# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

Pika 1.0正式上线后,拿到内测资格的网友们已经玩疯了!
有人用它生成了一个姜黄色头发女孩和她的姜黄色猫的短片。
以往,因为一致性的难题,用AI视频很难做出优秀的动漫作品。但是Pika 1.0,实在是太给人惊喜了!

更令人震惊的是,作者表示,这是100%用文本到视频生成的。

还记得半个月前,这家有斯坦福AI Lab博士创办的初创公司Pika,发布的第一个产品瞬间成为顶流。
不仅能够生成3D动画、动漫、卡通和电影,甚至可以实现风格转换、幕布扩展等重磅能力。

如今,许多网友到手体验后,纷纷觉得太哇塞了。
与此同时,Pika官方账号公布了自家的最新研究。这是Pika 1.0发布产品以来,这家公司首次对外披露技术细节。

最新研究中,提出了一种DreamPropeller方法,能够将文本到3D的生成速度提升4.7倍。

接下来,先来一起看看,广大网友们的创意。
比起Runway的Gen-2,Pika 1.0在让人物动起来时的一致性非常稳定。

Pika 1.0非常擅长动漫风格的动物,看看这些不同场景中的老鹰就知道了。
看得出,宫崎骏画风非常浓郁。

还有这种漫威风格的小人模型,让他们动起来真的像是「复仇者联盟」。

还有形单影只的白天鹅,在波光粼粼的湖中嬉戏,再游到岸边,好像在找回家的路。

就连美版「机器人总动员」动画的科幻风,呈现的也是淋漓尽致。

一朵含苞待放的花朵。

如下这个例子是Pika自己做的丛林中兔子士兵的电影级效果,并给出了提示(拿到内测资格的网友可试)
1. Cinematic, extreme close-up of a bunny soldier in a jungle, 3D rendering
2. Cinematic, back-view long shot of a bunny soldier exploring a giant carrot in the jungle, 3D rendering

疯狂动物城、狮子王、熊大熊二混版动画。

网友做了一个电影预告片,就连名字都想好了「金刚哥斯拉:新帝国」。


爱因斯坦和他的实验。

还有一位自称「AI级导演」做出的真人演示效果,简直绝绝子。
戴上帽子,穿上羽绒服,服饰的搭配与人的身体契合度,毫无违和感。

还可以把周边的物体变成松柏,还能把自己变成北极熊,简直可爱到爆。

还有「泰坦尼克号」重制版,女主Rose直接变成熊猫,和男主Jack在一起牵手的画风,你细品...

01:1
再来看个真人变身的效果,还有二次元小姐姐。

用AI「修改区域」,能够把所有背景,甚至包括主体的衣服能够换成一致的圣诞的风格。
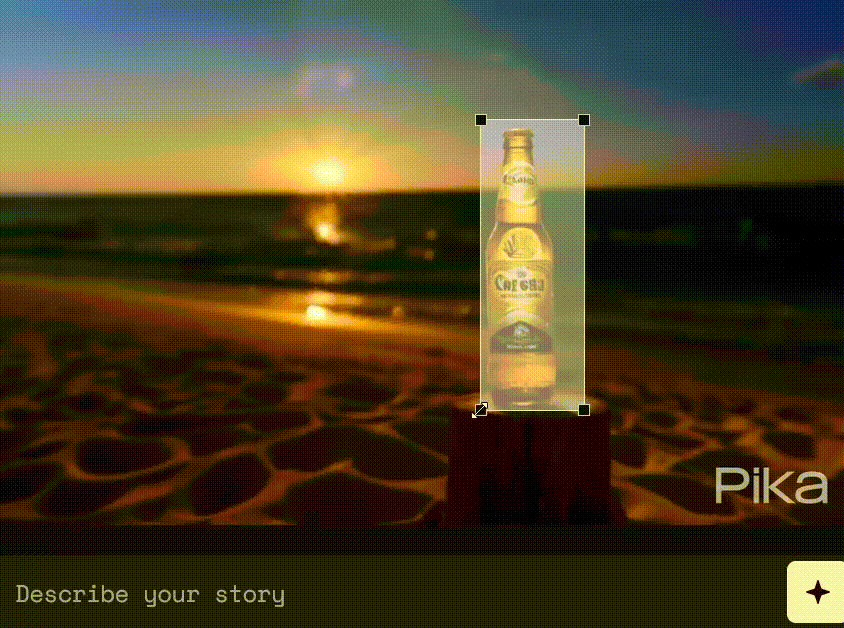
还有网友尝试了这一替换功能,把海边的啤酒,瞬间变成了可乐。
具体实现效果,Chase Lean给出了一个教程,只需要3步过程。
首先需要生成一个视频,先让Midjourney生成一张海边Corona啤酒的图片,然后将其做成视频。


