# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着 o1、o1 Pro 和 o3 的成功发布,我们明显看到,推理所需的时间和计算资源逐步上升。可以说,o1 的最大贡献在于它揭示了提升模型效果的另一种途径:在推理过程中,通过优化计算资源的配置,可能比单纯扩展模型参数更为高效。
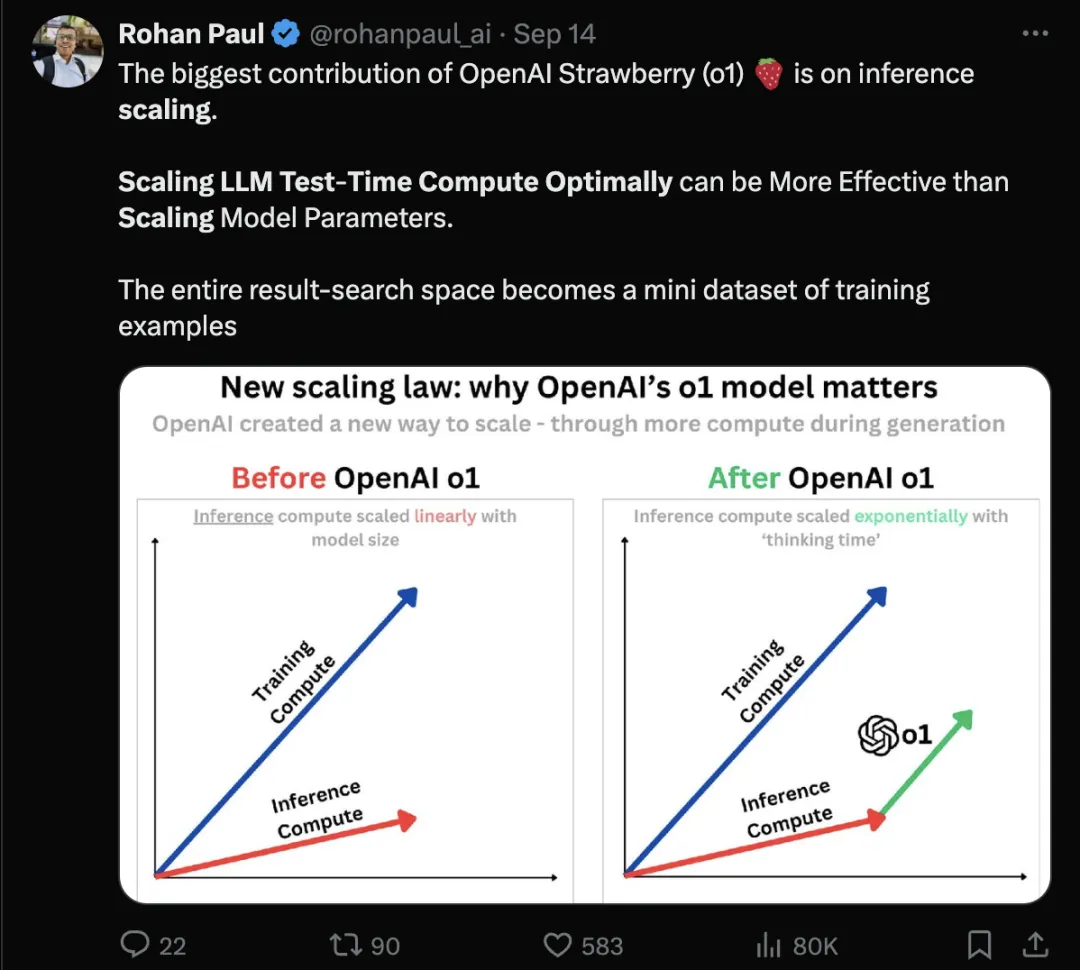
上述的结论不是凭空提出的,在谷歌八月发表的一篇论文中通过系统全面的实验,进行了详细的论证。同时论文中对于如何验证最佳结果给出了详细的分析。
论文标题:
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
论文链接:
https://arxiv.org/pdf/2408.03314
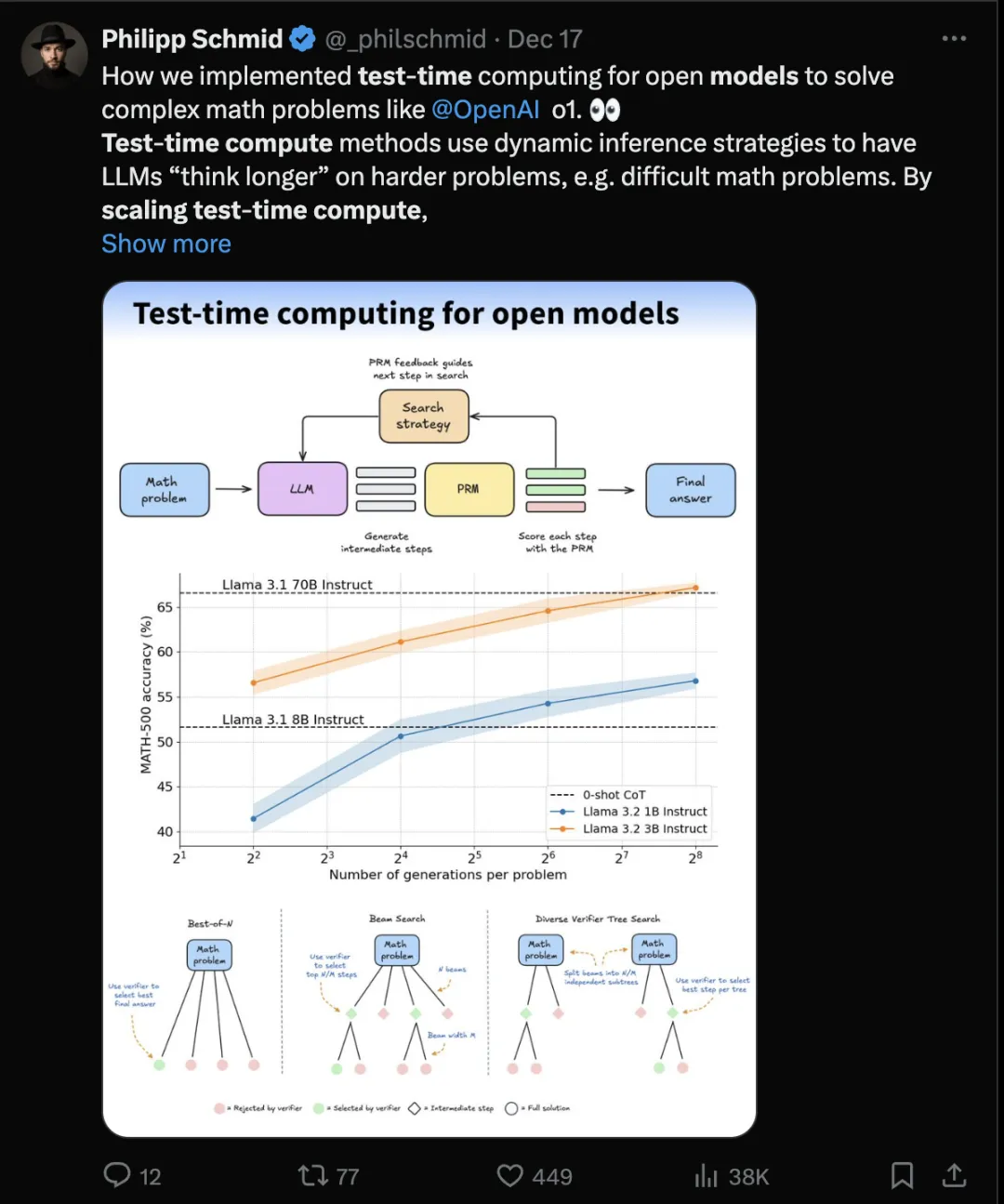
