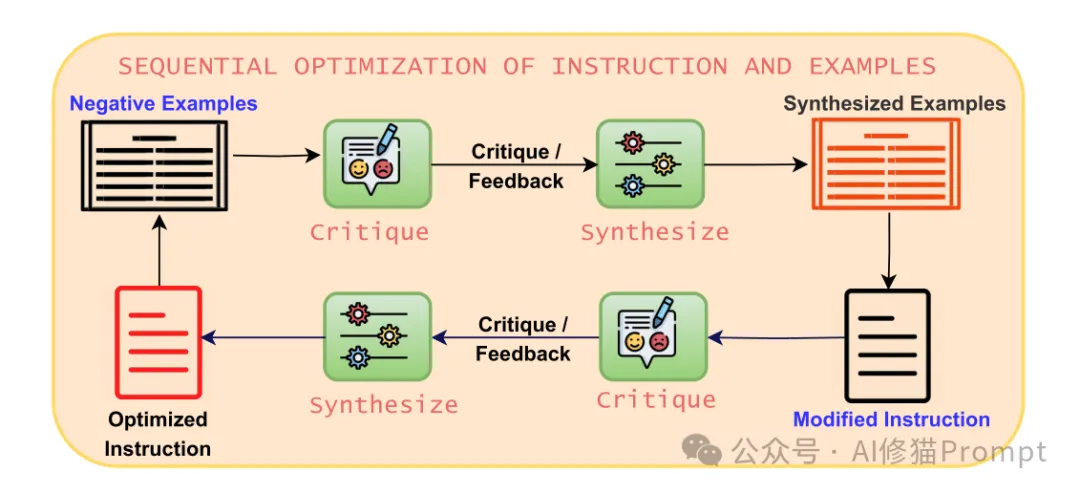
具体的优化过程示例如图5所示,通过多轮迭代和优化,系统能够不断改进提示词的质量。
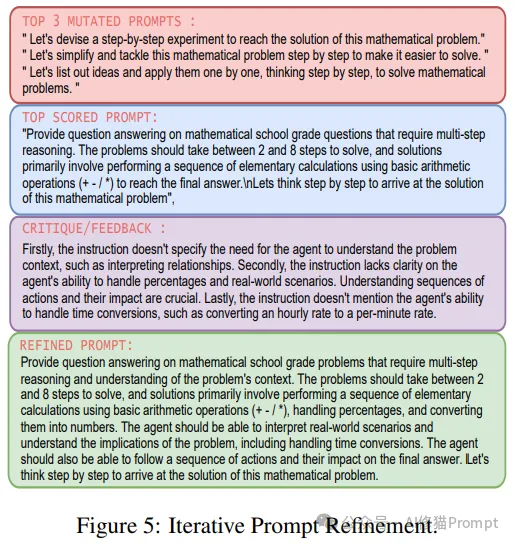
关于自我进化部分您可以看一看以下文章中的第二篇,Google DeepMind PROMPTBREEDER,2023年9月的论文,让AI系统不再被动地执行人类设计的提示,而是能够自主进化出更优秀的提示策略,从而大幅提升自身的推理能力和问题解决能力。
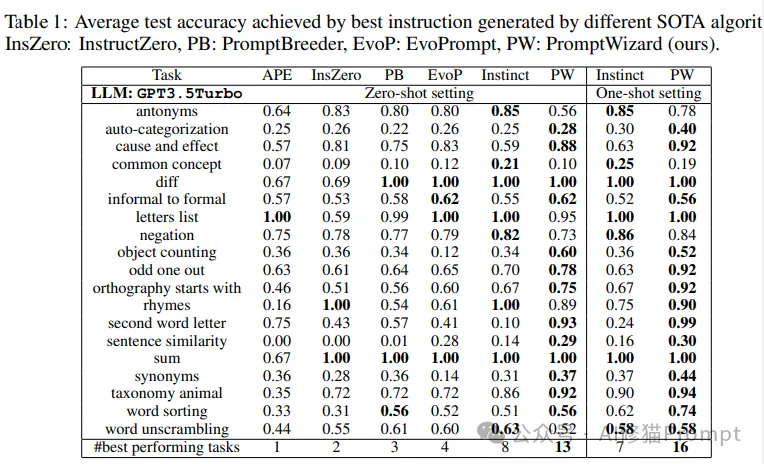
最终的实验结果(如表1所示)进一步证实了PromptWizard在各类任务上的卓越表现,特别是在算术推理等具有挑战性的任务中表现出色。
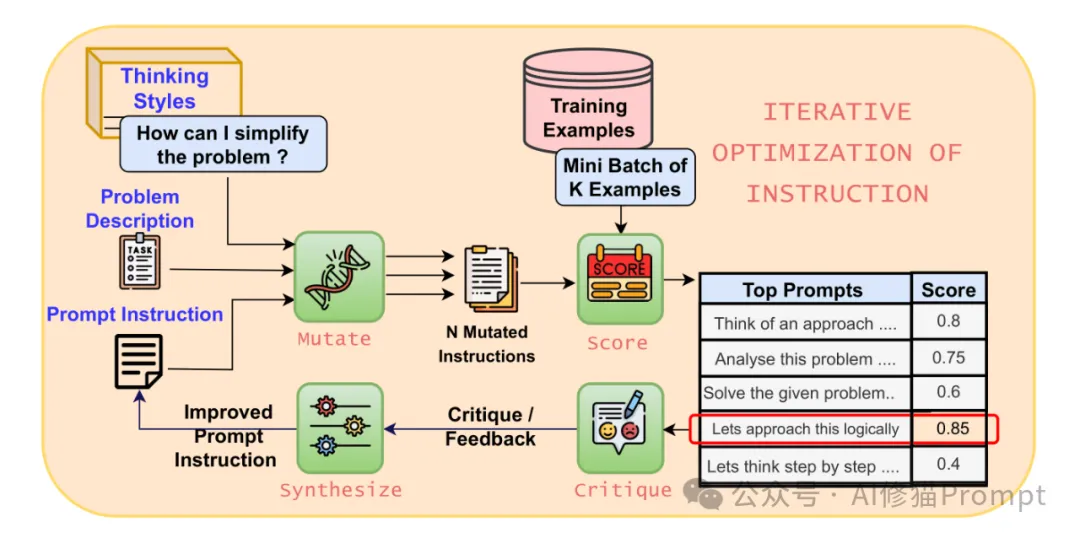
PromptWizard最显著的技术创新在于其独特的自我进化机制。与现有的提示词优化方法相比,它采用了一种基于反馈的批评和综合过程,能够在探索和利用之间取得有效平衡。
1.提示词生成
2.反馈驱动的优化
3.双重优化策略
PromptWizard采用了一个结构清晰、层次分明的系统架构(如图1所示)。
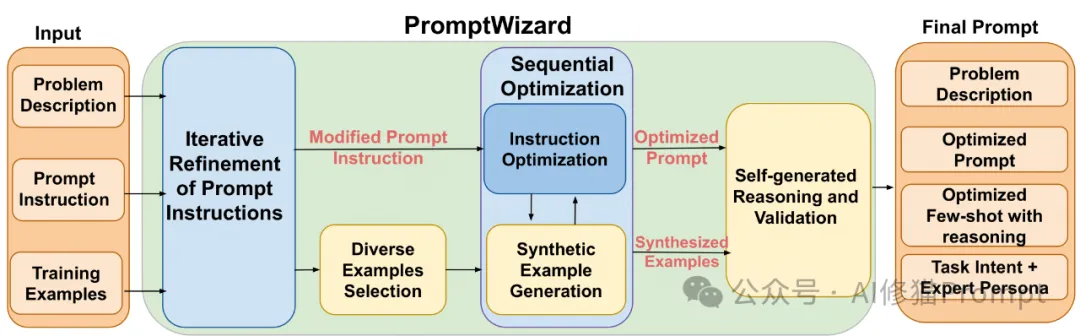
1.输入阶段
2.迭代优化阶段
“通过迭代优化机制(如图3所示)对提示词进行持续改进。这个过程包含了批评和反馈的循环,确保每次迭代都能产生更好的结果。
1.序列化优化阶段
2.示例生成与整合
在实际性能表现上,PromptWizard展现出了显著的优势:
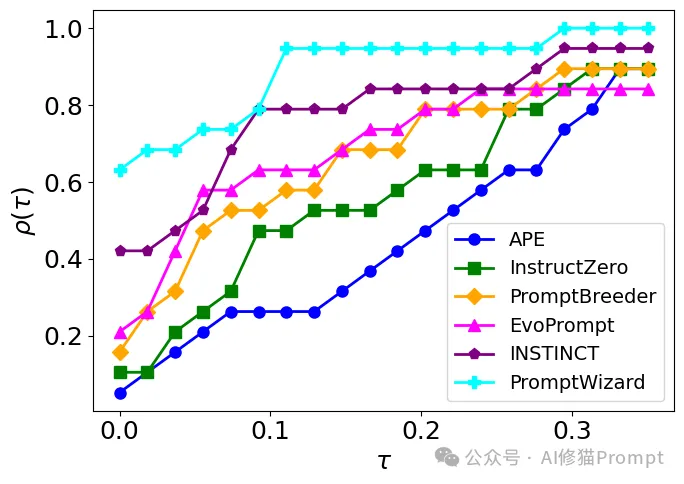
“在GSM8k、AQUARAT和SVAMP等算术推理数据集上,PromptWizard展现出了优秀的性能。例如,在GSM8k数据集上,它实现了90%的准确率,比基线方法提高了15个百分点以上。
与现有方法相比,PromptWizard在API调用次数和token使用量上都实现了显著的降低:
1.提示词指令迭代优化
“通过多轮迭代优化提示词指令,包含生成、评估、批评和改进的完整循环。
2.多样化示例选择
3.序列化优化
4.自生成推理链
5.任务意图和专家角色整合
1.基准测试性能
“在BIG-Bench指令归纳(BBII)数据集上,在19个具有挑战性的任务中的13个任务上取得最佳性能。
2.算术推理能力
3.领域特定任务
4.成本效益分析
“API调用次数减少5-60倍,显著节省计算资源和时间。
1.训练数据需求低
2.适应性强
3.成本优势
4.可解释性强
看一下PromptWizard的代码,采用了模块化的设计架构,主要包含以下几个核心模块:
1.提示词优化引擎(promptopt):这是框架的核心模块,负责整个提示词优化过程的协调和管理。主要包含以下组件:
2.参数日志记录(paramlogger):这个模块负责记录和追踪优化过程中的各种参数变化,帮助理解和调试优化过程。它能够:
3.通用功能模块(common):提供了框架所需的基础功能支持,包括:
4.优化技术库(techniques):包含了各种提示词优化技术的具体实现,例如:
