# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

幻觉,早已成为LLM老生常谈的问题。
然而,OpenAI科学家Andrej Karpathy今早关于大模型幻觉的解释,观点惊人,掀起非常激烈的讨论。
在Karpathy看来:
从某种意义上说,大语言模型的全部工作恰恰就是制造幻觉,大模型就是「造梦机」。

另外,Karpathy的另一句话,更是被许多人奉为经典。他认为,与大模型相对的另一个极端,便是搜索引擎。
「大模型100%在做梦,因此存在幻觉问题。搜索引擎则是完全不做梦,因此存在创造力问题」。

总而言之,LLM不存在「幻觉问题」。而且幻觉不是错误,而是LLM最大的特点。只有大模型助手存在幻觉问题。
对此,英伟达高级科学家Jim Fan分享了自己的看法,「令人着迷的是,最好的LLM可以通过切换到『工具使用模式』来『决定』何时做梦,何时不做梦。网络搜索是一种工具。
LLM可以动态调整自己的『dream% 超参数』。GPT-4试图做到这一点,但远非完美」。

亚利桑那州立大学的教授Subbarao Kambhampati也跟帖回复了Karpathy:

LLM一直在产生幻觉,只是有时他们的幻觉碰巧和你的现实一致而已。
而提问者是否能够让幻觉和自己的现实一致,很大程度取决于提问者自己对产生内容的检查能力。
基于这个认知,他认为,所有想要将LLM的能力拟人化的尝试都只是人类的一厢情愿,将思考、想法、推理和自我批评等拟人化概念强加在LLM上都是徒劳的。
人类应该在认清LLM能力的本质基础之上,将它当作一个「补充人类认知的矫正器」,而不是潜在的替代人类智能的工具。
当然,讨论这种问题的场合永远少不了马老板的身影:「人生不过就是一场梦」。

感觉下一句他就要说,我们也只是生活在矩阵模拟之中????????

Karpathy:LLM不存在「幻觉问题」,LLM助手才有
对于大模型饱受诟病的幻觉问题,Karpathy具体是如何看的呢?

我们用「提示」来引导这些「梦」,也正是「提示」开启了梦境,而大语言模型依据对其训练文档的模糊记忆,大部分情况下都能引导梦境走向有价值的方向。
只有当这些梦境进入被认为与事实不符的领域时,我们才会将其称为「幻觉」。这看起来像是一个错误,但其实只是LLM本就擅长的事情。
再来看一个极端的例子:搜索引擎。它根据输入的提示,直接返回其数据库中最相似的「训练文档」,一字不差。可以说,这个搜索引擎存在「创造力问题」,即它永远不会提供新的回应。

「大模型100%在做梦,因此存在幻觉问题。搜索引擎则是完全不做梦,因此存在创造力问题」。
说了这么多,我明白人们「真正」关心的是,不希望LLM助手(ChatGPT等产品)产生幻觉。大语言模型助手远比单纯的语言模型复杂得多,即使语言模型是其核心。
有很多方法可以减轻AI系统的幻觉:使用检索增强生成(RAG),通过上下文学些将做梦更准确回溯在真实数据上,这可能是最常见的一种方法。另外,多个样本之间的不一致性、反思、验证链;从激活状态中解码不确定性;工具使用等等,都是热门且有趣的研究领域。
总之,虽然可能有些吹毛求疵,,但LLM本身不存在「幻觉问题」。幻觉并非是缺陷,而是LLM最大的特点。真正需要解决幻觉问题的是大语言模型助手,而我们也应该着手解决这一问题。
来自亚利桑那州立大学的AI科学家Subbarao Kambhampati教授,把自己的研究总结成了一篇X上的长文。
他认为产生不同的认知(包括幻觉)就是LLM本质能力,所以不应该对于LLM产生过于理想化的期待。

链接地址:https://twitter.com/rao2z/status/1718714731052384262
在他看来,人类应该将LLM视为强大的认知「模拟器」,而不是人类智能的替代品。
LLM本质上是一个令人惊叹的巨大的外部非真实记忆库,如果使用得当,可以作为人类强大的认知「模拟器」。
而对于人类来说,想要发挥LLM的作用,关键是如何有效地利用LLM,而不是在这个过程中不断用拟人化的企图来自欺欺人。
人类对于LLM最大的错觉就是我们不断地将LLM与人类智能相混淆,努力地将思考、想法、推理和自我批评等拟人化概念套在LLM之上。
这种拟人化是相当徒劳的——而且,正如很多研究中展现的那样——甚至会适得其反并具有误导性。
而从另一个角度说,如果我们不将「通过LLM开发出达到人类水平的AI系统」设定为唯一目标,就不用天天批判自回归LLM非常差劲(比如LeCun教授)。

