# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
视频生成模型卷得热火朝天,配套的视频评价标准自然也不能落后。
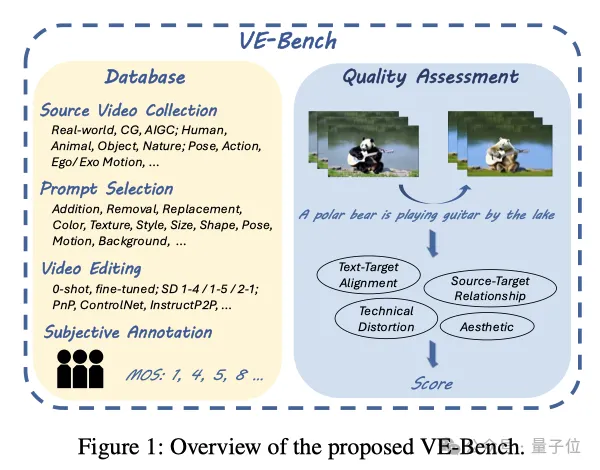
现在,北京大学MMCAL团队开发了首个用于视频编辑质量评估的新指标——VE-Bench,相关代码与预训练权重均已开源。
它重点关注了AI视频编辑中最常见的一个场景:视频编辑前后结果与原始视频之间的联系。
例如,在“摘掉女孩的耳环”的任务中,需要保留人物ID,源视频与编辑结果应该有着较强语义相关性,而在“把女孩换为钢铁侠”这样的任务中,语义就明显发生了改变。
此外,它的数据还更加符合人类的主观感受,是一个有效的主观对齐量化指标。
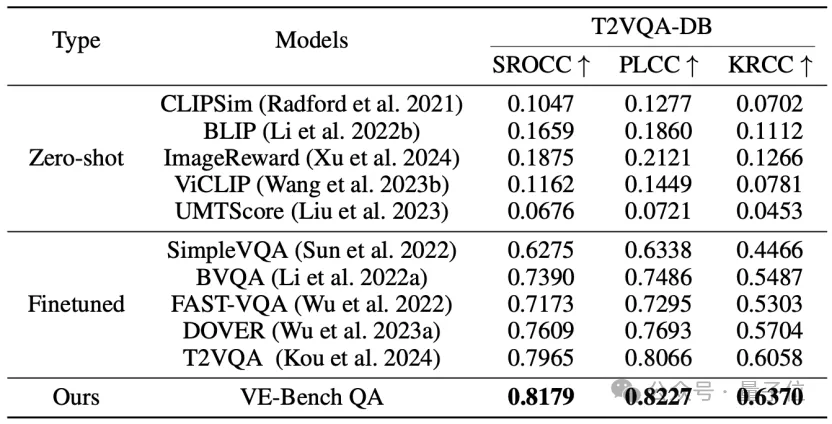
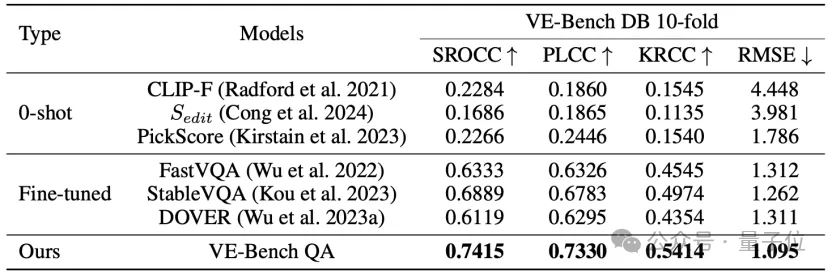
实验结果显示,与FastVQA、StableVQA、DOVER、VE-Bench QA等视频质量评价方法相比,VE-Bench QA取得了SOTA的人类感知对齐结果:
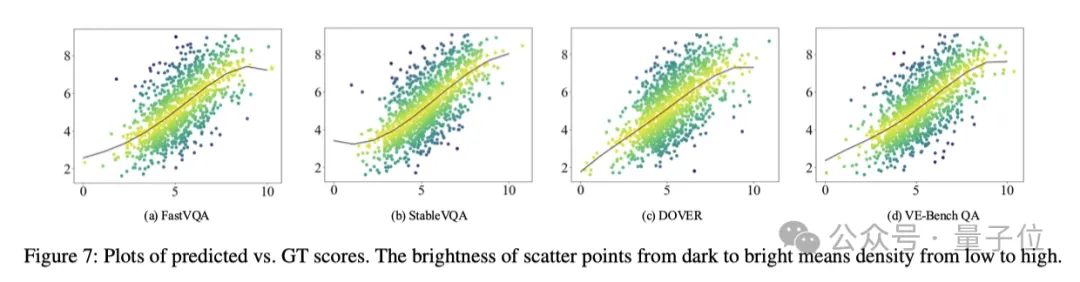
这到底是怎么做到的呢?
