# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
啥?AI都能自己看电影大片了?
贾佳亚团队最新研究成果,让大模型直接学会了处理超长视频。
丢给它一部科幻大片《星际穿越》(片长2小时49分钟):

它“看”完之后,不仅能结合电影情节和人物轻松对电影进行点评:

还能很精准地回答出剧中所涉的细节:
例如:虫洞的作用和创造者是谁?

答:未来的智慧生物放置在土星附近,用于帮助人类进行远距离星际穿越。
男主库珀是如何将黑洞中的信息传递给女儿墨菲?

答:通过手表以摩斯密码的方式传递数据。
啊这,感觉电影博主的饭碗也要被AI抢走了。

这就是最新多模态大模型LLaMA-VID,它支持单图、短视频和长视频三种输入。
对比来看,包括GPT-4V等在内的同类模型基本只能处理图像。
而背后原理更有看头。
据介绍,LLaMA-VID只通过一个非常简单的办法就达成了如上能力,那就是:
把表示每一帧图像的token数量,压缩到仅有2个。

具体效果如何以及如何实现?一起来看。
对于电影来说,除了精准回答所涉细节,LLaMA-VID也能对角色进行十分准确的理解和分析。
还是《星际穿越》,我们让它看完后分析米勒星球上相对地球时间的快慢及原因。
结果完全正确:
LLaMA-VID表示是因为米勒星球在黑洞附近,导致1小时相当于地球7年。

再丢给它时长近俩小时的《阿甘正传》。

对于“珍妮对于阿甘有何意义?”这一问题,LLaMA-VID的回答是:
孩童时期的朋友,后来成为阿甘的妻子,是阿甘生活和心灵的慰藉。

对于阿甘在战争及退伍后的事件也能进行分析,且回答也很到位:
丹中尉责怪阿甘救了自己,因为这让他无法战死沙场。

除了看电影,成为一个无所不知的的“电影搭子”,它也能很好地理解宣传片的意图,回答一些开放问题。
比如给它一段最近很火的GTA6预告片。

问它“这个游戏哪里最吸引你?”,它“看”完后给出的想法是:
一是游戏场景和设置非常多(从赛车、特技驾驶到射击等),二是视觉效果比较惊艳。

哦对了,LLaMA-VID还能根据游戏中的场景和特征,推测出预告片是Rockstar游戏公司的推广:

以及认出游戏的背景城市为迈阿密(根据夜生活、海滩等信息,以及在作者提示游戏设置在佛罗里达之后)。

最后,在宣传片、时长高达2-3小时的电影这些视频材料之外,我们也来看看LLaMA-VID对最基础的图片信息的理解能力。
呐,准确识别出这是一块布料,上面有个洞:

让它扮演“福尔摩斯”也不在话下。面对这样一张房间内景照片:

它可以从门上挂了很多外套分析出房间主人可能生活繁忙/经常外出。

看得出来,LLaMA-VID对视频的准确解读正是建立在这样的图片水准之上的,但最关键的点还是它如何完成如此长时间的视频处理。
LLaMA-VID的关键创新是将每帧画面的token数量压缩到很低,从而实现可处理超长视频。
很多传统多模态大模型对于单张图片编码的token数量过多,导致了视频时间加长后,所需token数量暴增,模型难以承受。
为此研究团队重新设计了图像的编码方式,采用上下文编码(Context Token)和图像内容编码(Content Token)来对视频中的单帧进行编码。
从而实现了将每一帧用2个token表示。
具体来看LLaMA-VID的框架。
只包含3个部分:
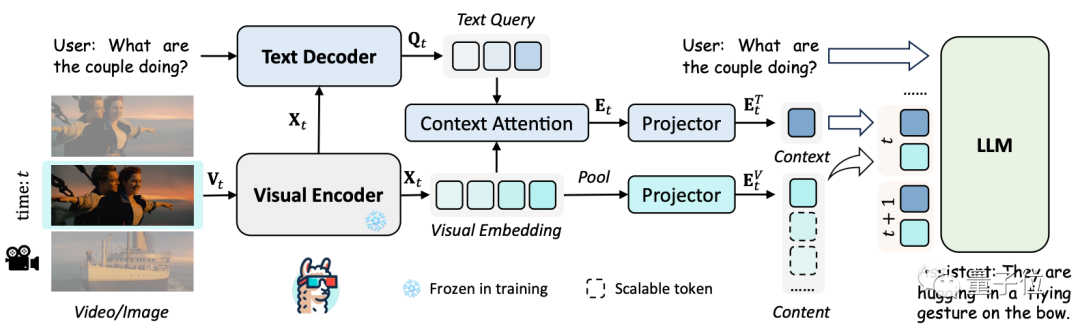
根据指令,LLaMA-VID选取单个图像或视频帧作为输入,然后从大语言模型上生成回答。
这个过程从一个可视编码器开始,该编码器将输入帧转换为可视帧嵌入。
然后文本解码器根据用户输入和图像编码器提取的特征,来生成与输入指令相关的跨模态索引(Text Query)。
然后利用注意力机制(Context Attention),将视觉嵌入中和文本相关的视觉线索聚合起来,也就是特征采样和组合,从而生成高质量的指令相关特征。
为了提高效率,模型将可视化嵌入样本压缩到不同token大小,甚至是一个token。
其中,上下文token根据用户输入的问题生成,尽可能保留和用户问题相关的视觉特征。
图像内容token则直接根据用户指令对图像特征进行池化采样,更关注图像本身的内容信息,对上下文token未关注到的部分进行补充。
文本引导上下文token和图像token来一起表示每一帧。
最后,大语言模型将用户指令和所有视觉token作为输入,生成回答。
而且这种token的生成方法很简单,仅需几行代码。