相比通过增量预训练或者微调的方式,增加推理资源更加简单直接,不需要大量的数据和成本,减少了训练微调带来的试错成本,对于快速的效果验证是多么理想的方案。
我们知道大模型的生成过程是 token by token 的生成方式,假如词表大小是 V,需要生成的长度序列是 L,生成过程可以看作是从 V*L 的矩阵中每一列选择一个元素的过程,如下图的红色色块代表的序列,至少有一条正确的路径。
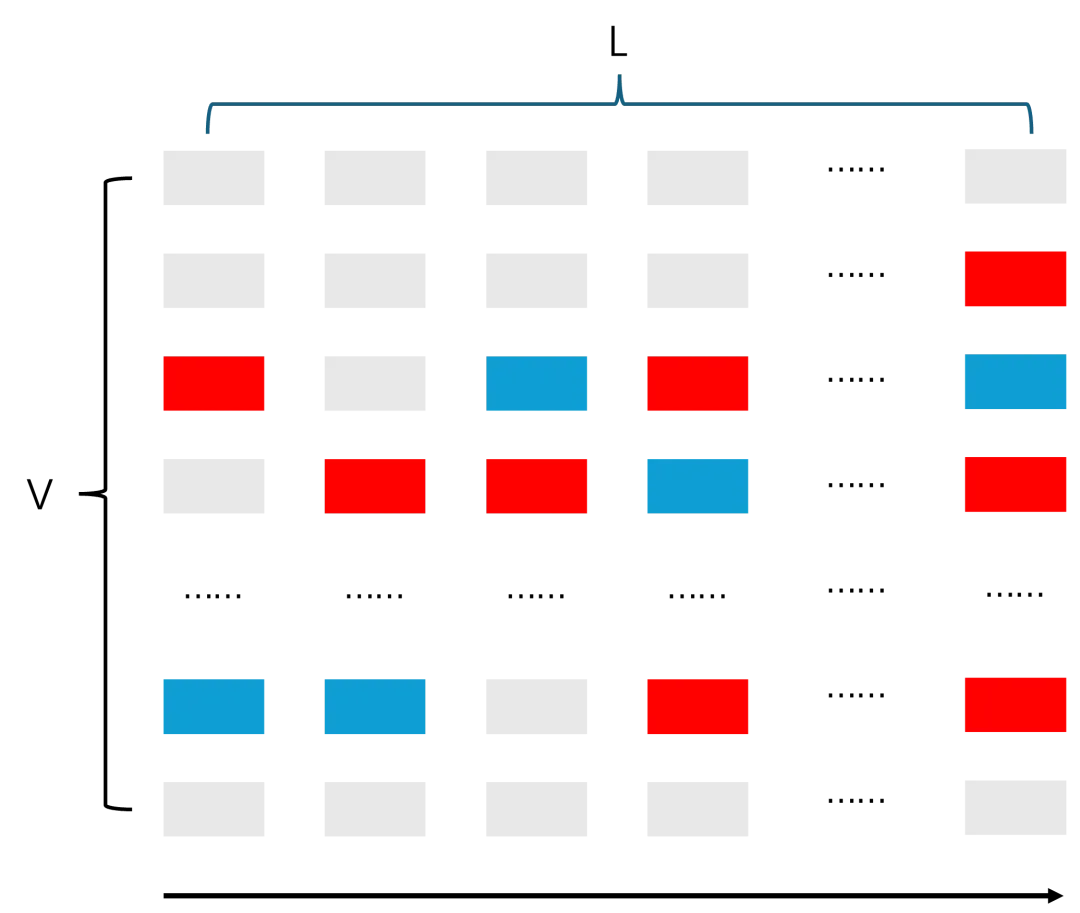
这种情况下,大模型的一次生成过程,等同于采样一条上图中的序列。随着采样次数的增加,那么采样的结果集合中包括正确序列的概率一定是增大的,极限状态下,采样所有的组合方式,那么一定有正确答案。
基于这个想法,斯坦福、Deepmind、剑桥在下面的论文给出了详细的实验分析。
论文标题:
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
