# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在文生图模型的技术版图中,VAE 几乎已经成为共识。从 Stable Diffusion 到 FLUX,再到一系列扩散 Transformer,主流路线高度一致:先用 VAE 压缩视觉信息,再在潜空间中完成生成。这条路径被反复验证、规模化扩展,也几乎没有再被认真挑战过。
但挑战者其实早已到来,它就是谢赛宁团队提出的表征自编码器(RAE),详见我们去年十月的报道《VAE 时代终结?谢赛宁团队「RAE」登场,表征自编码器或成 DiT 训练新基石》。
现在,RAE 方向又诞生了一项新的重磅成果。并且是来自 Rob Fergus、Yann LeCun 以及谢赛宁三位业内知名学者领导的一个联合团队。

他们解答了一个更加基础的问题:我们真的需要 VAE 才能做好大规模文生图吗?
这篇工作给出的答案颇为激进。该团队系统性地扩展了「表征自编码器」这一思路,在冻结的语义表征编码器之上构建扩散模型,从 ImageNet 一路扩展到大规模自由文本生成场景。
结果显示,在从 5 亿到近百亿参数的多个尺度上,RAE 不仅在预训练阶段全面优于当前最强的 VAE 方案,还在高质量数据微调时展现出惊人的稳定性,而 VAE 模型却在短短 64 个 epoch 后出现灾难性过拟合。
