# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型的出现,成了AI第三次浪潮的新拐点。
正值“Scaling Law是否撞墙”热议之际,北京智源人工智能研究院院长王仲远表示:
看过去七、八十年,每一次新的科技浪潮背后都有一些本质规律,即随着模型参数、训练数据及计算能力提升,模型效果也会有巨大提升。
也就是说,如果拉长时间维度,其实Scaling Law在人工智能发展领域中一直起着作用。
此外,在本次量子位MEET 2025智能未来大会上,他还介绍了智源在过去6年里,建立了一支最早在国内从事大模型研发的顶尖团队,并且从2020年10月开始,就成立了技术攻关团队来持续推动大模型技术研发探索。
至于大模型未来的发展方向,在他看来,除了文本数据,世界上还存在大量的图像、音频、视频等多模态数据。如何激发这些数据中的智能,是未来大模型研究的重要方向。
原生统一的多模态大模型才能更好支撑产业落地应用,实现人工智能对世界的感知、理解和推理。

为了完整体现王仲远的思考,在不改变原意的基础上,量子位对演讲内容进行了编辑整理,希望能给你带来更多启发。
MEET 2025智能未来大会是由量子位主办的行业峰会,20余位产业代表与会讨论。线下参会观众1000+,线上直播观众320万+,获得了主流媒体的广泛关注与报道。
以下为王仲远演讲全文:
大家上午好,我是来自北京智源人工智能研究院的王仲远。
当下我们正处在人工智能七八十年历程的第三次浪潮新拐点,尤其是出现了大模型。
以2023年大模型出现前后做一个分界线,可以认为过去属于弱人工智能,也就是针对特定的场景,特定的任务,收集特定的数据,训练一个模型,然后在特定场景解决问题。
像AlphaGO,能够战胜世界围棋冠军,但是无法直接用来解决医疗问题,解决无人驾驶问题等。
在大模型之后,弱人工智能开始向通用人工智能方向转变,从专精尖的模型到通用模型,开启了一个新的时代。由于能力还在不断提升的过程中,所以我们还会觉得大模型依然不够好用。
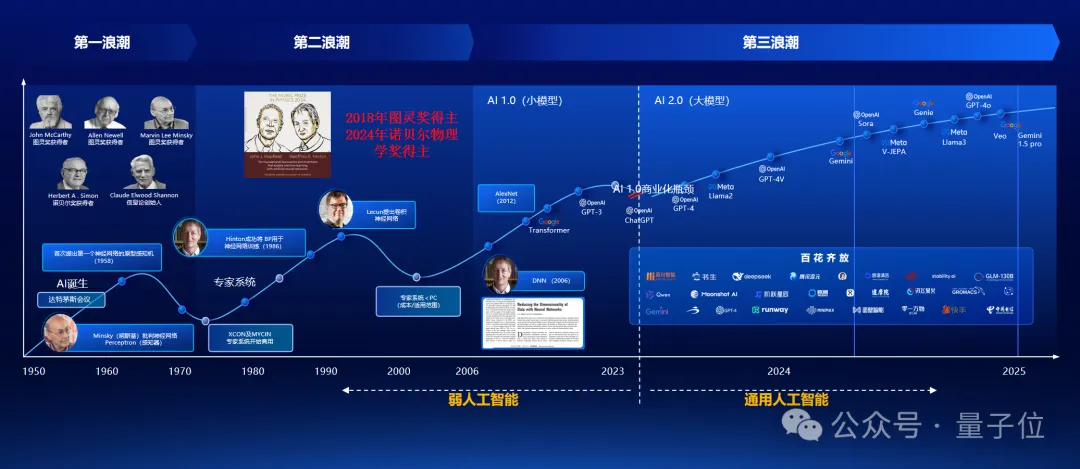
但是可以看到,过去七八十年每一次新的浪潮背后都有的本质规律:模型参数、训练数据以及计算能力的提升,会带来模型效果的巨大提升,这就是反复讨论的Scaling Law。
最近关于Scaling Law是否失效,有很多争论。
如果时间维度足够长,会发现Scaling Law一直都在整个人工智能的发展历程中不断发挥作用。至于最近谈到的Scaling Law已经失效,一个很大原因是数据、算力,这些支撑Scaling Law发展的要素出现瓶颈。
通用人工智能时代的到来,对各行各业都有非常多的影响。
今年以来,大模型开始加速落地。
如果说过去两年,中国依然在不断地追基础模型的能力,那么现阶段国产模型的能力已经接近GPT4了,足以支撑更多的应用落地,因此可以预期在明年会有越来越多基于大模型的各种场景应用的诞生。
智源研究院是第三次浪潮中在北京成立的一家非营利性质的新型研发机构。
在过去六年时间里建立起了一支非常顶尖的科研团队,科研人员60%有博士学位,30%有海外教育研究背景和经历。正是因为有这样一支年轻有活力、有国际视野的团队,智源研究院在国内最早开始了大模型的研发。
而且智源研究院在2020年10月就成立了一支百余人的技术攻关团队,专做大模型研发。并在2021年分别发布了悟道1.0、悟道2.0,2023年发布悟道3.0系列。