第二步:单击「编辑」,然后单击「修改区域」。
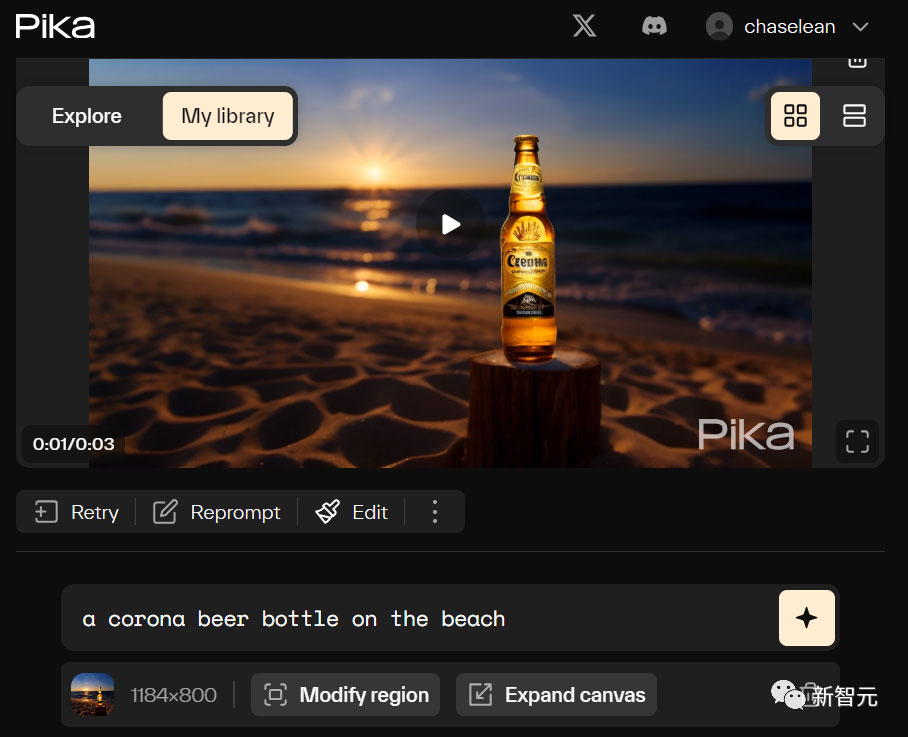
第三步,告诉Pika你想用什么来代替它,比如可口可乐。
图像画布扩展能力,其实我们也见到了许多像MidjourneyAI图像生成工具已经实现了。
而Pika 1.0不仅能开出脑洞,还能让画面动起来。
就看这雅典帕特农神庙,外画出的景色更加凸显这座建筑的壮观。