系统的工作流程如下:
1.初始化阶段:
def initialize_optimization(problem_description, training_samples):
# 初始化优化器
optimizer = PromptOptimizer(
model_type="gpt-3.5-turbo",
max_iterations=5,
batch_size=25
)
# 设置初始提示词和示例
initial_prompt = generate_initial_prompt(problem_description)
examples = select_diverse_examples(training_samples)
return optimizer, initial_prompt, examples
2.参数日志记录(paramlogger)
3.通用功能模块(common)
4.优化技术库(techniques)
def optimize_prompt(optimizer, initial_prompt, examples):
for iteration in range(optimizer.max_iterations):
variants = optimizer.generate_variants(initial_prompt)
scores = optimizer.evaluate_variants(variants, examples)
best_variant = select_best_variant(variants, scores)
feedback = optimizer.get_critique(best_variant)
improved_prompt = optimizer.synthesize(best_variant, feedback)
initial_prompt = improved_prompt
return improved_prompt
1.示例优化过程:
def optimize_examples(optimizer, prompt, initial_examples):
# 分析示例
example_feedback = optimizer.analyze_examples(initial_examples)
# 生成合成示例
synthetic_examples = optimizer.generate_examples(example_feedback)
# 验证示例质量
validated_examples = optimizer.validate_examples(synthetic_examples)
# 生成推理链
examples_with_reasoning = optimizer.add_reasoning_chains(validated_examples)
return examples_with_reasoning
2.任务意图和专家角色整合:
def integrate_intent_and_persona(optimizer, prompt, task_description):
