# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文作者姜洲是西湖大学的研究助理和即将入学香港中文大学(深圳)的博士生。温研东是西湖大学工学院的助理教授,刘圳是香港中文大学(深圳)数据科学学院的助理教授。
近两年,单步生成模型的性能不断提升,训练方式也逐渐摆脱对预训练扩散模型蒸馏的依赖。与此同时,去噪轨迹和策略似然这些信号不再容易拿到,许多偏好优化方法很难直接套用。如何对这类模型做偏好后训练,也成了一个绕不开的问题。
今年初,何恺明团队提出漂移模型(Drifting Model),为单步生成模型训练引入了 “漂移场”。在训练过程中,漂移场为当前生成分布给出更新方向,推动它逐步靠近真实数据分布,由此绕开对去噪轨迹的依赖。那么,能不能用类似的漂移目标,来做单步生成模型的偏好后训练?
来自西湖大学和香港中文大学(深圳)的团队沿着这一思路提出 Drifting Preference Optimization(DrPO),把漂移场用于单步文生图模型的偏好后训练。在 DrPO 中,奖励只负责对候选图像排序,不参与反向传播。具体而言,针对同一个文本提示词,当前模型生成一组候选图像。高分样本在特征空间中产生吸引,低分样本产生排斥,并结合参考模型约束给出模型的更新方向。
由于目标奖励不参与反向传播,DrPO 可以在大型奖励模型上收敛更快:当目标奖励采用基于多模态大模型的奖励函数 HPSv3 时,DrPO 相比需要反传奖励梯度的 DRaFT 提速 3.51 倍。同时,由于 DrPO 不依赖奖励模型本身得到梯度,DrPO 还能应用于不可微奖励模型的微调。

从漂移场到强化学习后训练
漂移模型提供了一种从有限样本估计漂移场的方法:真实数据样本作为正样本,当前模型样本作为负样本;正样本提供吸引,负样本提供排斥。模型不需要显式估计完整数据分布,只需在特征空间中估计这种局部漂移,生成分布便会随训练逐步靠近真实数据分布。
将这套思路用于强化学习后训练时,需要先处理样本来源的问题。强化学习目标给出的是奖励函数,而不是漂移模型所需的正负样本。DrPO 在每个训练步中由当前模型在策略(on-policy)采样候选图像,再用目标奖励对同一提示词下的候选图像打分排序。高分图像和低分图像不是预先给定的偏好对,而是在策略采样后构造出的正负样本。
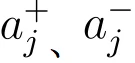
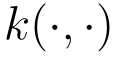
设当前样本特征为 Z,由奖励排序得到的高分和低分图像特征分别为,核函数衡量特征相似度。论文将这组在线构造出的正负关系写成偶极奖励函数:
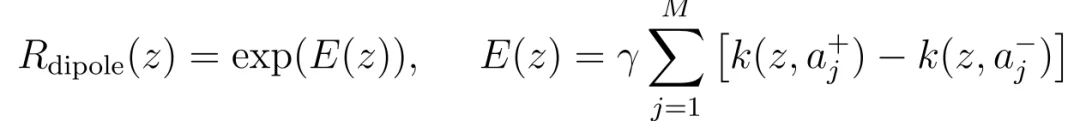
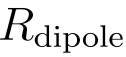
这里的是根据当前 batch 中的排序结果直接构造出的局部势场。当前样本越接近高分图像,正项越大;越接近低分图像,负项越大。
更新方向来自该函数的梯度:
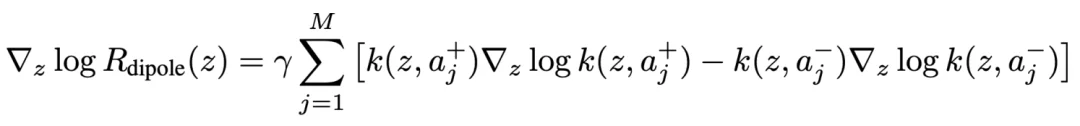
这个式子保留了漂移模型的吸引 / 排斥结构:正样本项贡献吸引,负样本项贡献排斥;核相似度越高,对当前样本的影响越大。到这一步,奖励排序被转化为局部漂移方向。对应到漂移模型的核加权形式,漂移场可写为:
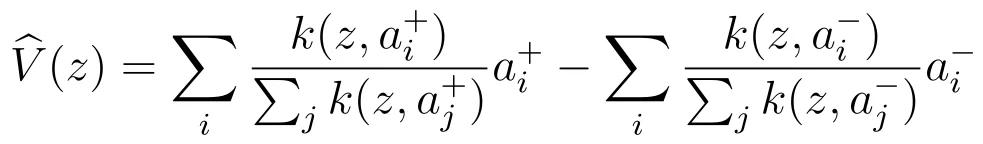
偏好漂移只近似奖励项对应的方向。完整的强化学习微调还需要限制模型不要偏离基础分布,因此目标中包含 KL 约束:

它的策略梯度是:
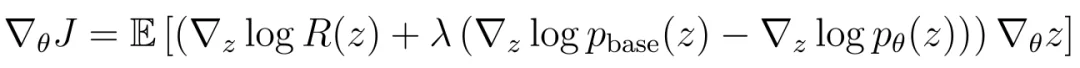
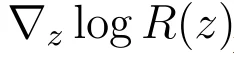
其中,是奖励方向,由前面的高分 / 低分样本漂移近似。KL 项拆成两部分:基础模型分布提供吸引,当前模型分布提供排斥。DrPO 对这部分也使用漂移估计,即参考模型样本作为正样本,当前模型样本作为负样本。
将奖励项对应的偏好漂移和 KL 项对应的参考漂移合并,得到 DrPO 实际使用的更新方向:
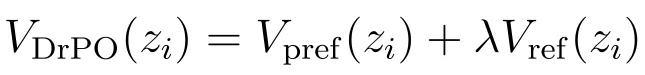
得到漂移方向后,DrPO 将其转化为当前样本的回归目标:
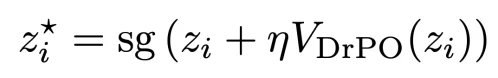
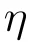
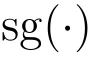
是控制漂移场强度的超参,表示 stop-gradient。模型随后优化当前样本与目标点之间的距离:
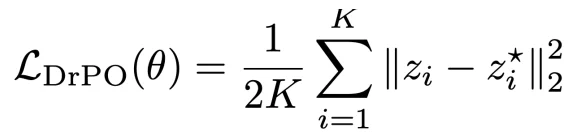
图 1:DrPO 方法概览。左图对应上述两类漂移:绿色 / 红色点来自当前模型在线候选图像中的高分和低分样本,构成偏好漂移;蓝色 / 灰色点来自参考模型和当前模型,构成参考漂移。两者合并后,确定黑色当前样本的目标位置。右侧展示了固定提示词下,生成结果随在线微调逐步变化的过程。

图 2: DrPO 算法。其中,drift radii 表示构造漂移场时使用的一组核函数尺度参数。
实验结果
实验首先验证的是,DrPO 构造出的漂移方向是否能稳定改善单步文生图模型。研究团队在 SD-Turbo 和 SDXL-Turbo 上进行在线微调,训练提示词来自 Pick-a-Pic v2,评测覆盖 Pick-a-Pic v2 测试集和 Parti-Prompts。
除了 PickScore、Aesthetic Score 和 ImageReward 等标量指标,论文还使用 Qwen3-VL 进行成对偏好比较,从语义忠实度、整体连贯性、图像瑕疵和审美质量等维度判断两张图像的相对优劣。在两个评测集合上,DrPO 相较多种单步生成对照方法获得了更高的 win rate。
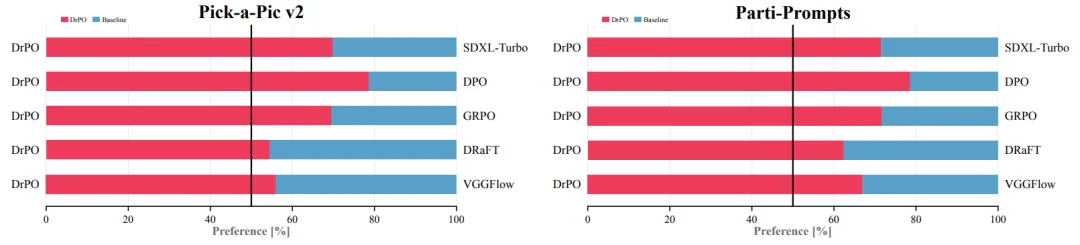
图 3:Qwen3-VL 成对偏好评测。对于同一提示词下的匹配生成结果,Qwen3-VL 从语义忠实度、整体连贯性、图像瑕疵和审美质量等方面进行比较。红色表示 DrPO 获得偏好,蓝色表示对照方法获得偏好;A/B 顺序经过随机化处理。
其他定量指标给出了类似结果。在 SD-Turbo 和 SDXL-Turbo 上,DrPO 相比其他不依赖奖励梯度的方法,均提升了 PickScore、AES 和 ImageReward 等指标。定性结果中,DrPO 生成图像在指令跟随和视觉质量上也更稳定。