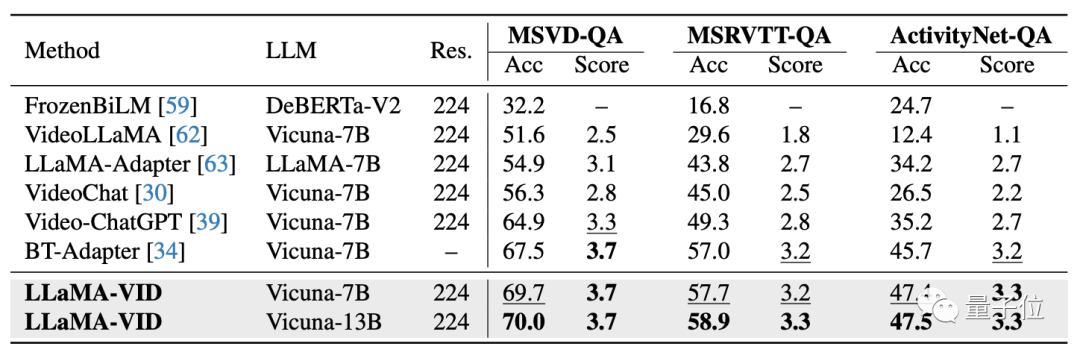
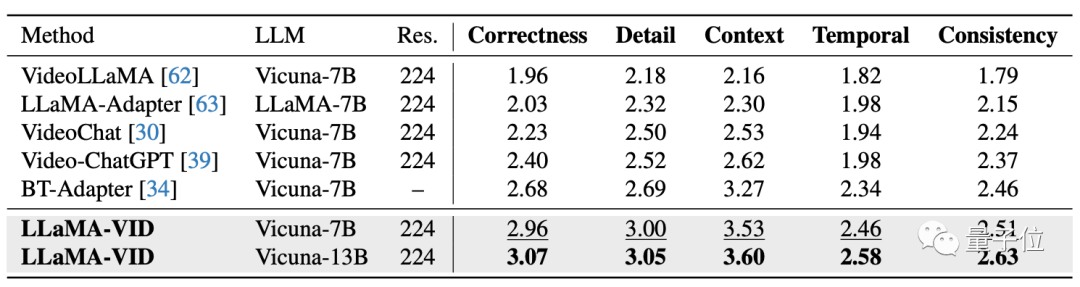
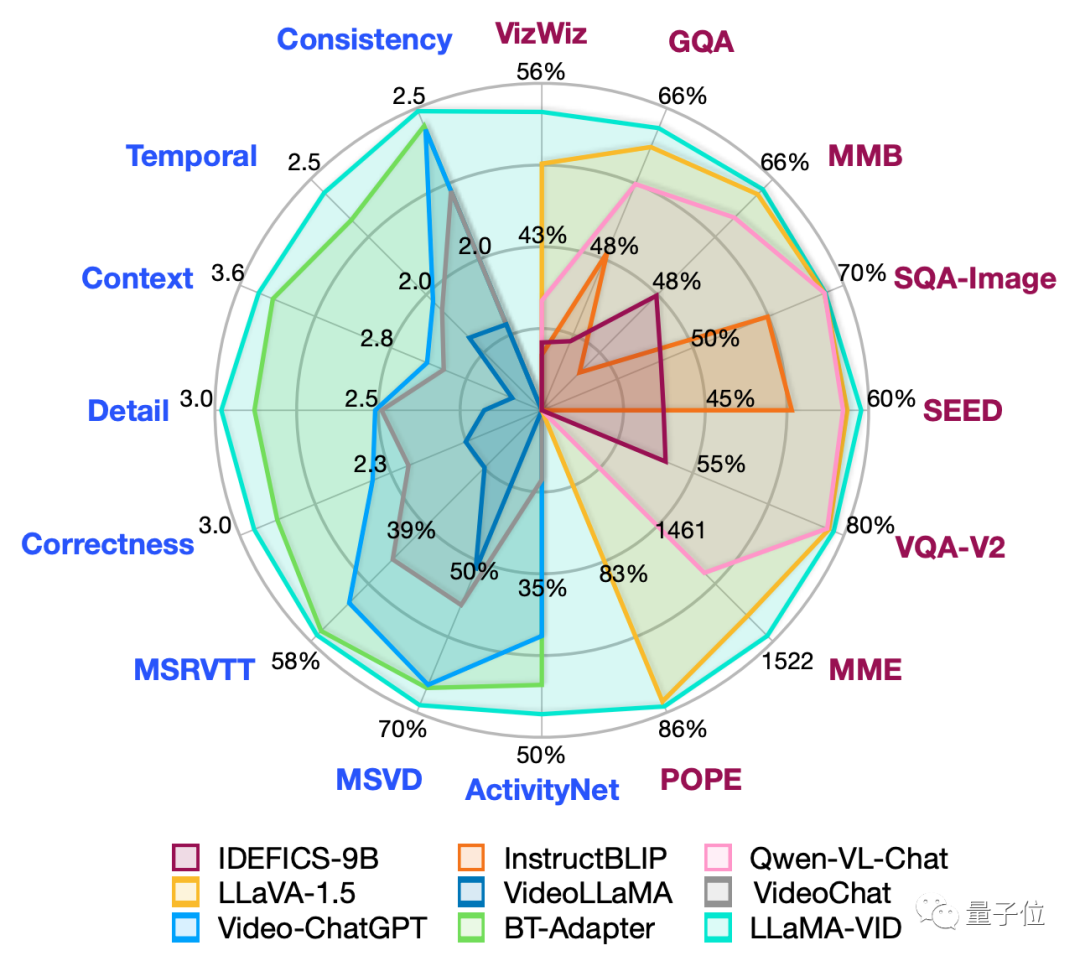
实验结果方面,LLaMA-VID在多个视频问答和推理榜单上实现SOTA。
仅需加入1个上下文token拓展,LLaMA-VID在多个图片问答指标上也能获得显著提升。