论文链接:
https://arxiv.org/pdf/2407.21787
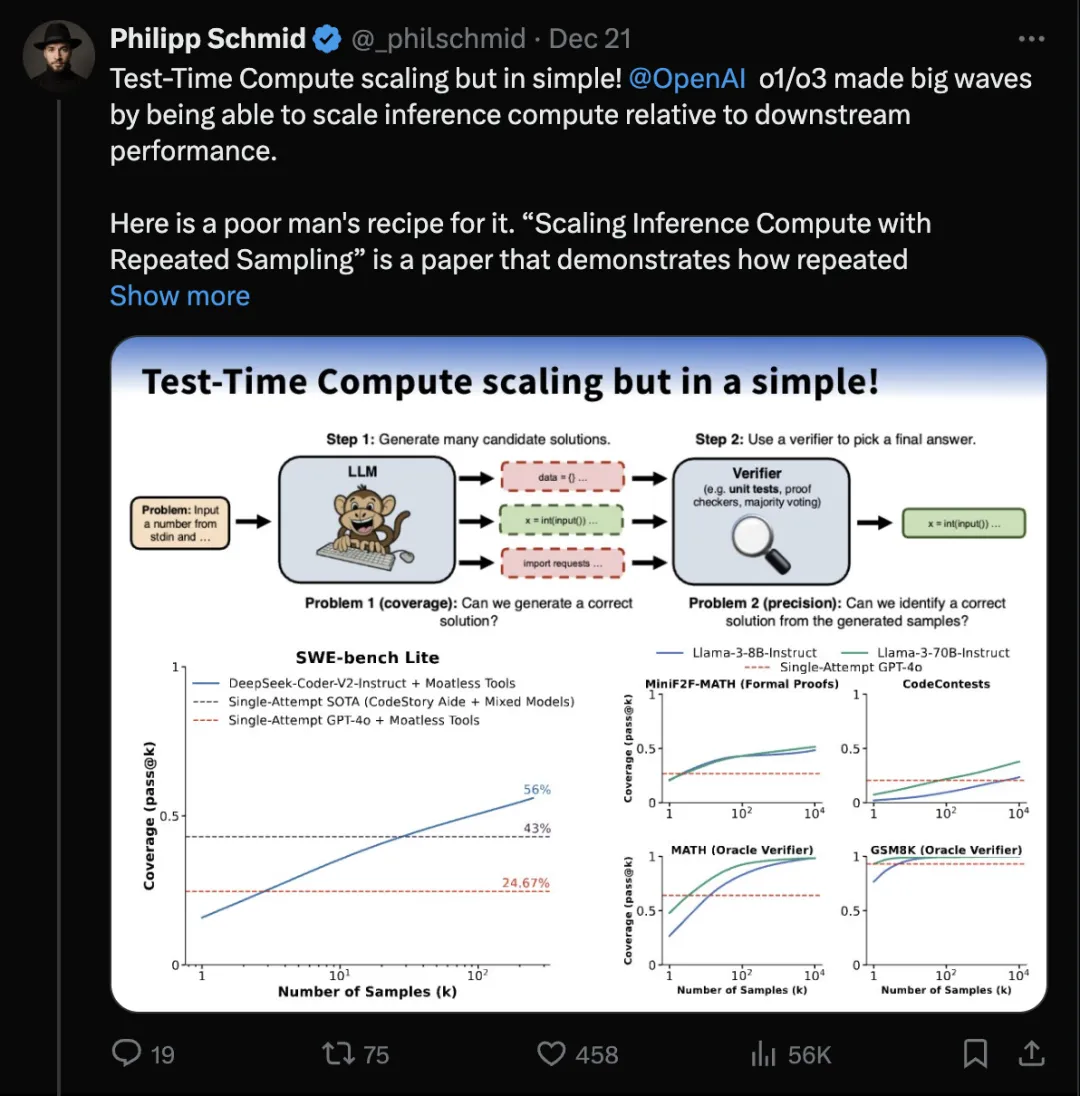
通过重复采样的方式,能够获取到足够多的候选答案,从而提升模型的性能。例如,论文提到 DeepSeek-Coder-V2-Instruct 在 SWE-bench Lite 数据集上,通过250 采样能够从 15.9% 的准确率提升到 56%,远超 SOTA 的 43%。
为了验证方法的有效性,那么有两个问题需要考虑:
为了解决这两个问题,论文中定义了两个指标:
为了便于实验的验证,在论文中,只使用了 GSM8K、MATH、MiniF2F-MATH、CodeContests 和 SWE-bench Lite 数据集,这些数据集能够通过自动化的方式验证答案的有效性。
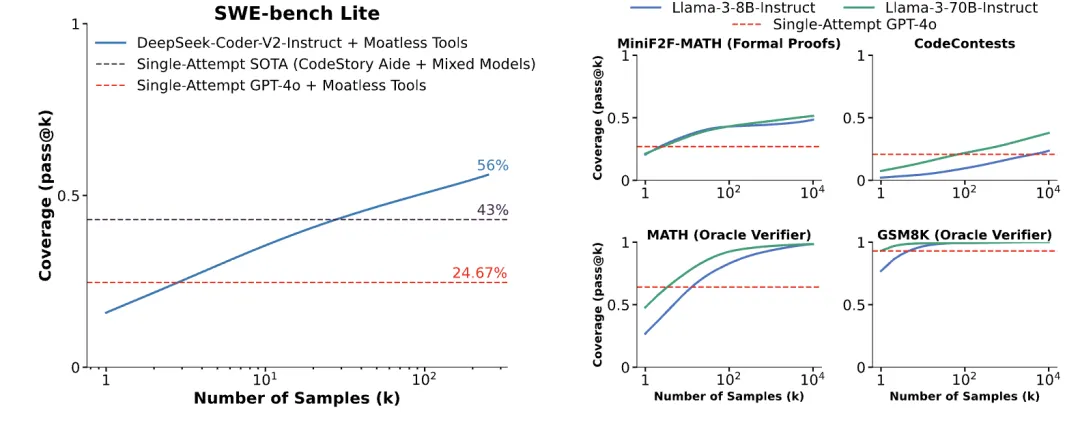