还有橄榄树、游览古建筑都能暗藏各种惊喜。

你可以录一段视频,Pika能够直接想象出背景。
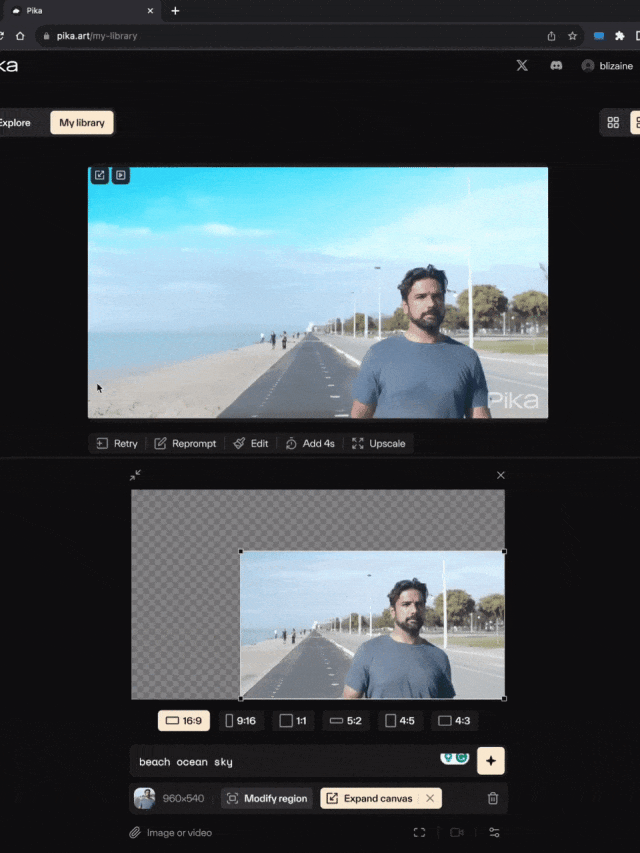
下面这个网友使用文本提示创建了第一个视频,然后扩展画布几次,获得了第二个视频。
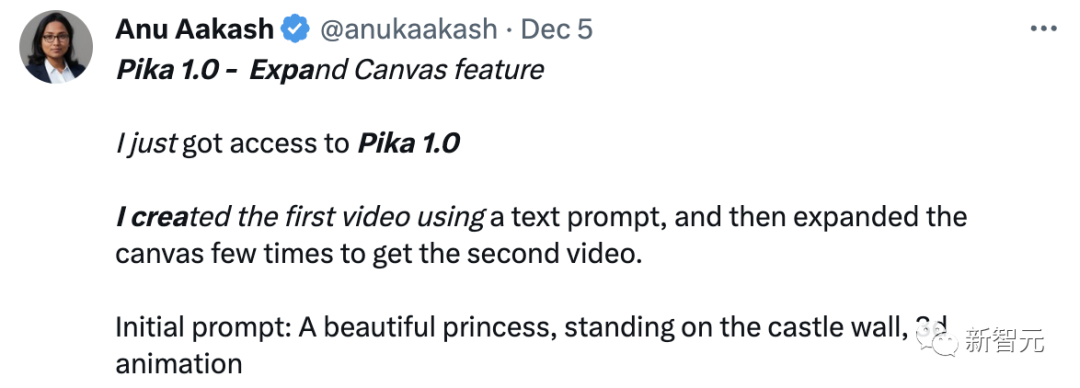
初始提示是:A beautiful princess, standing on the castle wall, 3d animation

还有网友做出了,演唱会级的音乐视频,不过不得不承认,还有些不足的地方。

01:2
Pika 1.0背后技术
看到这么多惊艳的效果,或许许多人更想了解一些关于Pika 1.0生成的技术细节。
这不,官方刚刚公布了一篇论文,是由斯坦福大学和Pika Labs联手共创。
以往,通过分数蒸馏,比如DreamFusion、ProlificDreamer等模型,进行文本到3D的生成质量虽高,但运行时间可能长达10个小时。
最新论文中,研究人员提出了一种基于分数蒸馏的加速方法——DreamPropeller,能够将现有方法的速度提高4.7倍。

