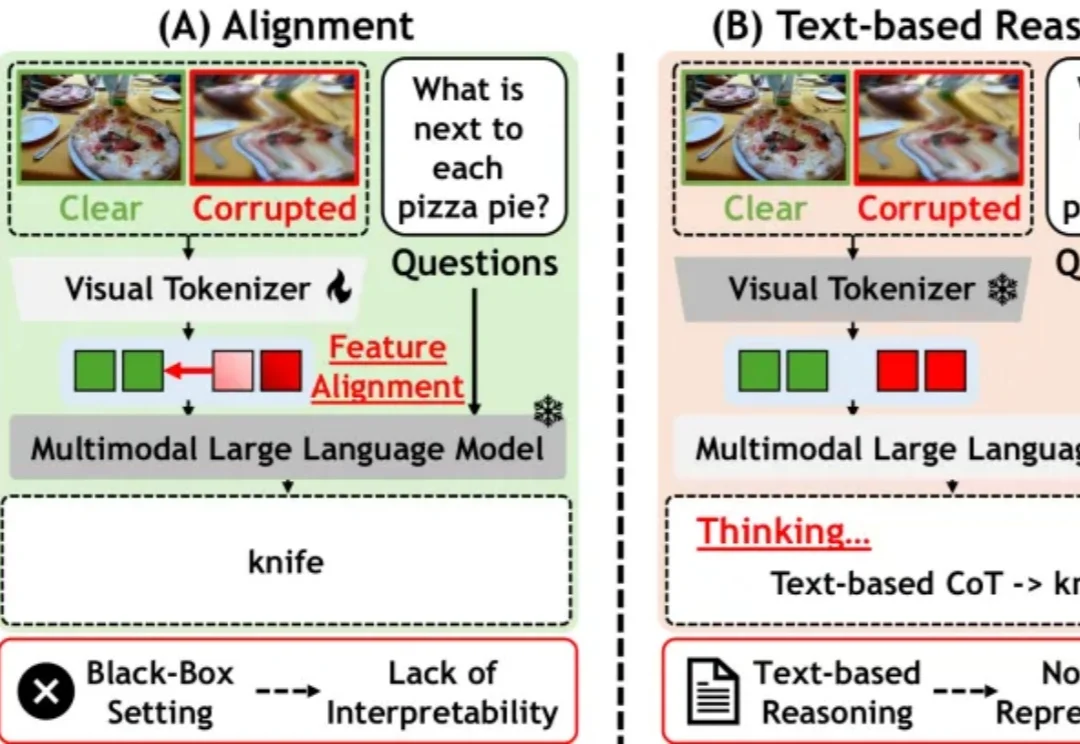
看不清就乱答?多模态大模型的这个毛病终于有解了 | ICML 2026
看不清就乱答?多模态大模型的这个毛病终于有解了 | ICML 2026雨雪、雾霾、镜头噪点、压缩失真、夜间弱光……
来自主题: AI技术研报
7307 点击 2026-06-15 09:19
 搜索
搜索
雨雪、雾霾、镜头噪点、压缩失真、夜间弱光……
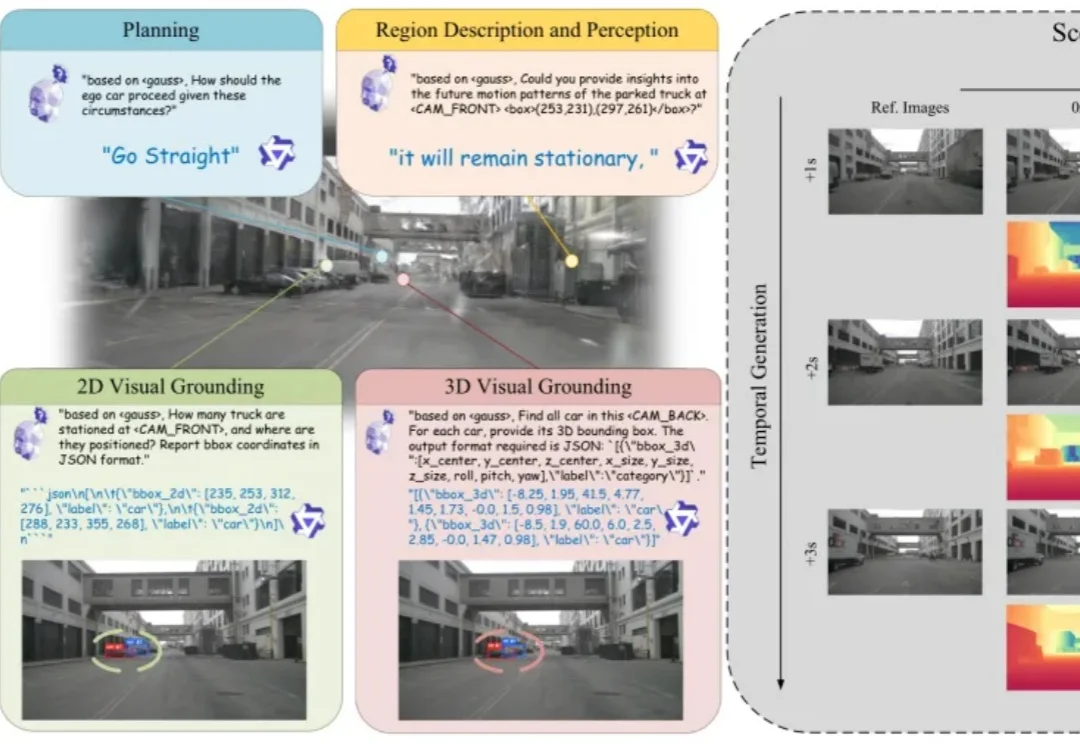
自动驾驶世界模型的研究目标已经从单纯预测未来视觉帧,扩展到构建可用于场景理解、空间定位和后续决策的世界表示。如果模型只能生成外观上合理的未来图像,却无法回答场景中有哪些目标、目标位于何处,以及不同视角下的空间结构如何变化,那么它仍然缺少对三维驾驶环境的显式建模能力。