图 4:SD-Turbo 上的定性对比。图片使用相同提示词进行生成。
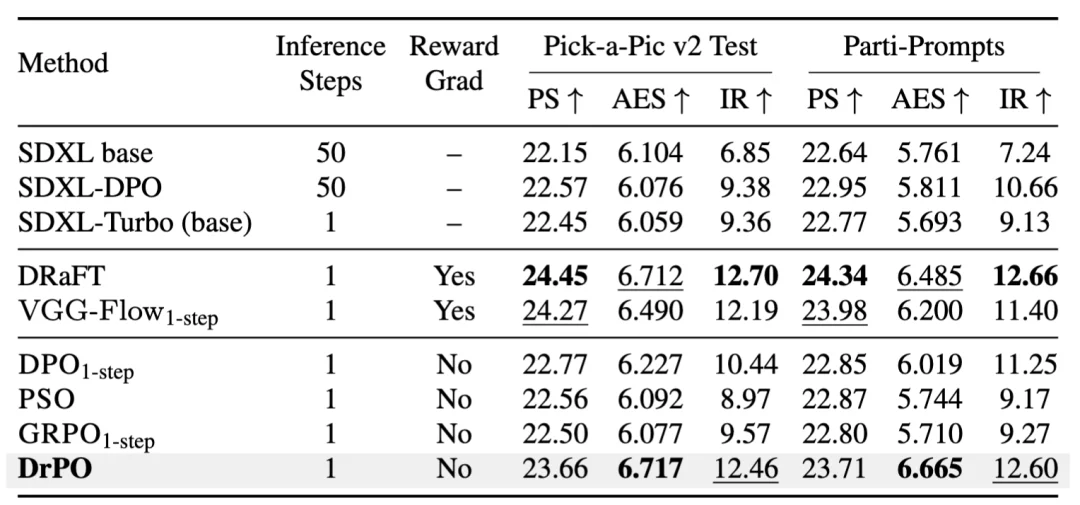
表 1:SDXL-Turbo 上的定量结果。DrPO 在保持单步推理的同时,在不使用奖励梯度的方法中取得了更好的整体结果。
在大型奖励模型上,训练提速 3.51 倍
大型多模态奖励模型会放大奖励梯度方法的训练开销。论文使用 HPSv3 作为目标奖励,对比 DrPO 和 DRaFT 在相同 effective batch size 下的单次更新时间。DRaFT 每次更新需要 21.62 秒,DrPO 为 6.17 秒,相比 DRaFT 提速 3.51 倍。
差异主要来自反向传播路径。DRaFT 需要通过 HPSv3 网络回传奖励梯度;DrPO 则只用 HPSv3 对候选图像前向打分和排序,随后用特征提取器在特征空间中估计漂移方向,并通过回归损失更新生成模型。换言之,目标奖励仍然决定哪些样本更好,但梯度计算不再经过 HPSv3,而是落到特征空间的漂移回归上。因此,当目标奖励模型较重时,DrPO 的训练开销会明显低于直接反传奖励梯度的方法。
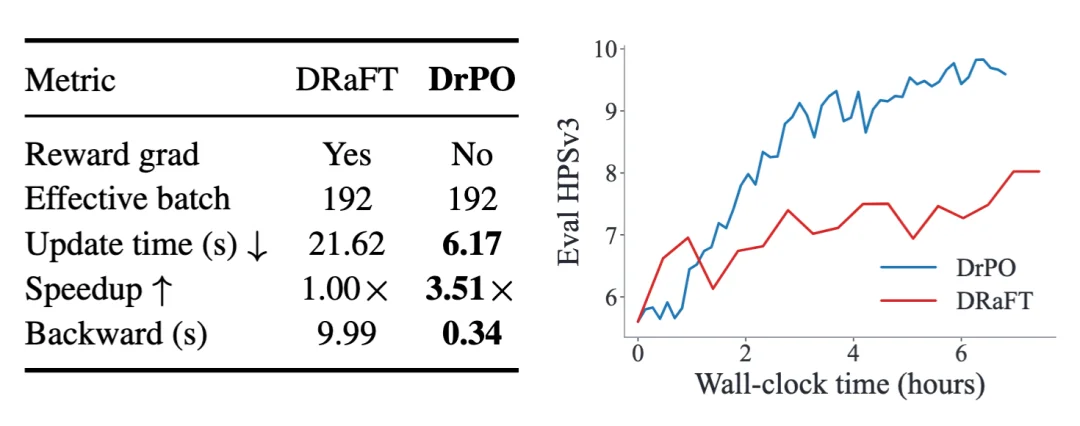
图 5:HPSv3 奖励下的训练效率对比。在有效 batch size 相同的条件下,DrPO 无需通过 HPSv3 回传梯度,相比 DRaFT 提速 3.51 倍。
不可微奖励也能接入
由于目标奖励只参与排序,DrPO 也可以接入不可微评价信号。论文进一步使用 GenEval 得分作为奖励进行训练。GenEval 主要考察物体数量、颜色、位置和属性绑定等组合约束,这类评价更接近规则或程序化打分,不适合直接作为可微奖励反传。
实验中,研究团队针对不同 GenEval 子任务分别微调 SD-Turbo,并在对应类别上评测。结果显示,这些子任务对应微调模型在各自目标类别上均取得提升。这个设置验证了:即使奖励信号不可微,只要它能对候选结果给出分数或排序,DrPO 仍然可以将其接入在线微调。