论文地址:https://arxiv.org/pdf/2311.17082.pdf
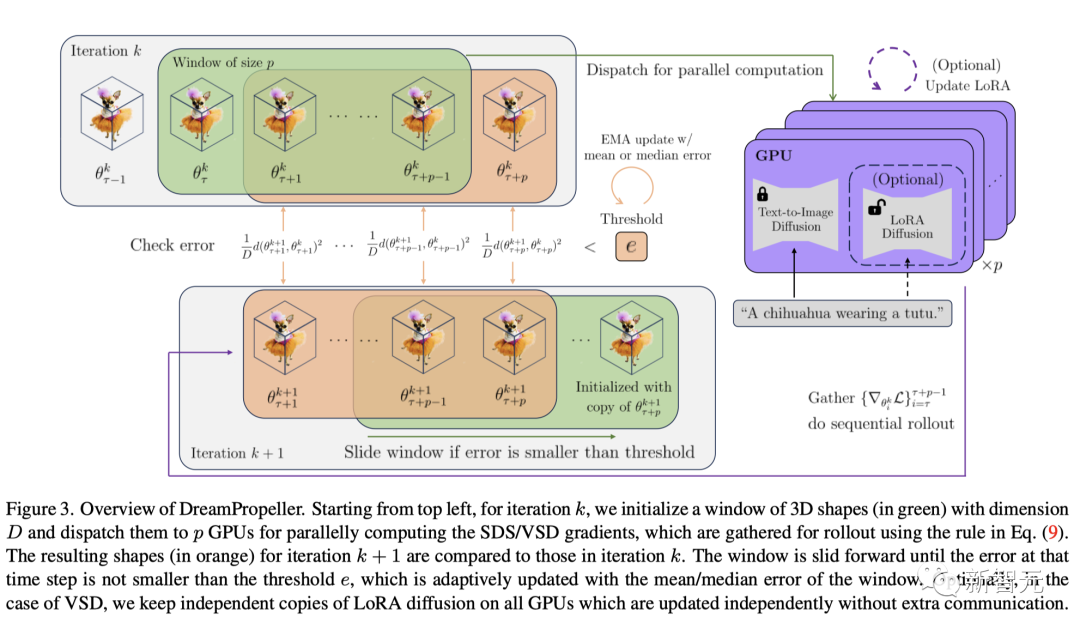
DreamPropeller整体架构如下图所示。
在每次迭代(k次)的开始,初始化一个由3D形状(用绿色表示)组成的窗口,然后,这些形状被分发到p个GPU上进行并行计算,在GPU上并行计算形状的SDS/VSD梯度。
然后根据公式 (9) 中的规则收集这些梯度,并使用这些梯度对形状进行更新。