ChatGPT发布之后,产业界开始关注大模型,智源实际对国内大模型创业公司做了非常大的贡献,包括孵化了一些公司,转化了一些技术。就在今年智源大会上,头部大模型公司对智源在过去这些年的贡献也给予了充分肯定。
面向未来,大模型还远没有到发展的尽头。百模大战,很大程度上依然聚焦于大语言模型,Scaling Law在大语言模型上开始放缓的一个非常重要的原因是文本数据消耗殆尽。
ChatGPT后的o1,想要通过Post-Training(后训练)的方式进一步激发大语言模型的智能。
面向未来看更多的技术发展趋势,可以看到除了文本数据,还存在着大量的图像、音频、视频等多模态数据,这些数据如何进一步激发大模型的智能,是一个非常重要的研究方向。
我们知道现阶段有多模态理解的模型,也有多模态生成的模型。像Sora是Diffusion-Transformer的技术路线,多模态理解的模型基本上还是以大语言模型为核心,把不同模态的视觉信号等往语言模型上做映射。
我们认为原生统一的多模态大模型才能更好支撑产业落地应用,实现人工智能对世界的感知、理解、推理。如果与真实物理世界的硬件结合就是具身智能,与微观世界的生命科学结合就是AI for Science,这一切最终都推动整个AGI时代的到来。
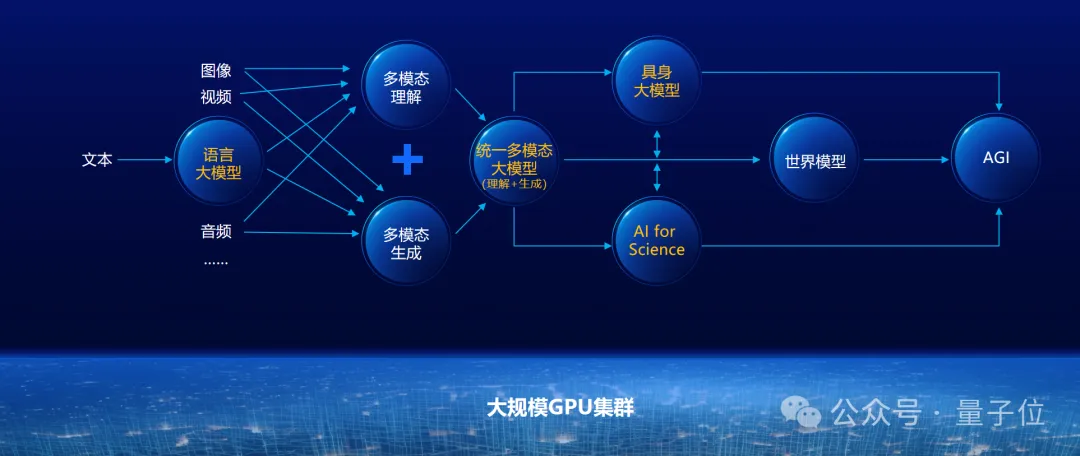
过程中,智源研究院会针对一些产业界的共性问题,进行科研层面的解决,以始终引领未来大模型的发展,支撑产业发展方向。
大模型一直有一个非常大的痛点就是幻觉。
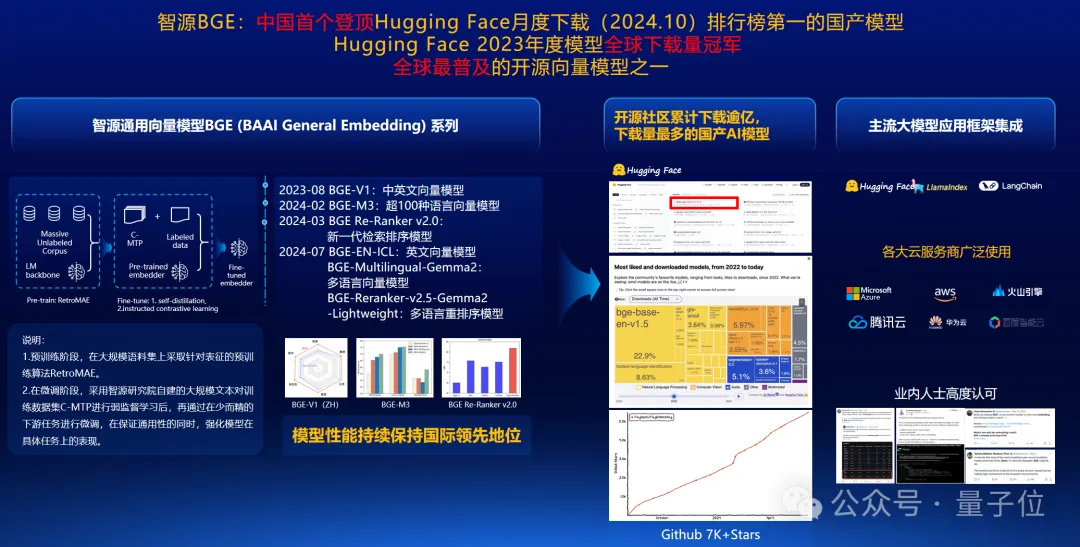
去年,我们发布的通用向量模型被广泛用在检索增强中,在过去的两年里,BGE已经成为全球知名开源平台Hugging face上120多万个开源AI模型中下载量最高的模型(超过20%)。
不仅在社区里广受欢迎,而且主流的云厂商平台集成了BGE模型。因为我们完全开源,也允许商用。这就是智源研究院对产业界的支撑。
前沿探索中,智源一直在开展视觉和多模态方向的研究。
当前阶段,不同模态的模型依然采用不同的技术架构,它能够在局部上展现出非常好的效果,但从长期的技术发展或最终落地来讲,还是会面临很多挑战。
所以我们一直都在挑战一个终极形态的技术路线——将所有的模态,包括理解和生成统一。
今年10月正式发布的Emu3原生多模态世界模型,我们将视觉信号和所有文本变成了token,通过类似大语言模型的训练架构训练出了一个统一的原生多模态大模型。