可以说,这篇论文释放出了一个相当具有颠覆性的信号:当理解与生成共享同一套语义表征空间时,扩散模型的复杂工程设计反而可以被大幅削减。更进一步,这个思路或许有望打开多模态统一模型的想象空间。
架构设计:以表征自编码器重塑潜空间
在传统的潜向扩散模型(LDM)中,VAE 的作用是将图像压缩进一个极低维度的空间。然而,RAE 采用了截然不同的逻辑:它直接耦合一个预训练且冻结的视觉表征编码器(如 SigLIP-2),并仅训练一个轻量化的 ViT 结构解码器用于像素重建。
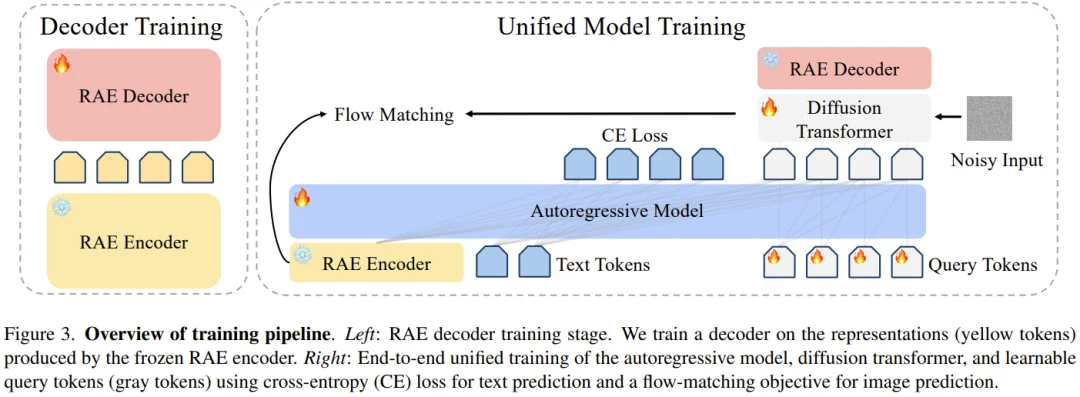
以研究中采用的 SigLIP-2 So400M 为例,它会将一幅图像转化为 16×16 个 token,每个 token 的维度高达 1152。这一维度远超主流 VAE 方案(通道数通常小于 64),为生成过程提供了极高保真度的语义起点。为了将这一思路从 ImageNet 推广至复杂的文本生成场景,研究团队进行了三项深度的架构探索。
超越规模的数据组成策略
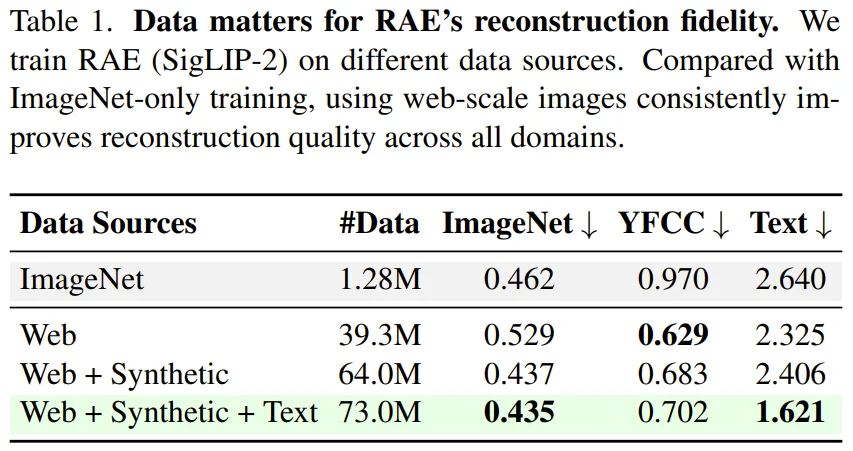
研究发现,单纯增加数据量并不能让 RAE 完美处理文生图任务。团队构建了一个包含约 7300 万条数据的大规模数据集,涵盖了 Web 图像、由 FLUX.1-schnell 生成的高美感合成图像以及专门的 RenderedText 文本渲染数据。