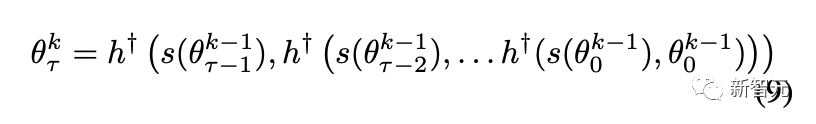
窗口向前滑动,直到该时间步的误差不小于阈值e,阈值e根据窗口的平均/中值误差进行自适应更新。
另外,在VSD的情况下,研究人员会在所有GPU上保留LoRA扩散的独立副本,这些副本会独立更新,无需额外通信。
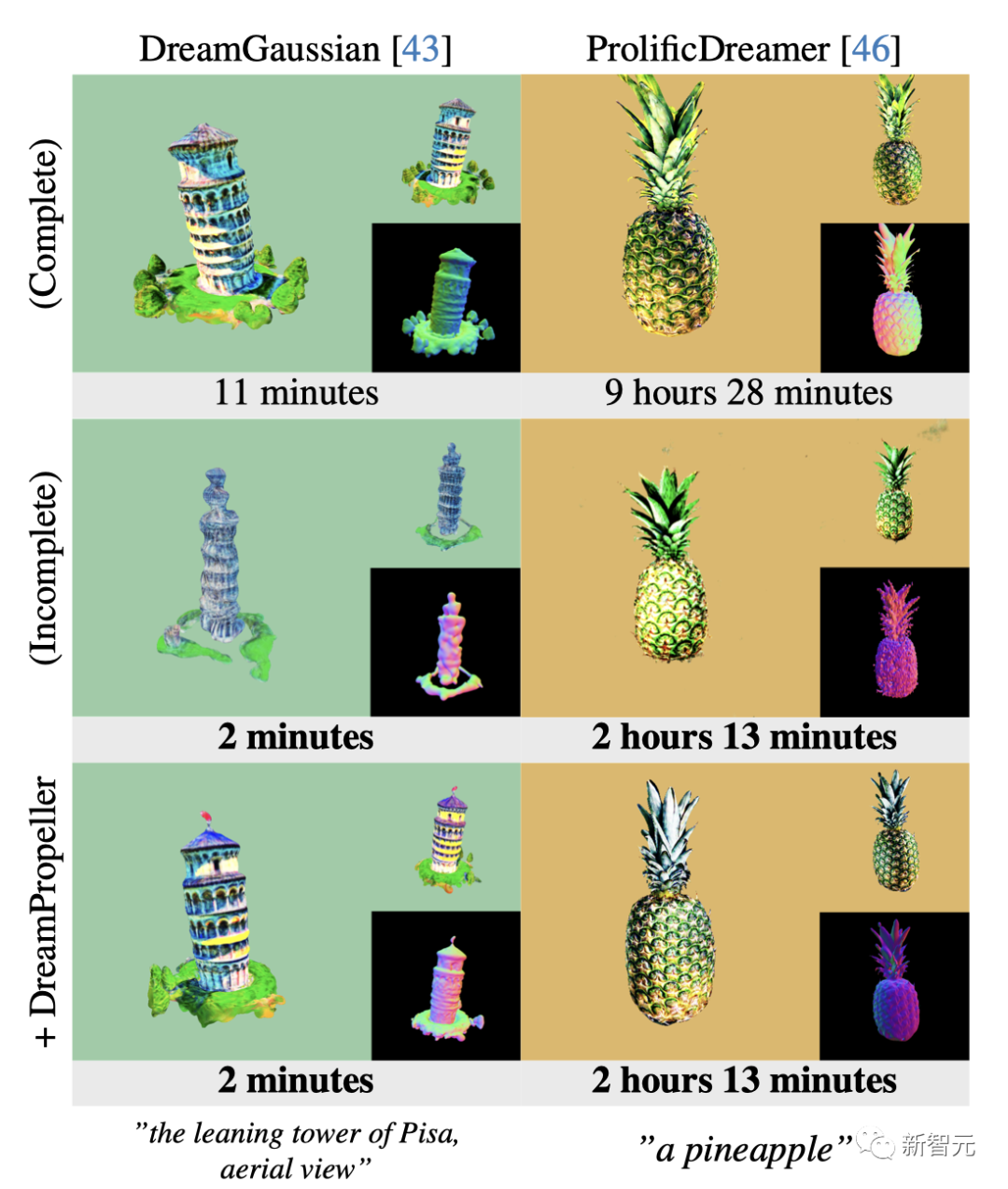
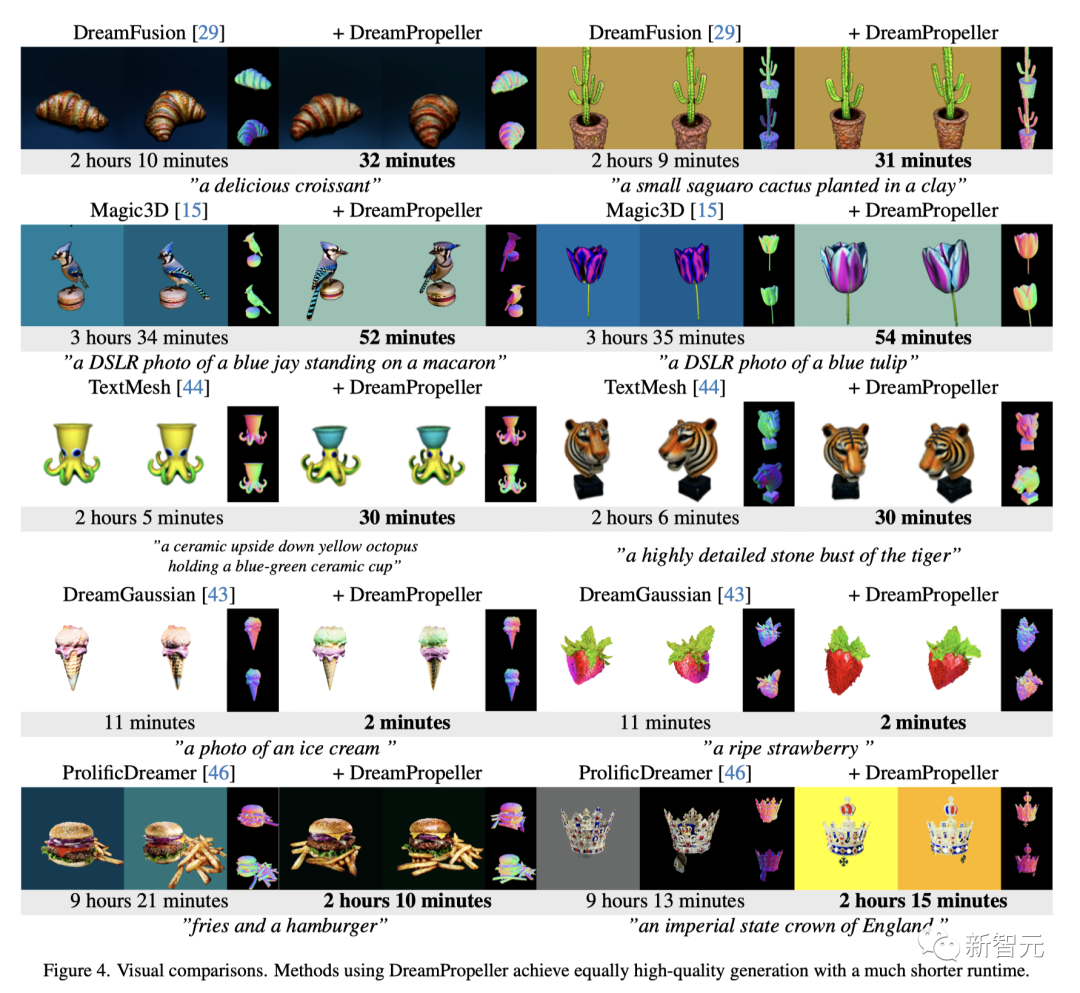