简单来说,VE-Bench首先从原始视频收集、提示词收集、视频编辑方法、主观标注4个方面入手,构建了一个更加丰富的数据库VE-Bench DB。
此外,团队还提出了创新的测试方法VE-Bench QA,将视频的整体效果分成了文字-目标一致性、参考源与目标的关系、技术畸变和美学标准多个维度进行综合评价,比当前常用的CLIP分数等客观指标、PickScore等反映人类偏好的指标都更加全面。
相关论文已入选AAAI 2025(The Association for the Advancement of Artificial Intelligence)会议。

为了确保数据多样性,VE-Bench DB除了收集来自真实世界场景的视频,还包括CG渲染的内容以及基于文本生成的AIGC视频。
数据来源包括公开数据集DAVIS、Kinetics-700、Sintel、Spring的视频,来自Sora和可灵的AIGC视频,以及来自互联网的补充视频。
来自互联网的视频包括极光、熔岩等常规数据集缺乏的场景。
所有视频都被调整为长边768像素,同时保持其原始宽高比。
由于目前主流视频编辑方法支持的长度限制,每段视频都被裁剪为32帧。
源视频的具体内容构成如下图所示,所有样本在收集时均通过人工筛选以保证内容的多样性并减少冗余:

参考过往工作,VE-Bench将用于编辑的提示词分为3大类别:
针对每个类别,团队人工编写了相应的提示词,对应的词云与类别构成如下:

VE-Bench选取了8种视频编辑方法。
这些方法包括早期的经典方法与近期较新的方法,涵盖从SD1.4~SD2.1的不同版本,包括需要微调的方法、0-shot的方法、和基于ControlNet、PnP等不同策略编辑的方法。
在进行主观实验时,VE-Bench确保了每个视频样本均由24位受试者进行打分,符合ITU标准中15人以上的人数要求。
所参与受试者均在18岁以上,学历均在本科及以上,包括商学、工学、理学、法学等不同的背景,有独立的判断能力。
在实验开始前,所有人会线下集中进行培训,并且会展示数据集之外的不同好坏的编辑例子。
测试时,受试者被要求根据其主观感受,并对以下几个方面进行综合评价:文本与视频的一致性、源视频与目标视频的相关度以及编辑后视频的质量,分数为十分制。
最后收集得到的不同模型平均得分的箱线图如下:
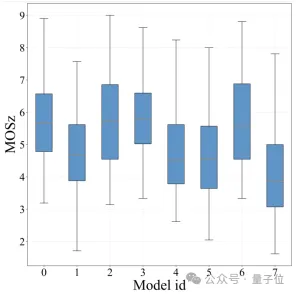
其中,横坐标表示不同模型ID,纵坐标表示Z-score正则化后的MOS (Mean Opinion Score)分数。橘红色线条表示得分的中位数。