多模态长记忆在“看得准、找得到、想得清”三大环节的底层逻辑与工程避坑指南。
想象这样一个惬意的周末: 空调带来阵阵凉意,你靠在沙发上看书,突然耳边传来“哒哒哒”的小碎步声,接着,玄关门边传来了一阵清脆、略带急切的“呜呜”声,还伴随着爪尖轻轻扒拉木门的声响。

过去一年,开源模型的发布节奏已经快到让人麻木。每次发布,伴随的永远是一组跑分、一张能力雷达图,以及几个“超越某某”的结论。
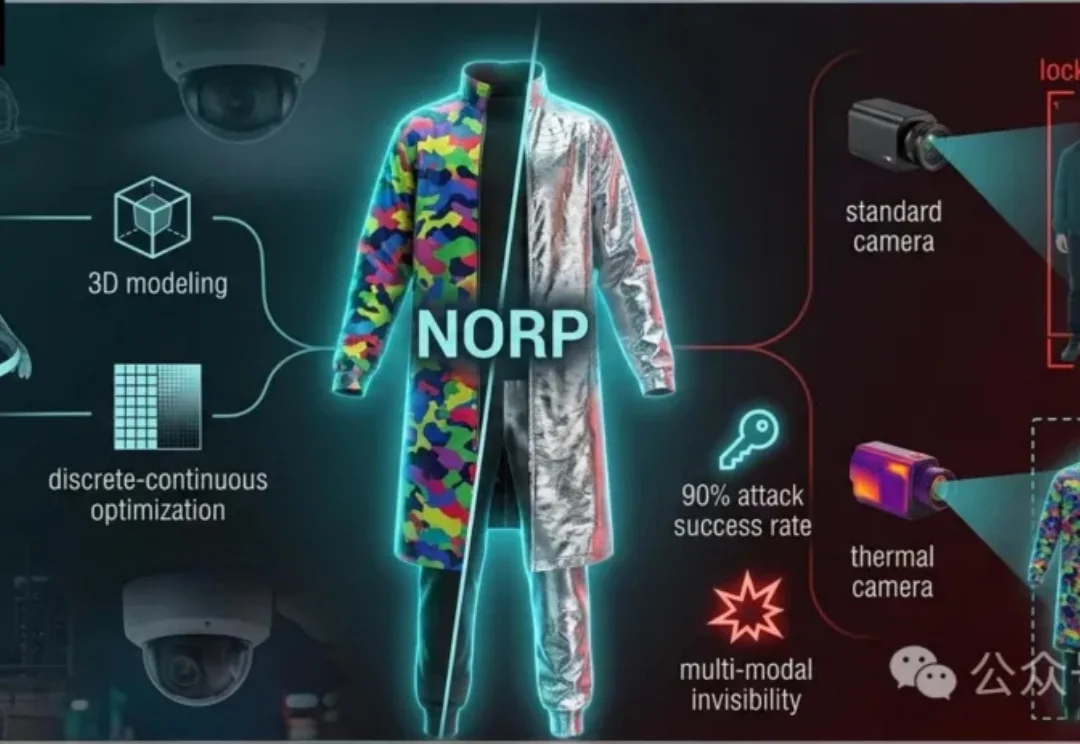
清华大学提出一种新型物理对抗方法,利用特殊服装同时干扰可见光和热成像检测。这种服装通过非重叠设计和三维建模优化,可有效躲避RGB-T检测器,促进系统安全性研究。

早在 2023 年大模型快速发展期,哈工大张民教授立知大模型团队已开展多模态大模型驱动的视频内容创作智能体研究,并全球首发开源了电影制作智能体 FilmAgent 与动画片生成智能体 Anim-Director,受到国内外智能体研究者与文艺创作者的广泛关注。

具身智能公司戴盟机器人(Daimon Robotics)新近完成亿元A轮融资,本轮融资由汇川产投和中国电信联合投资。与此同时量子位还获悉了关于这家公司的另一则消息——阿里通义实验室前多模态研究专家原玮浩加入戴盟,担任首席AI科学家。

刚刚,谷歌DeepMind发布了Gemma 4 12B。一句话概括这个模型的定位:把原本需要高端服务器才能跑的多模态智能,装进你的笔记本电脑里。它填补的是Gemma家族里一个关键空缺:比边缘端的E4B更强,比26B混合专家模型(MoE)更轻。而且在整个Gemma 4系列里,它是第一个支持原生音频输入的中等规模模型。

由格灵深瞳灵感实验室主导研发的 LLaVA-OneVision-2.0,是一款面向下一代感知智能的视觉语言大模型。团队充分利用视频 Codec 流和自研 OneVision-Encoder,实现跨帧、跨事件的增量观测和连续证据流建模。本文将详细介绍模型架构、训练方法与能力验证,展示该技术在视频理解、空间推理和目标追踪等任务中的应用潜力。