视频所展现出来的所有关于图像的生成、图像的理解,视频的生成、视频的理解都是基于一个基础模型。具体来说,基于Autoregressive技术路线的Emu3 ,还能够做视频的续写,以及对于复杂图像、视频的理解。
我们已经将Emu3基础模型以及微调的模型在开源社区开源,大家都可以使用。对比各种开源模型,可以发现Emu3在图像生成、视频生成以及图像视频的理解上都做得非常不错。
我们的技术报告和模型发布之后,国际同行也对Emu3给予了非常高的评价。
事实上,统一的多模态大模型对于最终落地各行各业有非常大的帮助。因为在真实的工业场景、医疗场景、教育场景,其实存在着大量的多模态数据,不仅仅是文本的数据。当人工智能模型进入物理世界,跟硬件结合,更需要的还是多模态模型。
面向未来,我们正在研发具身智能一脑多体的具身大模型。
具体来说,具身大脑能够更好地理解世界规律,跟环境交互,能够做好规划、决策的任务;小脑能够实现跨不同的本体,进行整个本体的控制,灵巧手能够做更加精细化的操作。
在规划决策上,o1能够不断反思思考,在具身智能上显得尤其重要。我们有快系统和慢系统,在真实世界交互中,对于某一个决策能够反思,即执行失败了能纠正自己的行为非常重要。
当然,我们也要意识到具身智能处在非常早期的阶段,有非常多的技术依然亟待突破,尤其是泛化能力。比如泛化抓取、泛化操作,以及不同自由度操作的能力,包括具身导航的泛化导航能力等。
而智源在具身智能上也有一些进展。
在今年两会央视连线智源研究员时,研究员说“我渴了”,机器人的机器手臂上的摄像头叠加多模态大模型,它就能够去理解、思考、抓取透明物体。

我们也将这样的技术用在了所孵化的一家企业(北京银河通用)的第一代机器人上,它能够在零售场景下理解人类语言,做一些抓取工作。
当然我们也深刻意识到,具身智能依然处在非常早期的阶段,因此我们现在也在不断加强和高校、院所、企业之间的合作,从数据采集到模型,包括大脑模型、小脑模型、端到端模型,到最终场景的落地应用。
最后,非常欢迎各个企业、学校能跟智源研究院一起推动具身智能技术的发展。
文章来自于“量子位”,作者“编辑部”。




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