如下是应用DreamPropeller的代表性示例。
最新框架以并行计算换取速度,在保持生成质量的前提下,应用于DreamGaussian和ProlificDreamer时,速度提高了 4 倍以上。
在DreamPropeller完成时,基线版本的外观和几何效果明显较差。
如下是与其他模型的可视化比较。使用DreamPropeller的方法能以更短的运行时间实现同样高质量的生成。
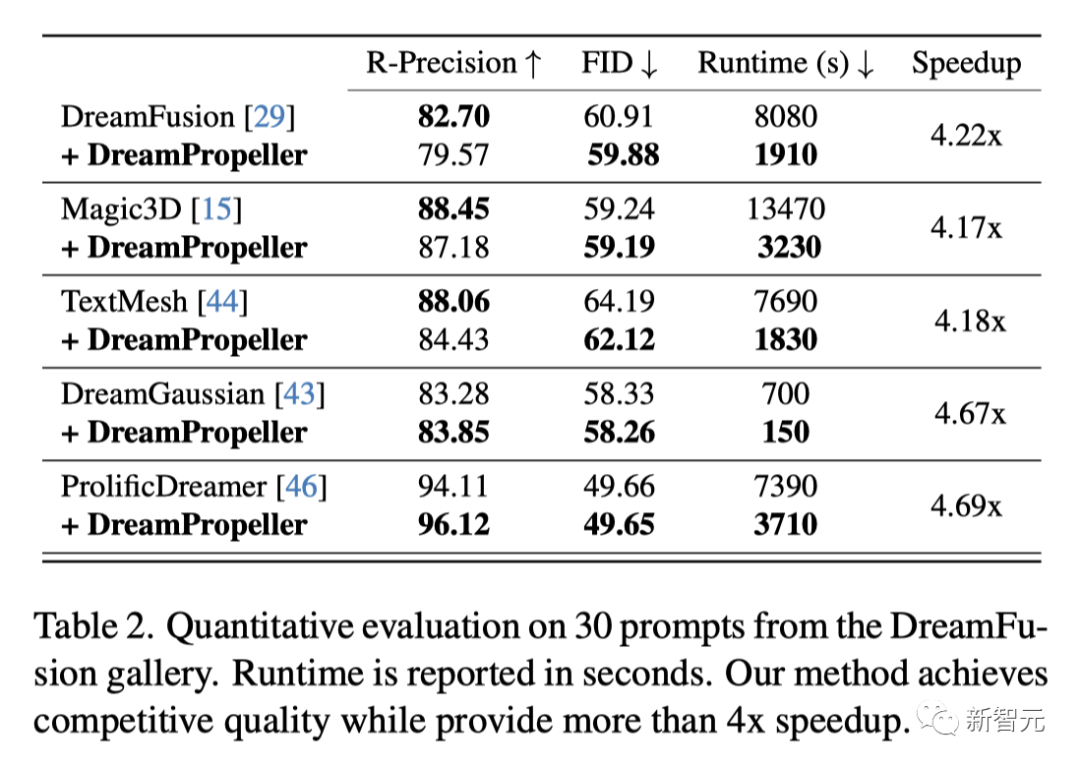