图 6:使用 GenEval 得分作为不可微奖励进行训练。左:各子任务得分;右:部分生成样例。
消融实验
消融实验进一步说明了特征空间在 DrPO 中的作用。漂移方向不是直接由奖励模型给出,而是在特征空间中根据样本相似度估计出来的;因此,特征提取器本身提供了一种额外先验,决定哪些样本被认为接近、哪些方向更可行。实验显示,latent-MAE 特征优于预训练模型自身特征。
如果特征空间没有充分编码目标奖励关注的属性,例如计数、布局、文字或细粒度身份信息,由相似度估计出的漂移方向就可能不够可靠。除此之外,增加候选样本数量可以改善结果,而 DrPO 对核函数选择不太敏感。

表 2:候选样本数量、特征提取器、核函数和速度尺度上的消融实验。

图 7:reference drift 的作用。参考项用于限制微调后的模型偏离基础模型原有的分布。
离线偏好微调的初步尝试
论文还尝试了一个离线版本:不再由当前模型在线采样并排序,而是直接使用离线偏好数据集中的图像对构造漂移场。结果显示,相比单步模型的 DPO 变体,离线 DrPO 收敛更快。
不过,离线设置仍然面临分布偏移问题。离线数据集中的图像对未必落在当前模型分布附近,用它们估计出的漂移场会更粗糙。随着微调时间拉长,这种偏差可能积累,训练也更容易崩溃。
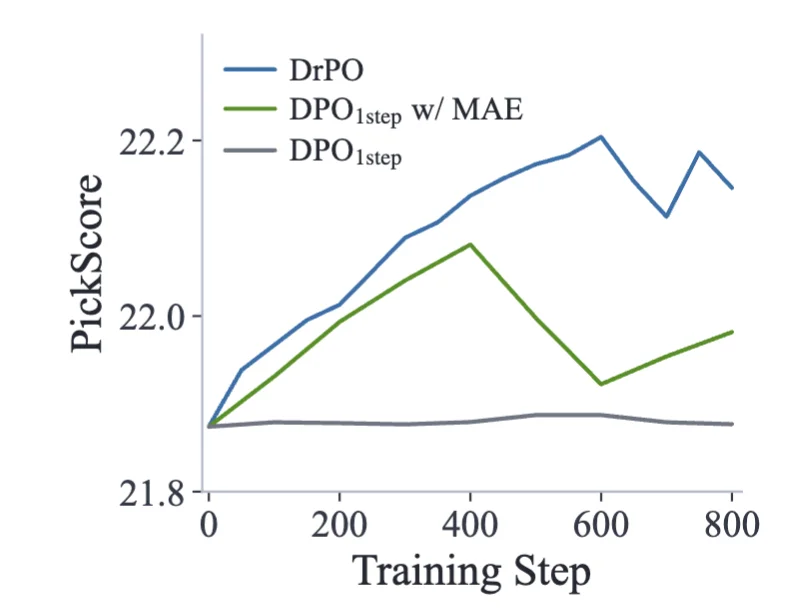
图 8:离线 DrPO 的收敛曲线。
总结
DrPO 将漂移模型中的漂移场估计引入单步文生图模型的强化学习后训练。每一步中,当前模型在当前策略下采样候选图像,目标奖励负责打分排序;高分和低分样本用于构造偏好漂移,参考模型和当前模型样本用于构造分布约束对应的参考漂移。最终,模型通过回归到漂移目标完成更新。
实验表明,DrPO 在 SD-Turbo 和 SDXL-Turbo 上改善了生成质量;在 HPSv3 这类大型奖励模型下,相比需要反传奖励梯度的 DRaFT 实现了 3.51 倍训练提速;同时,也可以接入 GenEval 等不可微奖励模型。
文章来自于微信公众号 “机器之心”,作者 “机器之心”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