LLM是可以非常有效地补充认知的「模拟器」,并没有天然包含人类的智力。
LLM在某些事情上能比人类做得好太多了,比如快速概括,归纳总结。
但是在做很多其他事情的能力上比人类又差太多了,比如规划、推理、自我批评等。
人类真正需要的也许是:
1.充分利用LLM的优势。这可以在LLM产品架构中加入人类或者其他具有推理能力的工具来强化LLM的优势。
2. 在某种程度上,人类水平的智能仍然是目前值得追寻的圣杯,保持开放的研究途径,而不是仅仅是堆叠算力,扩大自回归架构。
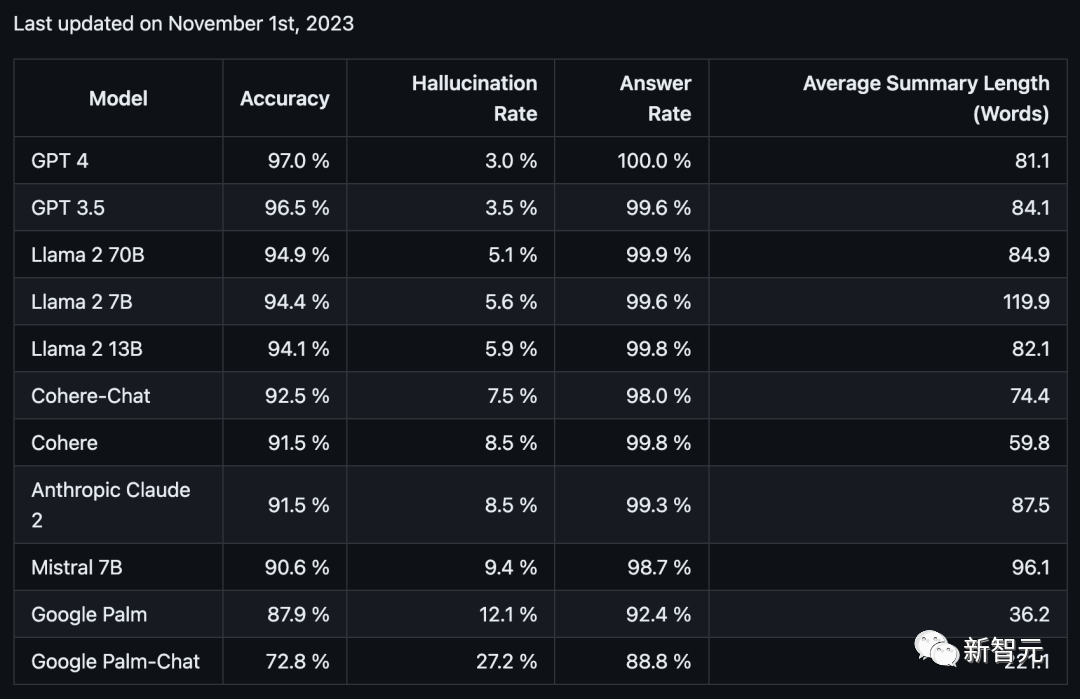
前段时间,一个名为Vectara的机构,在GitHub推出了一个大模型幻觉排行榜。
结果显示,在总结短文档方面,GPT-4的表现最为优异,而Google PaLM的两款模型直接垫。
其中,GPT-4的准确率为97.0%,幻觉率为3.0%,回答率为100.0%。Palm-Chat 2的准确率为72.8%,幻觉率高达27.2%,回答率为88.8%。
不过,这个榜单一出来,受到了许多业内人士的质疑。
OpenAI联合创始人兼研究员John Schulman曾在一次演讲——「RL和Truthfulness – Towards TruthGPT」,探讨了幻觉问题。

根据Schulman的说法,幻觉大致可以分为两种类型:
- 模型猜测错误
- 模式完成行为:语言模型无法表达自己的不确定性,无法质疑提示中的前提,或者继续之前犯的错误。
语言模型代表一种知识图谱,其中包含来自其自身网络中训练数据的事实,因此「微调」可以理解为学习一个函数,该函数在该知识图谱上运行并输出token预测。
举个例子,微调数据集可能包含「星球大战属于什么类型影片」这个问题,以及答案「科幻」。
如果这些信息已经在原始训练数据中,即它是知识图谱的一部分,那么模型不会学习新信息,而是学习一种行为——输出正确答案。这种微调也被称为「行为克隆」。

但是,如果答案不是原始训练数据集的一部分(也不是知识图谱的一部分),即使网络不知道答案,它便会学习回答。
使用实际上正确但不在知识图谱中的答案进行微调,从而教会网络编造答案——即产生「幻觉」。相反,用不正确的答案进行训练会导致网络隐瞒信息。
「LLM 是一个造梦机」。多么美妙的一句话。如果我们人类也生活在更高维度创造者构造的梦境中,那么LLM将来是否也能递归地创造出做梦的机器?