对DreamFusion图库中的30个提示进行量化评估。运行时间以秒为单位。最新研究的方法达到了具有竞争力的质量,同时速度提高了4倍以上。
对于Pika 1.0的诞生,让全网热血沸腾,而它或许成为下一个视频生成的顶流。
有人统计了Discord上最大的人工智能产品,以及它们在平台范围内的规模。
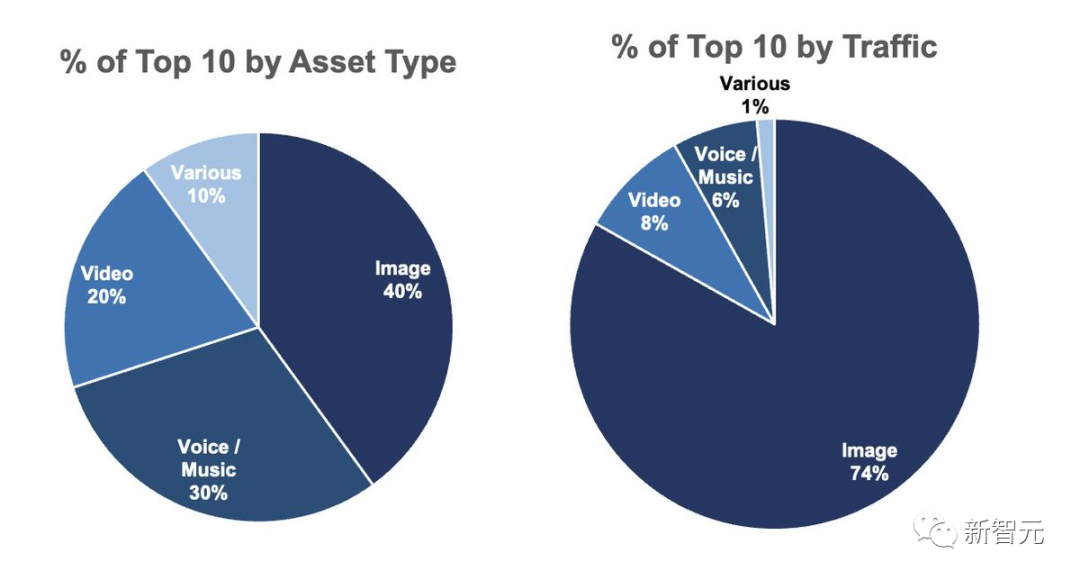
