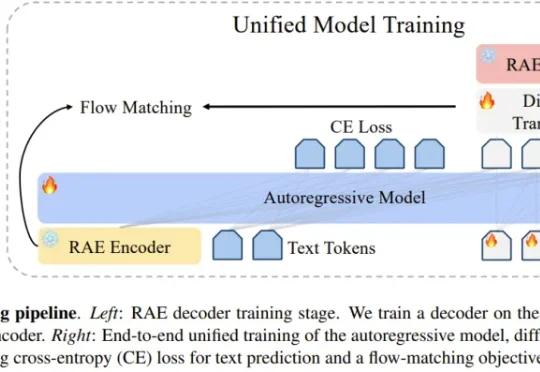
沿着何恺明团队「漂移模型」再走一步:奖励只需排名,单步文生图偏好优化提速3.51倍
沿着何恺明团队「漂移模型」再走一步:奖励只需排名,单步文生图偏好优化提速3.51倍来自西湖大学和香港中文大学(深圳)的团队沿着这一思路提出 Drifting Preference Optimization(DrPO),把漂移场用于单步文生图模型的偏好后训练。在 DrPO 中,奖励只负责对候选图像排序,不参与反向传播。具体而言,针对同一个文本提示词,当前模型生成一组候选图像。高分样本在特征空间中产生吸引,低分样本产生排斥,并结合参考模型约束给出模型的更新方向。
来自主题: AI技术研报
7367 点击 2026-06-21 10:33