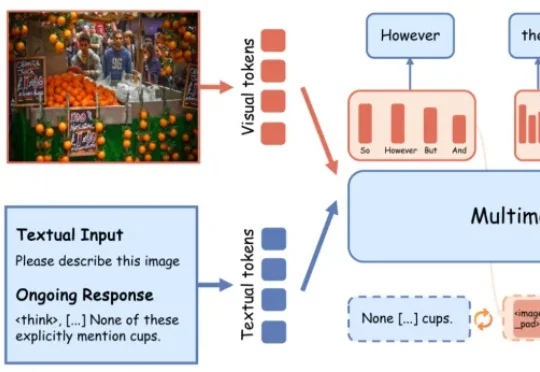
OpenClaw的风刮到了多模态生成,6B小模型超越Nano Banana 2!
OpenClaw的风刮到了多模态生成,6B小模型超越Nano Banana 2!近日,上海人工智能实验室联合南京大学、香港中文大学及上海交通大学,将OpenClaw的成功应用于多模态生成领域。他们提出GEMS(Agent-Native Multimodal Generation with Memory and Skills),激发小模型潜力,甚至让6B小模型在部分任务超越了Nano Banana 2。
来自主题: AI技术研报
7727 点击 2026-04-11 10:36