# 提取任务意图
task_intent = optimizer.extract_intent(task_description)
# 生成专家角色
expert_persona = optimizer.generate_expert_persona(task_intent)
# 整合到提示词中
final_prompt = optimizer.integrate_components(
prompt,
task_intent,
expert_persona
)
return final_prompt
这种模块化的设计使得系统具有很好的可扩展性和维护性。每个模块都可以独立更新和优化,同时通过统一的接口进行协作。系统还实现了完整的错误处理和日志记录机制,确保了优化过程的可靠性和可追踪性。
def optimize_examples(optimizer, prompt, initial_examples):
# 分析示例
example_feedback = optimizer.analyze_examples(initial_examples)
# 生成合成示例
synthetic_examples = optimizer.generate_examples(example_feedback)
# 验证示例质量
validated_examples = optimizer.validate_examples(synthetic_examples)
# 生成推理链
examples_with_reasoning = optimizer.add_reasoning_chains(validated_examples)
return examples_with_reasoning
3.任务意图和专家角色整合:
def integrate_intent_and_persona(optimizer, prompt, task_description):
# 提取任务意图
task_intent = optimizer.extract_intent(task_description)
# 生成专家角色
expert_persona = optimizer.generate_expert_persona(task_intent)
# 整合到提示词中
final_prompt = optimizer.integrate_components(
prompt,
task_intent,
expert_persona
)
return final_prompt
这种模块化的设计使得系统具有很好的可扩展性和维护性。每个模块都可以独立更新和优化,同时通过统一的接口进行协作。系统还实现了完整的错误处理和日志记录机制,确保了优化过程的可靠性和可追踪性。
“PromptWizard的出现代表了提示词工程领域的一个重要里程碑。它解决了当前提示词优化中的关键痛点。随着技术的不断发展和完善,我们有理由期待看到更多基于PromptWizard的创新应用和突破。
文章来自微信公众号“AI修猫Prompt”,作者“AI修猫Prompt”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
