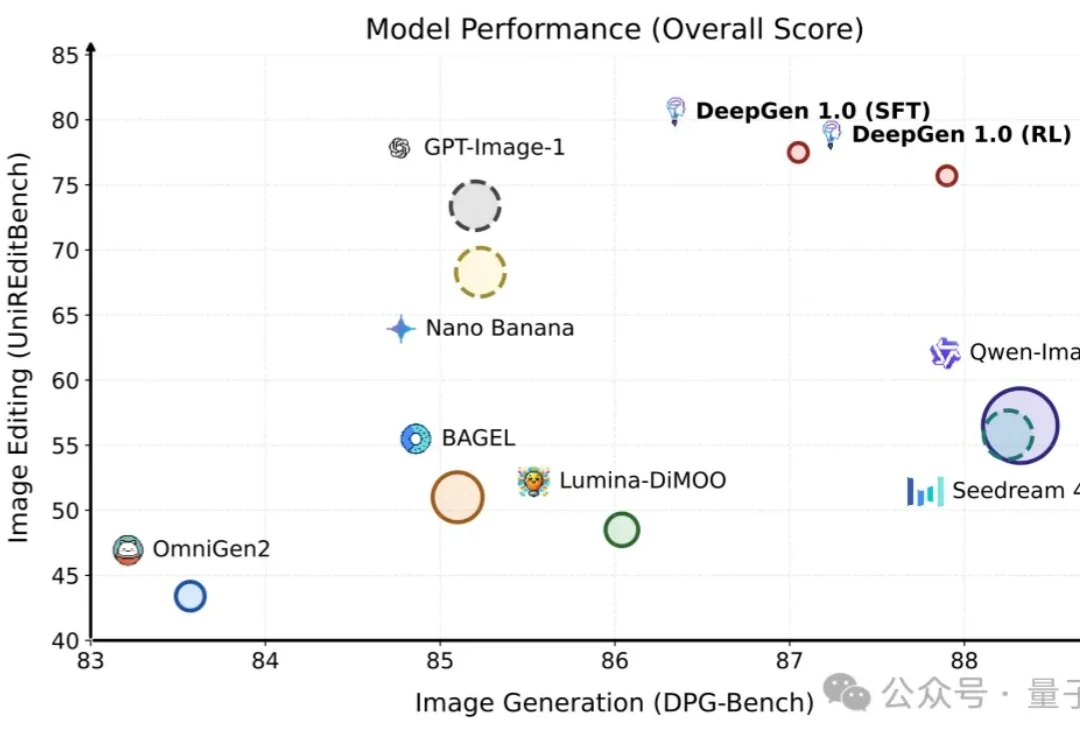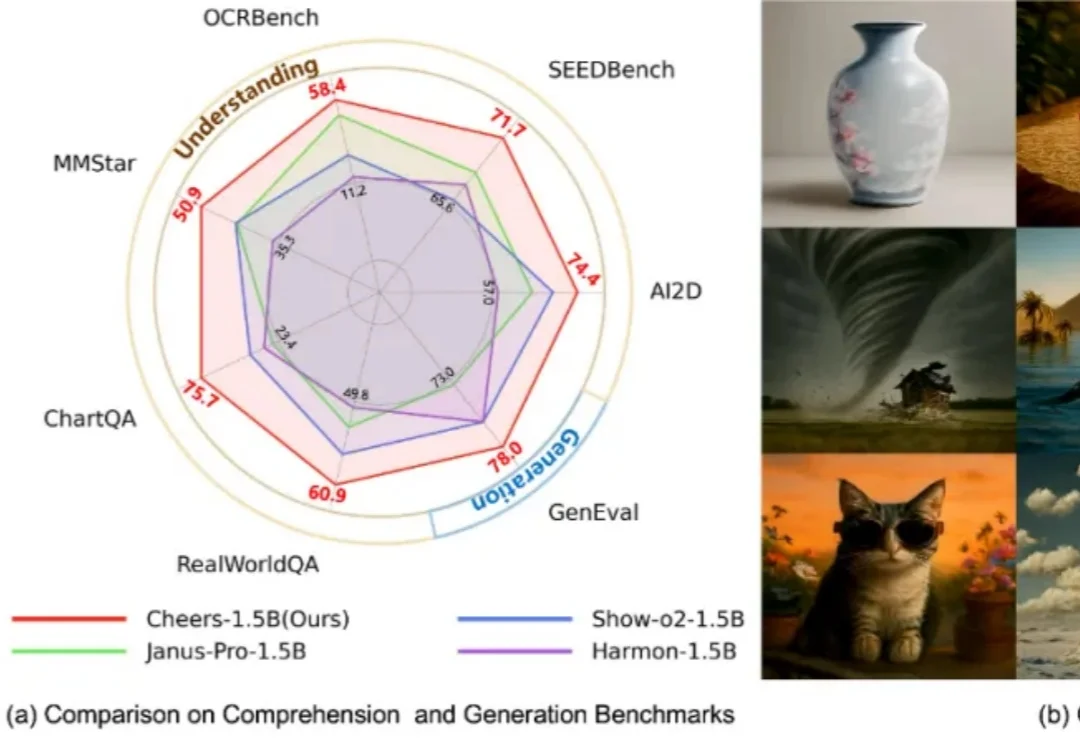
清华、西交联合开源发布了Cheers : 一条更简洁、更高效的统一多模态路线
清华、西交联合开源发布了Cheers : 一条更简洁、更高效的统一多模态路线过去几年,多模态模型在理解任务上快速演进,图像问答、OCR、视觉推理、跨模态对话等能力不断提升;与此同时,图像生成模型也在视觉质量、指令遵循和细节表达上持续突破。下一步一个自然的问题是:能否用同一个模型,同时做好理解与生成?这正是统一多模态模型(Unified Multimodal Models, UMMs)正在回答的问题。
来自主题: AI技术研报
6956 点击 2026-03-26 14:45