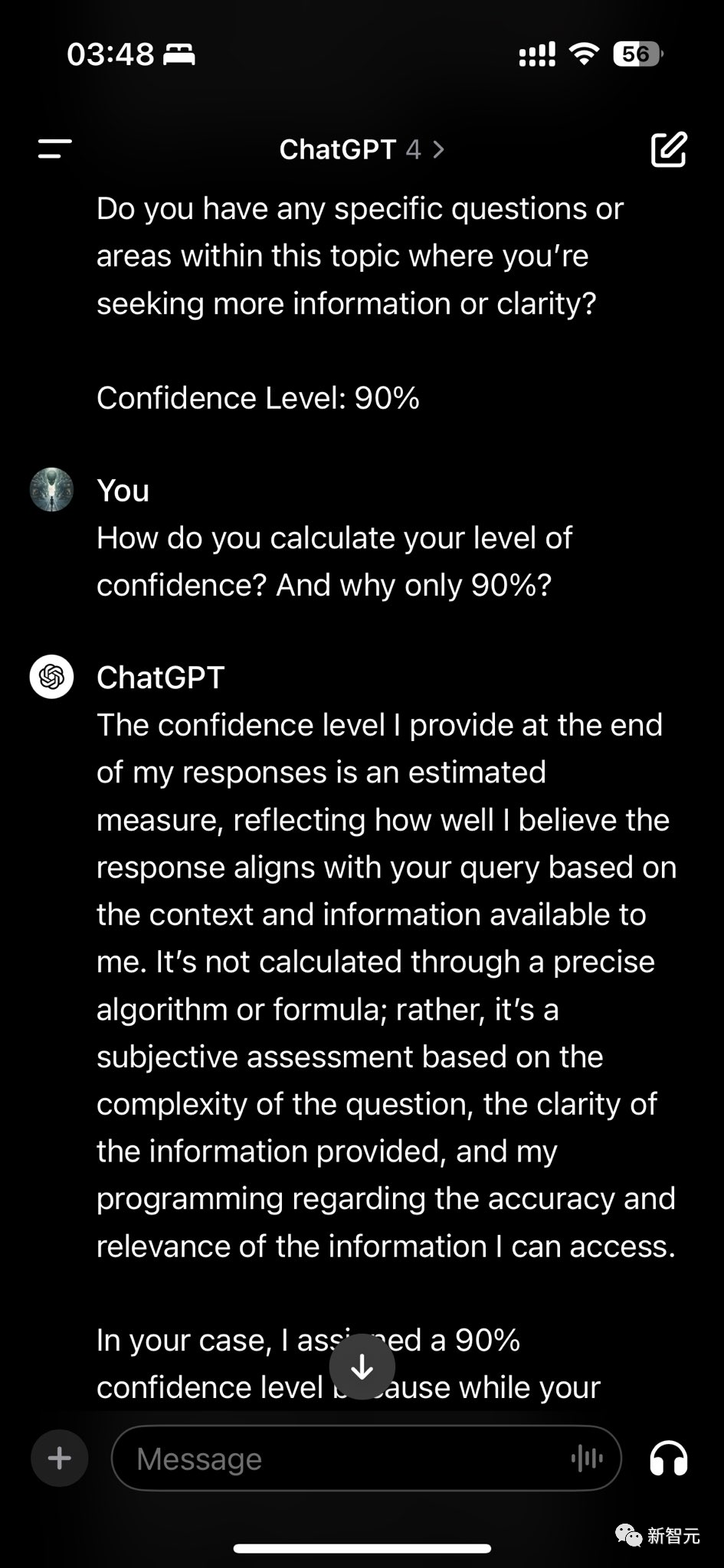
另一位网友分享了他要求ChatGPT给自己的回复进行置信度评分时,ChatGPT给了90%,并且解释了原因:

我在回复末尾提供的置信度是一个估计值,反映了根据我所掌握的上下文和信息,我认为回复与您的询问的吻合程度。它不是通过精确的算法或公式计算出来的,而是根据问题的复杂性、所提供信息的清晰度以及我对所能获取信息的准确性和相关性的编程进行的主观评估。
其实对于幻觉的讨论本质上就是对于「真理」的讨论,也许并没有什么东西是绝对客观的「真理」。

当所需数据已经存可用时,并不总是需要搜索事实。然而,LLM面临的挑战在于其学习过程,这通常涉及一种「破坏性」数据压缩。解决这个问题——减少数据丢失,不仅能缓解幻觉问题,还能减少对大量训练数据集的需求。
事实上,我们的最终目标不仅仅是创造更多的LLM,而是实现真正的智能。虽然LLM通过语言理解提供了一瞥,但它们的根本缺陷是学习过程损害了数据完整性。理想的架构应该是在学习过程中保留数据,保持对原始信息的忠实,同时还能让模型发展和完善其智能。我假设这样的架构可能涉及复制数据而不是压缩数据。

每个LLM都是一个不可靠的叙述者,就其架构的本质而言,它是不可逆转的。

对于大模型幻觉问题的解释,你赞同Karpathy的看法吗?
参考资料:
https://twitter.com/karpathy/status/1733299213503787018
https://twitter.com/DrJimFan/status/1733308471523627089
文章来自于微信公众号 “新智元”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