实验数据揭示了一个关键的技术细节:虽然在 Web 规模数据上训练能提升模型对自然图像的泛化能力,但对于「文本渲染」这一特定领域,数据的组成比例至关重要。
如表 1 所示,若缺乏针对性的文本渲染数据,解码器即使在数千万张 Web 图片上训练,也无法还原出清晰的字形细节。只有引入了文本专项数据后,其在 Text 域的 rFID 分数才出现了质的飞跃。
除了数据组成,研究团队还对比了不同视觉编码器作为 RAE 后端的重建质量。如表 2 所示,在 ImageNet、YFCC 以及文本(Text)这三个维度上,RAE 方案展现出了极具竞争力的保真度。
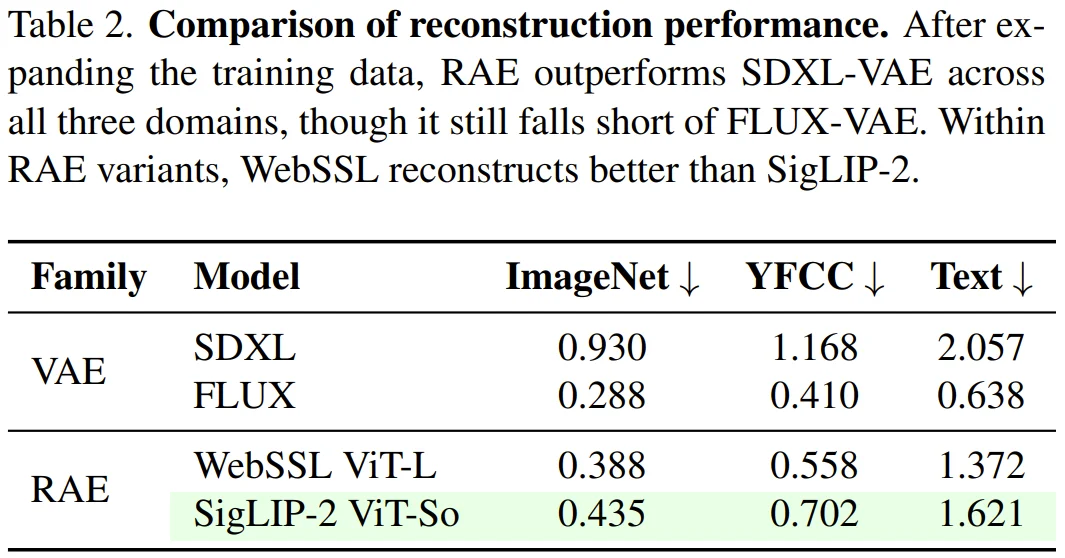

虽然 RAE 在绝对重建指标上目前还稍逊于顶尖的 FLUX VAE,但它已经全面超越了此前文生图领域的标杆 SDXL VAE。实验进一步发现,基于自监督学习(SSL)训练的 WebSSL ViT-L 编码器在图像重建任务中比 SigLIP-2 表现更优。这证明了 RAE 框架具备极佳的通用性,能够适配不同预训练目标的视觉编码器。
潜空间维度相关的噪声调度
由于 RAE 操作的是极高维度的语义表征,传统的扩散模型噪声调度方案会因为维度灾难而失效。为了解决这一数学难题,研究团队引入了维度敏感的噪声调度平移(Noise Schedule Shift)。
