# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在 3D 生成领域,根据文本提示创建高质量的 3D 人体外观和几何形状对虚拟试穿、沉浸式远程呈现等应用有深远的意义。传统方法需要经历一系列人工制作的过程,如 3D 人体模型回归、绑定、蒙皮、纹理贴图和驱动等。为了自动化 3D 内容生成,此前的一些典型工作(比如 DreamFusion [1] )提出了分数蒸馏采样 (Score Distillation Sampling),通过优化 3D 场景的神经表达参数,使其在各个视角下渲染的 2D 图片符合大规模预训练的文生图模型分布。然而,尽管这一类方法在单个物体上取得了不错的效果,我们还是很难对具有复杂关节的细粒度人体进行精确建模。
为了引入人体结构先验,最近的文本驱动 3D 人体生成研究将 SDS 与 SMPL 等模型结合起来。具体来说,一个常见的做法是将人体先验集成到网格(mesh)和神经辐射场(NeRF)等表示中,或者通过将身体形状作为网格 / 神经辐射场密度初始化,或者通过学习基于线性混合蒙皮(Linear Blend Skinning)的形变场。然而,它们大多在效率和质量之间进行权衡:基于 mesh 的方法很难对配饰和褶皱等精细拓扑进行建模;而基于 NeRF 的方法渲染高分辨率结果对时间和显存的开销非常大。如何高效地实现细粒度生成仍然是一个未解决的问题。
最近,3D Gaussian Splatting(3DGS)[2] 的显式神经表达为实时场景重建提供了新的视角。它支持多粒度、多尺度建模,对 3D 人体生成任务非常适用。然而,想要使用这种高效的表达仍有两个挑战:1) 3DGS 通过在每个视锥体中排序和 alpha - 混合各向异性的高斯来表征基于图块的光栅化,这仅会反向传播很少一部分的高置信度高斯。然而,正如 3D 表面 / 体积渲染研究所证实的那样,稀疏的梯度可能会阻碍几何和外观的网络优化。因此,3DGS 需要结构引导,特别是对于需要层次化建模和可控生成的人体领域。2)朴素的 SDS 需要一个较大的无分类器指导(Classifier-Free Guidance)来进行图像文本对齐(例如,在 DreamFusion [1] 中使用的 100)。但它会因过度饱和而牺牲视觉质量,使真实的人类生成变得困难。此外,由于 SDS 损失的随机性,3DGS 中原始的基于梯度的密度控制会变得不稳定,导致模糊的结果和浮动伪影。
在最近的一项工作中,香港中文大学、腾讯 AI Lab、北京大学、香港大学、南洋理工大学团队推出最新有效且快速的 3D 人体生成模型 HumanGaussian,通过引入显式的人体结构引导与梯度规范化来辅助 3D 高斯的优化过程,能够生成多样且逼真的高质量 3D 人体模型。目前,代码与模型均已开源。