可以看出,当前的大多数文本驱动的视频编辑模型中位数得分普遍在5分左右浮动,少数模型的得分中位数可以达到近6分,部分模型的得分中位数不到4分。
模型得分最低分可以下探到不到2分,也有个别样本最高可以达到近9分。
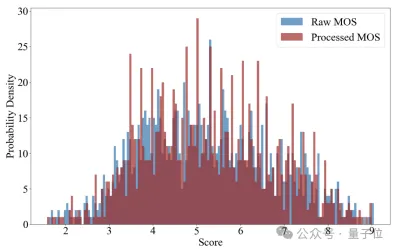
具体每个样本在Z-score前后的得分直方图如下图所示,可以看出极高分和极低分仍在少数:
在此基础上,团队进一步绘制了不同视频编辑模型在VE-Bench提示词上的表现:
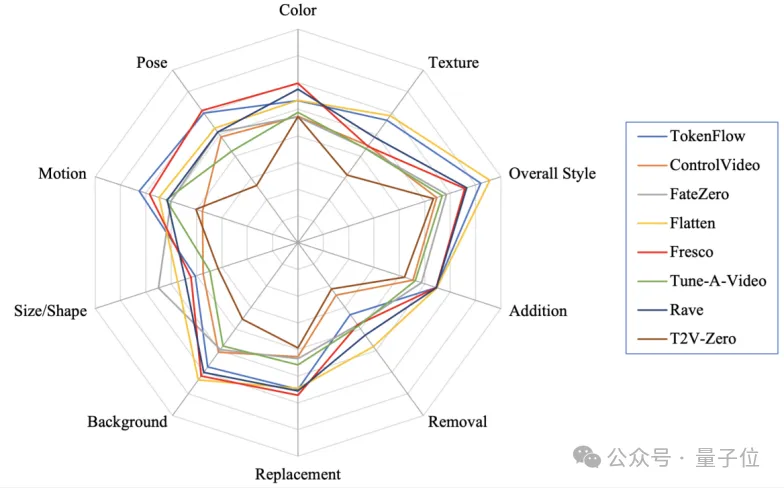
可以看出,目前的模型都相对较为擅长风格化指令,这可能是利用了SD在大量不同风格图片上训练的先验成果。
同时,删除指令相比于添加得分更低,因为它需要额外考虑物体或背景重建等问题,对模型语义理解与细粒度特征提取能力有更高要求。
现有模型都还不太擅长形状编辑。这方面FateZero模型表现较为优秀,这可能与它针对shape-aware提出的注意力混合方法有关。
在构建的VE-Bench DB的基础上,团队还提出了创新的VE-Bench QA训练方法,目标是得到与人类感知更加接近的分数。
下面这张图展示了VE-Bench QA的主要框架:
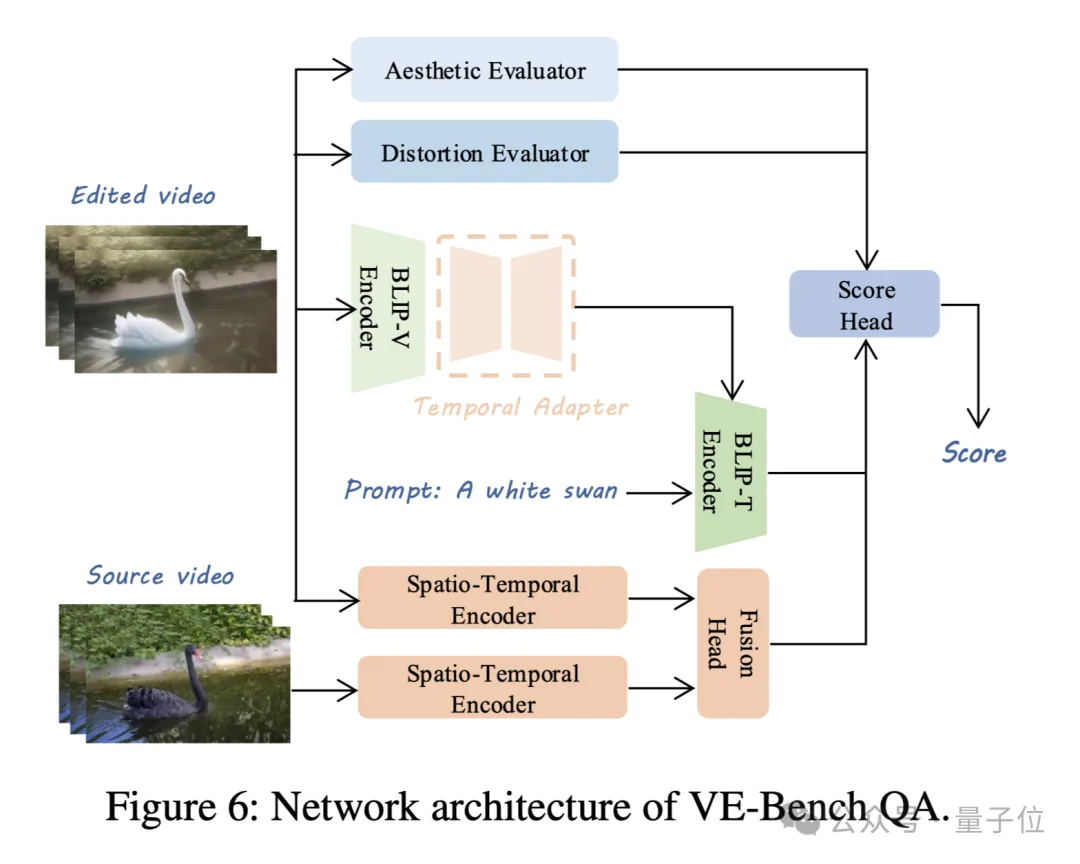
VE-Bench QA从3个维度对文本驱动的视频编辑进行评估:
为了衡量所编辑视频是否与文本有关,VE-Bench QA基于BLIP进行了有效的视频-文本相关性建模,通过在BLIP视觉分支的基础上加入Temporal Adapter将其扩展到三维,并与文本分支的结果通过交叉注意力得到输出。
为了更好建模随上下文动态变化的相关性关系,VE-Bench QA在该分支上通过时空Transformer将二者投影到高维空间,并在此基础上拼接后利用注意力机制计算二者相关性,最后通过回归计算得到相应输出。
VE-Bench QA参考了过往自然场景视频质量评价的优秀工作DOVER,通过在美学和失真方面预训练过后的骨干网络输出相应结果。
最终各个分支的输出通过线性层回归得到最终分数。
实验结果显示,VE-Bench QA在多个数据集上所预测的结果,其与真值的相关性得分都领先于其他方法:
论文链接:https://arxiv.org/abs/2408.11481
代码链接:https://github.com/littlespray/VE-Bench
文章来自于微信公众号“量子位”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