如下是按邀请页面流量排序的十大人工智能应用程序,Midjourney位列第一,Pika排在第二。
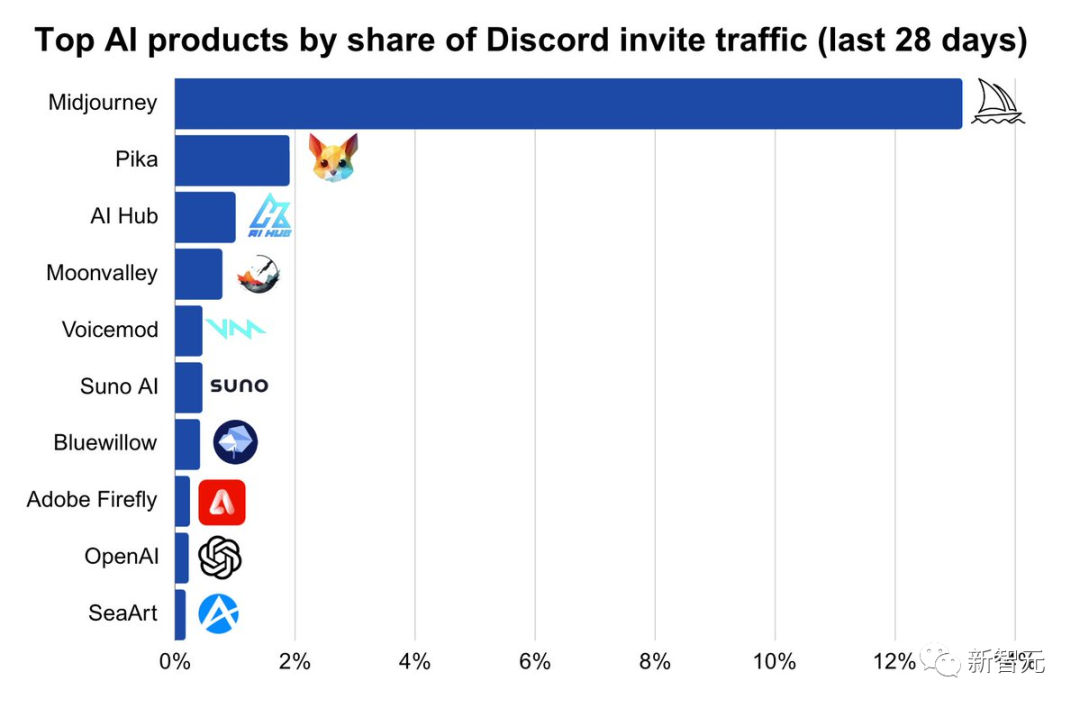
在排名前十的应用程序中,有4个是图片生成应用程序,3个是语音/歌曲生成应用程序,2个是视频生成应用程序。
按流量计算,图片占了前10名流量的74%,其次是视频8%,语音/音乐6%。
参考资料:
https://twitter.com/pika_labs
文章来自于微信公众号 “新智元”,作者 “桃子”