从论文的实验结果来看,重复采样的方法无疑是成功的,随着采样次数的增多,覆盖率得到明显的提升。但我们可能有疑惑:这个方法是否适用于所有的大模型?这个答案是肯定的,论文中给出了这个问题的实验结果。
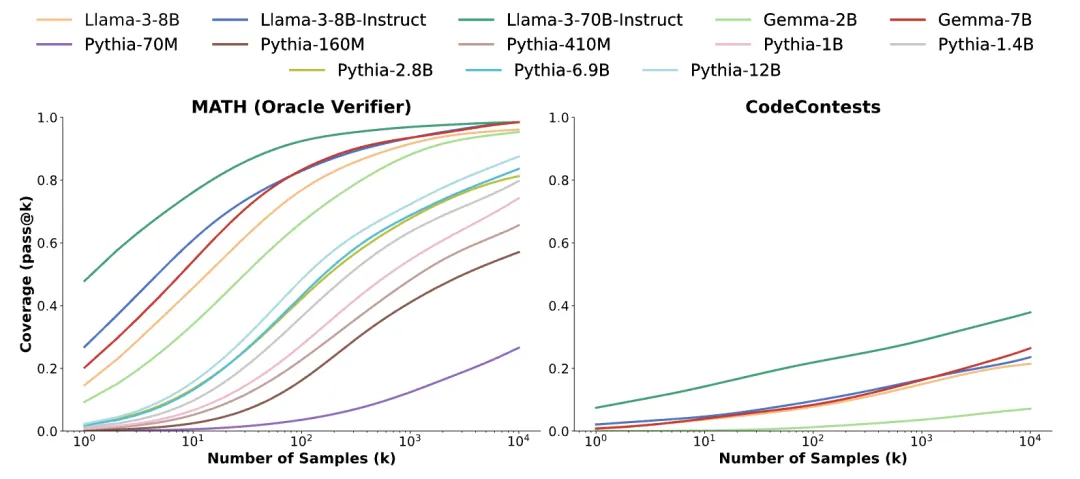
重复采样能够在各种模型规模(70M-70B)、模型家族(Llama、Gemma 和 Pythia)以及不同的后训练水平(基础模型和指令模型)中实现一致的覆盖率提升。
从前面的分析看,重复采样是以推理成本的增加为代价,提升大模型的效果,那增加的成本是否具备性价比?论文中通过定义 FLOPs 来衡量成本,定义如下:

但遗憾的是,在论文的实验中,并没有得到一致的结论:单独检查 FLOPs 可能是一个粗略的成本指标,它忽略了系统效率的其他方面。特别是,重复采样可以利用大批量和专门的优化来提高相对于单次尝试推理工作负载的系统吞吐量。