其核心逻辑是根据有效数据维度 m(即 token 数量 N 与通道维度 s 的乘积)对基础调度 t_n 进行重缩放。其计算公式如下:
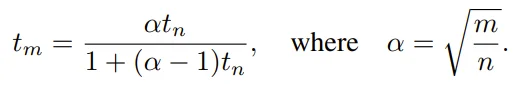
其中 α 是比例因子,n 为参考基准维度。实验证明,应用这一平移变换对模型收敛至关重要,不带平移的模型在 GenEval 上的表现甚至不及带平移模型的一半。
大模型时代的结构化减法
在 RAE 最初针对 ImageNet 的设计中,为了增强模型能力,曾引入过复杂的「宽扩散头(DiT^DH)」以及「噪声增强解码(Noise-augmented decoding)」。然而,这篇论文通过严谨的消融实验发现,当扩散 Transformer(DiT)的规模扩展至十亿参数以上时,这些复杂设计反而成了冗余。
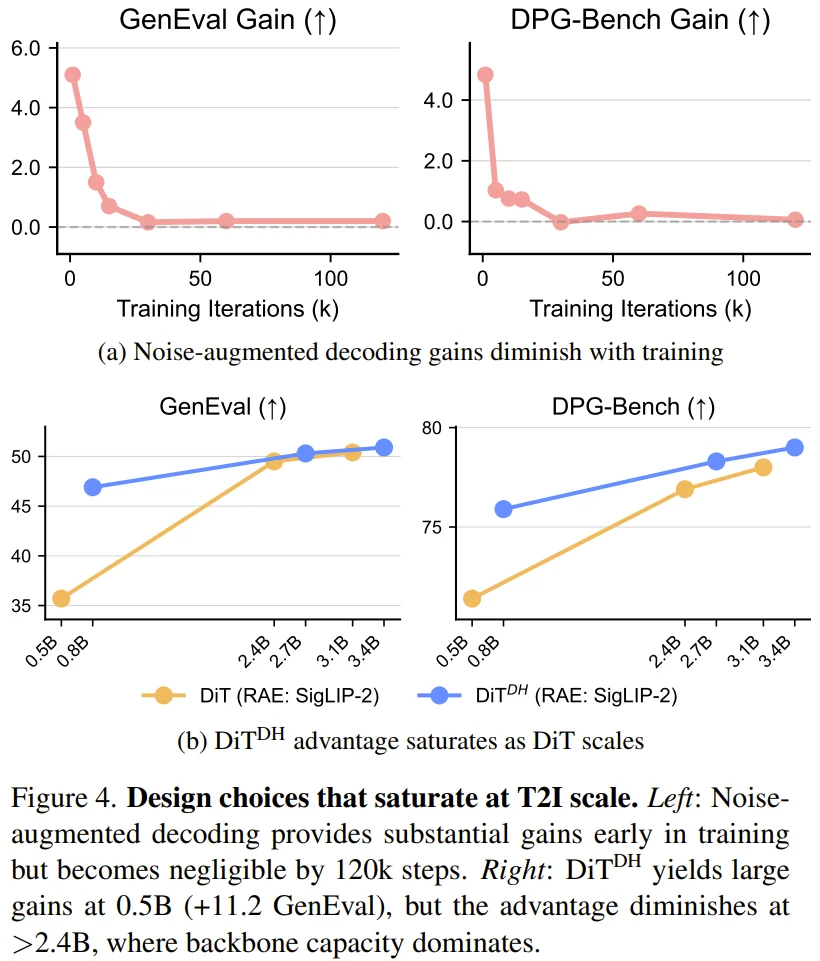
实验表现:从极速收敛到无惧过拟合
研究团队在从 0.5B 到 9.8B 参数的多个 DiT 尺度上,将 RAE 与目前最先进的 FLUX VAE 进行了系统性对比。
在相同的算力与数据条件下,RAE 展现出了显著的收敛速度优势。
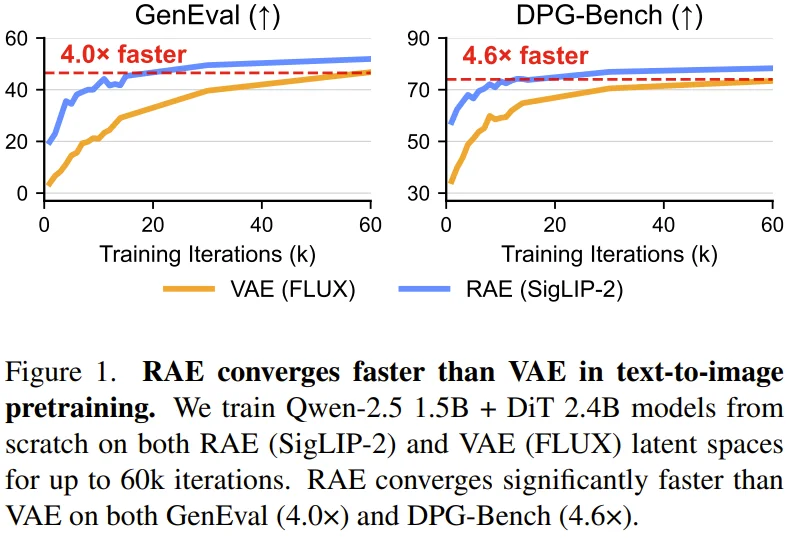