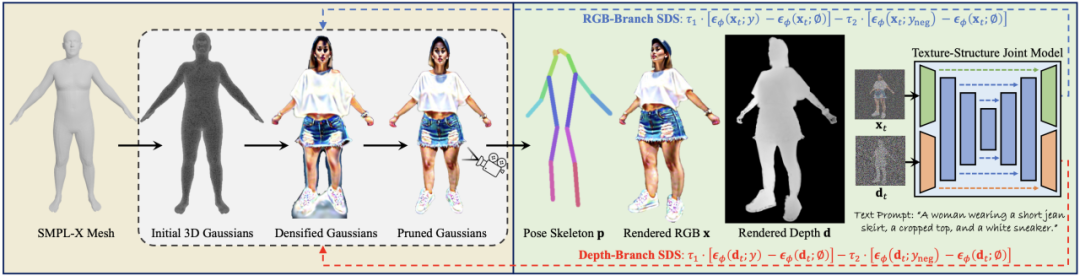
(1)Structure-Aware SDS
研究者基于 SMPL-X 网格形状初始化 3D 高斯中心位置:1)以前的研究使用运动结构点(Structure-from-Motion)或 Shap-E [3] 和 Point-E [4] 等通用文本到点云先验。然而,此类方法通常在人体类别中存在点过于稀疏或身体结构不连贯等问题。2)作为 SMPL 的扩展,SMPL-X 补充了人脸和手部的形状拓扑,有利于进行具有细粒度细节的复杂人体建模。基于这些观察,研究者提出了在 SMPL-X 网格表面均匀采样点作为 3DGS 初始化。他们对 3DGS 进行缩放和变换,使其达到合理的人体尺寸并位于 3D 空间的中心。
由于 SMPL-X 先验仅用作初始化,因此需要更全面的指导来促进 3DGS 训练。研究者提出使用一个同时捕获纹理和结构联合分布的 SDS 源模型,而不是从仅学习外观或几何形状的单一模态扩散模型中学习 3D 场景。他们使用结构专家分支扩展预训练的 Stable Diffusion 模型,以同时对图像 RGB 和深度图进行去噪:
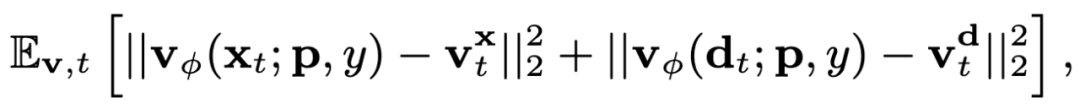
借助这种方式,研究者获得了一个统一的模型,可以捕获外观的图像纹理和前景 / 背景关系的结构,该模型可以在 SDS 中用于促进 3DGS 学习。
通过生成空间对齐图像 RGB 和深度的扩展扩散模型,可以从结构和纹理方面同时指导 3DGS 优化过程:
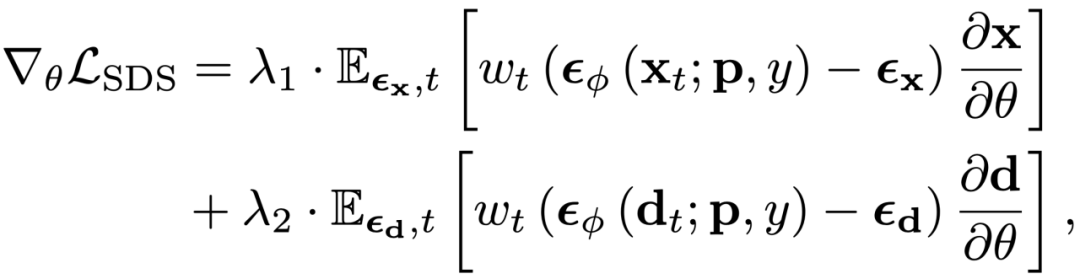
这种结构正则化有助于减少几何失真,从而有利于具有稀疏梯度信息的 3DGS 优化。
(2)Annealed Negative Prompt Guidance
为了促进文本与 3D 生成内容之间的对齐,DreamFusion [1] 使用较大的无分类器引导尺度来更新 3D 场景优化的分数匹配差异项:
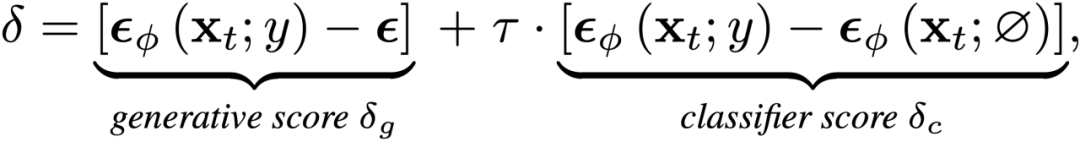
在这个公式中,可以自然地将分数匹配差异分解为两部分,其中前一项是将图像推向更真实的流形的生成分数;后一项是将样本与隐式分类器对齐的分类器分数。然而,由于生成分数包含高方差的高斯噪声,它提供了损害训练稳定性的随机梯度信息。为了解决这个问题,DreamFusion 特地使用较大的无分类器引导尺度,使分类器分数主导优化,导致模式过度饱和。相反,研究者仅利用更清晰的分类器分数作为 SDS 损失。
在文生图和文生 3D 领域中,负文本被广泛用于避免生成不需要的属性。基于此,研究者提出增加负文本分类器分数以实现更好的 3DGS 学习。
根据经验,研究者发现负文本分类器分数会在小时间步长内损害质量,因此使用退火的负文本引导来结合两个分数进行监督:
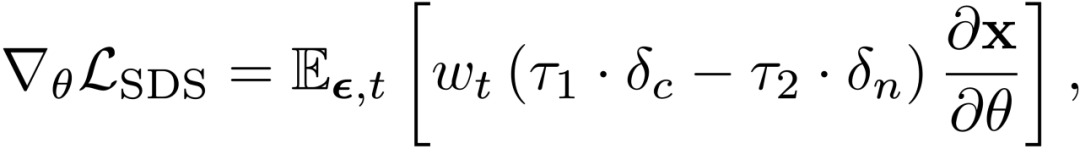
研究者与通用的文生 3D 和 3D 人体生成领域的模型进行对比。可以看到,HumanGaussian 取得了优越的性能,渲染出更真实的人体外观、更连贯的身体结构、更好的视图一致性、更细粒度的细节捕捉:

此外,研究者还通过消融实验验证了各个模块的有效性。可以看出,SMPL-X 提供的人体结构先验可以给 3DGS 优化提供初始化信息;负文本引导可以确保逼真的人体纹理外观;图像 RGB 与深度图双分支的 SDS 监督约束可以同时对人体的几何和纹理进行优化;最后根据高斯大小进行剪枝可以去除雾状的伪影:

以下是一些高清的多视角 3D 人体生成结果图:


更多样本请参考文章的项目主页以及 demo 视频。
本文提出 HumanGaussian,一种有效且快速的框架用于生成具有细粒度几何形状和逼真外观的高质量 3D 人体。HumanGaussian 提出两点核心贡献:
(1)设计了结构感知的 SDS,可以显式地引入人体结构先验,并同时优化人体外观和几何形状;
(2)设计了退火的负文本引导,保证真实的结果而不会过度饱和并消除浮动伪影。总体来说,HumanGaussian 能够生成多样且逼真的高质量 3D 人体模型,渲染出更真实的人体外观、更连贯的身体结构、更好的视图一致性、更细粒度的细节捕捉。
未来工作:
1. 由于现有的文生图模型对于手部和脚部生成的性能有限,研究者发现它有时无法高质量地渲染这些部分;
2. 后背视图的渲染纹理可能看起来模糊,这是因为 2D 姿势条件模型大多是在人类正面视图上训练的,而人类后视图的先验知识很少。
参考文献
[1] Dreamfusion: Text-to-3d using 2d diffusion, ICLR’23
[2] 3d gaussian splatting for real-time radiance field rendering, SIGGRAPH’23
[3] Shap-e: Generating conditional 3d implicit functions, arXiv preprint arXiv: 2305.02463
[4] Point-e: A system for generating 3d point clouds from complex prompts, arXiv preprint arXiv: 2212.08751
文章来自于微信公众号 “机器之心”,作者 “香港中文大学、腾讯AI Lab、北京大学、香港大学、南洋理工大”


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