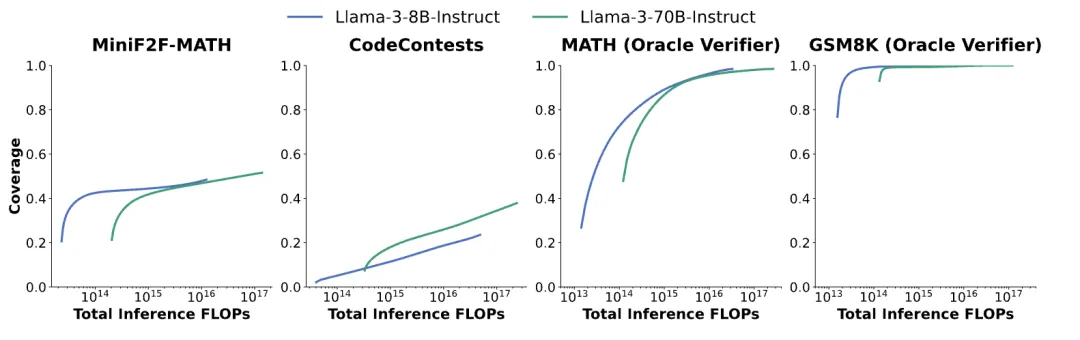
以推理FLOP的数量衡量,以及Llama8B-Instruct和Llama-3-70B-Instruct的覆盖率。我们看到理想的模型大小取决于任务、计算预算和覆盖要求
从上图可以看出,在相同 FLOPs 下,除了 CodeContests 任务外,8B 的模型效果更佳。而 CodeContests 任务上 70B 总是优于 8B 的模型。重复采样带来的效果提升需要结合任务的复杂程度来看。
不过,从实际落地的角度出发,当不具备大量显卡资源下,以推理耗时成本提升效果也是不错的选择。毕竟,不考虑资源的落地就是耍流氓。
在推理过程中,增加采样次数会提高覆盖率,但也会显著增加计算成本(FLOPs)。论文希望通过缩放定律找到性能与计算成本的最优平衡点。