在 1.5B LLM 与 2.4B DiT 的基准测试中,RAE 达到同等生成质量所需的时间仅为 VAE 的四分之一左右。在 GenEval 评测中实现了 4.0 倍加速,在 DPG-Bench 上更是达到了 4.6 倍加速。
这种由 RAE 带来的效率提升与性能增益,在模型规模扩展过程中表现出了极强的鲁棒性。研究团队通过图 5 系统性地评估了 DiT 规模以及 LLM 骨干规模对最终生成效果的影响。
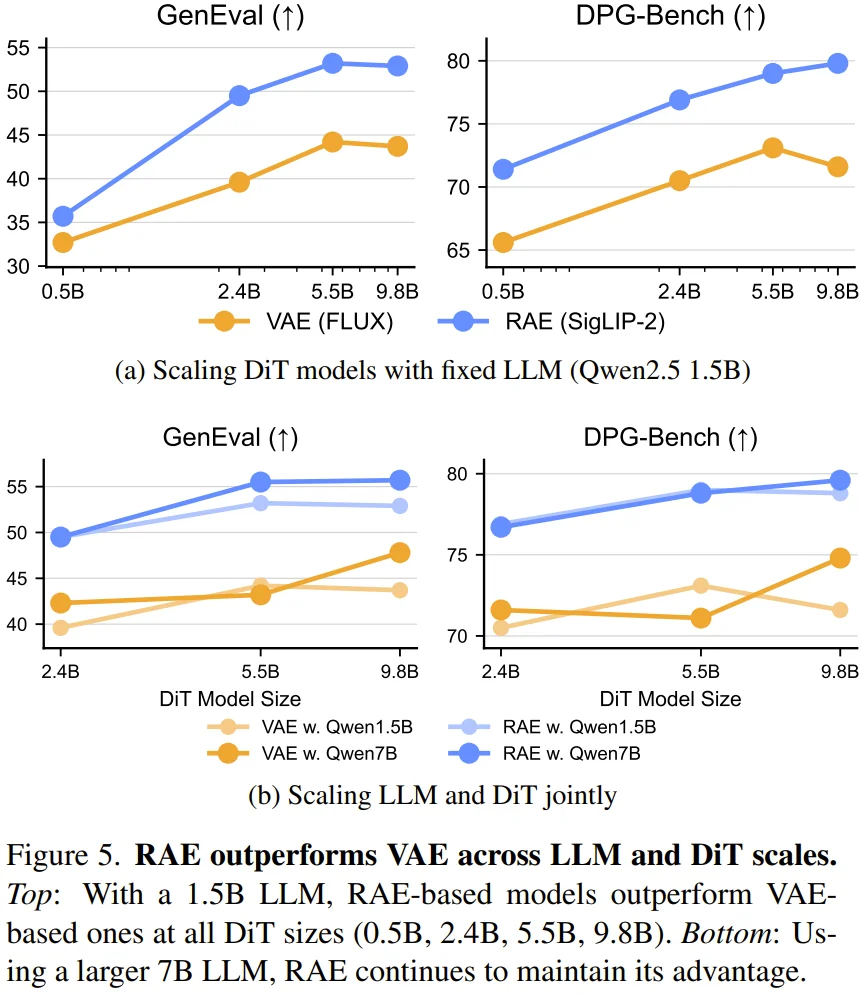
在 0.5B 到 9.8B 参数的所有 DiT 尺度下,RAE 均能稳定且大幅度地优于 VAE 方案。即便是在 DiT 隐藏维度仅略大于 RAE 潜空间维度的 0.5B 小模型上,这种优势依然清晰可见。此外,当 LLM 骨干从 1.5B 升级至 7B 时,RAE 模型能够更好地利用更丰富的文本表征,从而获得进一步的性能跨越。
这一发现极具启发意义。以往研究往往认为 LLM 规模的增加对文生图任务的增益有限,但本论文通过微调 LLM 骨干,证明了当生成与理解在同一个语义潜空间中对齐时,更大的语言模型确实能释放出更强的生成潜力。
而在针对高质量数据集(如 BLIP30-60k)进行的精细化微调中,RAE 与 VAE 方案的表现分化更是令人震惊。传统的 VAE 模型在训练至 64 个 epoch 左右后,会发生灾难性的过拟合,性能指标呈断崖式下跌。