我们知道,传统的模型缩放定律(Scaling Laws)主要研究训练阶段的性能随计算预算的变化规律。而论文通过研究推理阶段的重复采样,希望揭示推理计算量如何影响模型的性能表现(如覆盖率、任务解决率)。
希望通过缩放定律帮助回答:
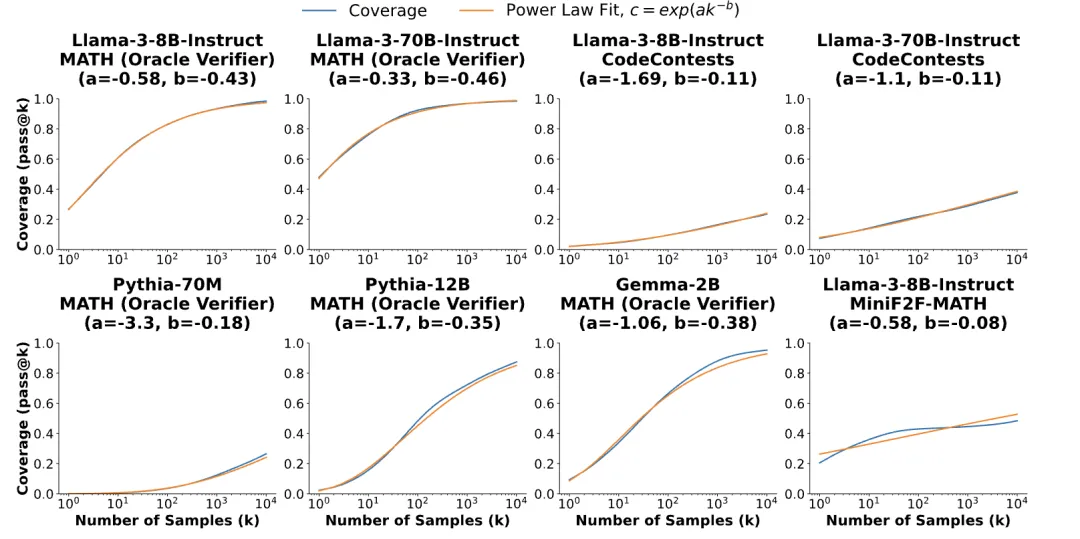
对于大多数任务和模型,覆盖率和样本数量之间的关系可以用指数幂定律建模。但是,如MiniF2F-MATH上的Llama-3-8B-Instruct稍微有点差异,这可能和模型以及具体任务场景有关。
基于上面的讨论,我们可以看出,推理阶段的重复采样能够有效提升覆盖率,也就是获得备选答案,但是,从所有的候选解中如何选出正确的答案呢?
可以类比传统的搜索引擎,用户搜索“一点点奶茶”,召回阶段会得到大量的候选结果,排序阶段是如何将“一点点”这个品牌排序到第一位,这也就是验证器要干的事。
论文设计了三种验证器的实现逻辑:
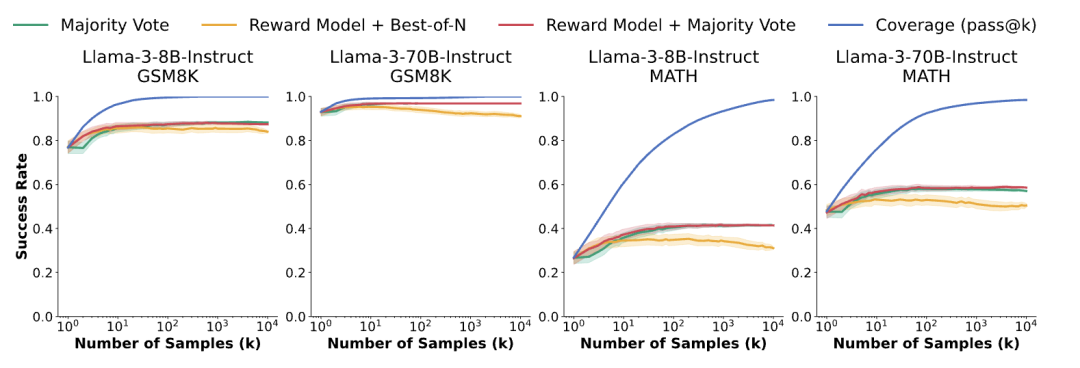
通过实验结果,我们可以看出,重复采样方法带来的效果提升,很大程度受限于验证器的性能,覆盖率的提高无法直接转化为最终的任务成功率,且验证器在样本数量增加时表现出性能饱和。\

这是谷歌的 alpha 代码(前文提到的谷歌 8 月份提出的论文)。结合可靠的验证器,你可以将域性能扩展到疯狂的水平。
当然,也有网友表示这个方法更像是 O3 的简化版本。
对于提升模型性能,大多数的选择是调整模型,包括预训练、微调和强化学习等,在训练阶段增加成本。重复采样给了我们一种新的思路,不改变模型的情况下,通过增加推理耗时,也能得到很好的结果,但效果的提升强依赖于验证器的性能。
世间难得双全事,解决了一个问题,总会出现另一个问题,但这不就是探索嘛,期待在这个方向上的进一步的突破。
文章来自微信公众号“夕小瑶科技说”,作者“张其来”




【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