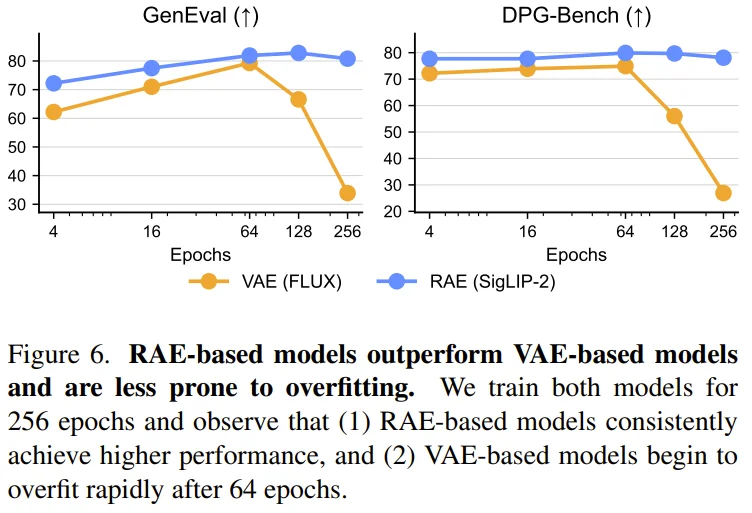
损耗曲线显示 VAE 的 Loss 会迅速跌至近乎为零,这意味着模型正在机械地死记硬背训练样本。
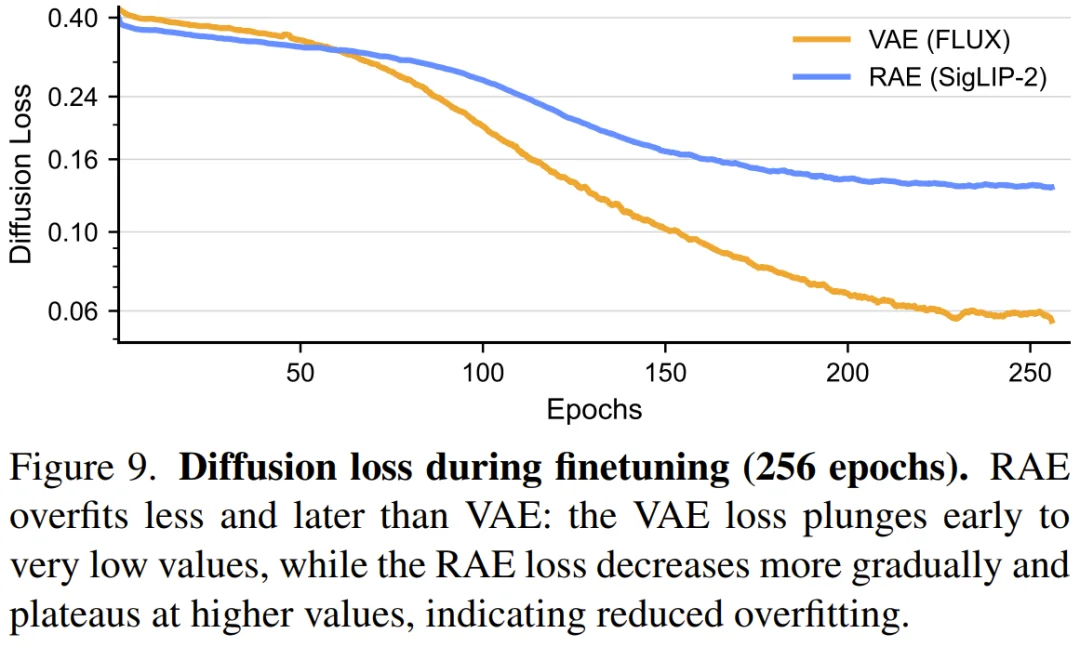
相比之下,RAE 表现出了极强的鲁棒性。即使持续微调至 256 个甚至 512 个 epoch,RAE 依然能保持稳定的生成质量。这种「天然」的防过拟合特性,或许得益于高维语义空间提供的隐式正则化作用。
迈向多模态统一的新可能
RAE 的意义不仅在于生成,它还让理解与生成在同一套语义特征空间中运行。
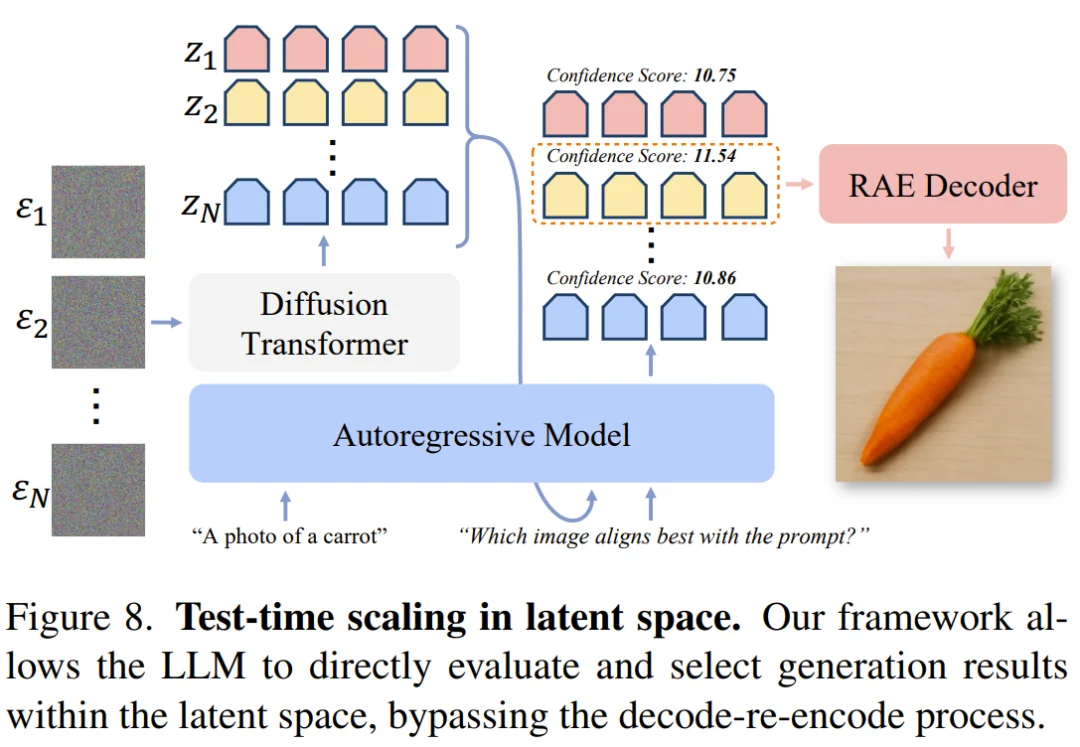
文生图技术栈的下一站
这篇论文为大规模文生图提供了一个全新的基础范式。
通过将 RAE 扩展至百亿参数规模,该团队证明了:我们不仅不需要 VAE 来实现高质量生成,甚至可以利用 RAE 获得更快的收敛速度、更高的训练稳定性和更好的多模态统一潜力。
当理解与生成不再需要依靠两个互不相通的潜空间(如 CLIP 与 VAE)来回切换时,扩散模型真正开始学会以「视觉语义」的角度去构建世界。
RAE 的成功,标志着潜向扩散模型正在从繁复的结构堆砌回归到更简洁、更本质的语义建模。
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