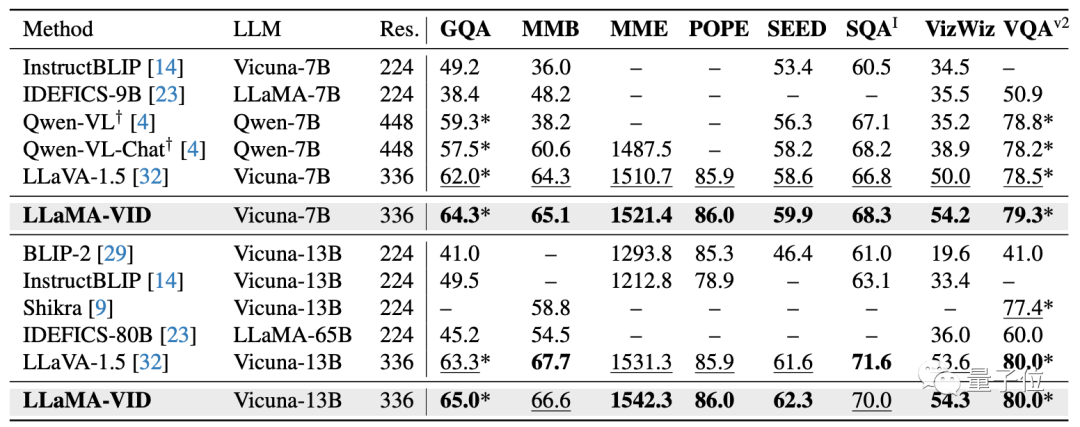
在16个视频、图片理解及推理数据集上,LLaMA-VID实现了很好效果。
在GitHub上,团队提供了不同阶段的所有微调模型,以及第一阶段的预训练权重。
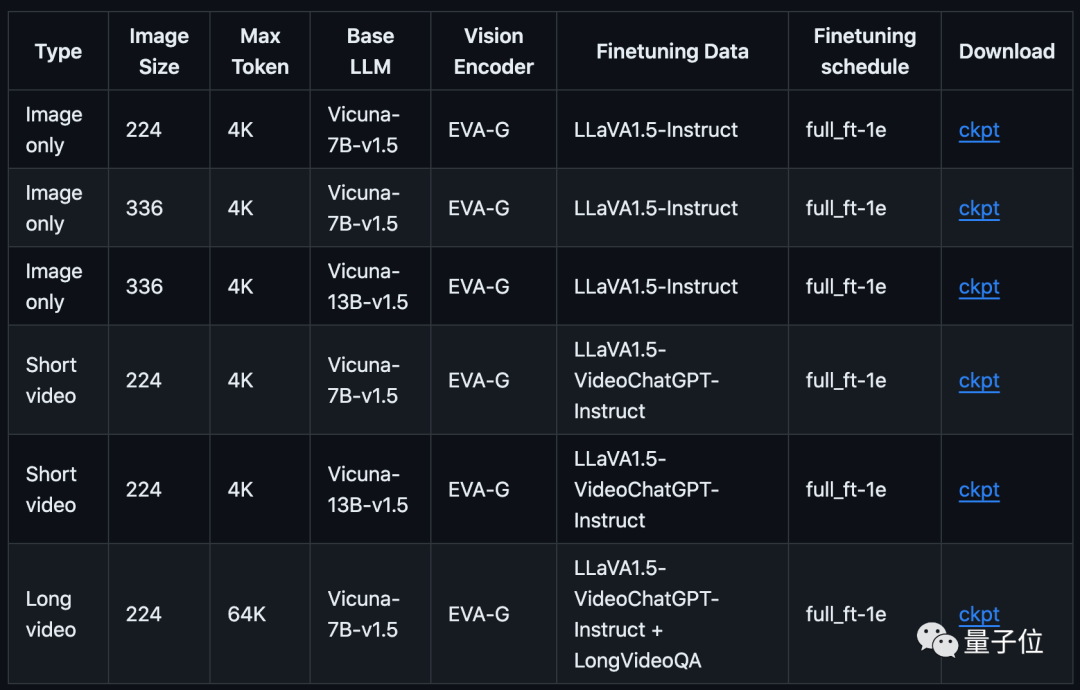
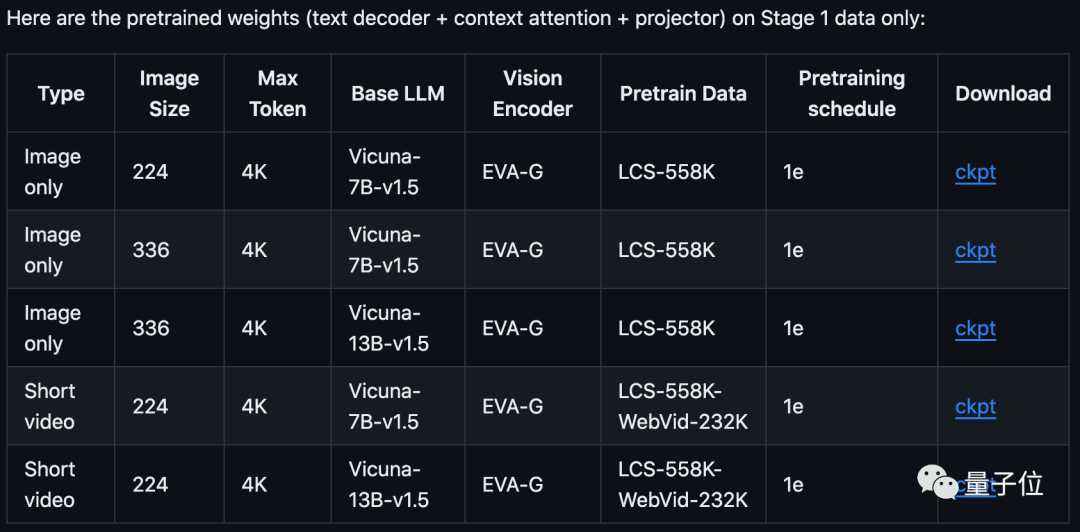
具体训练包括3个过程:特征对齐、指令微调、长视频微调(相应步骤可参考GitHub)。
此外,LLaMA-VID还收集了400部电影并生成9K条长视频问答语料,包含电影影评、人物成长及情节推理等。
结合之前贾佳亚团队所发布的长文本数据集LongAlpaca-12k(9k条长文本问答语料对、3k短文本问答语料对), 可轻松将现有多模态模型拓展来支持长视频输入。
值得一提的是,今年8月开始贾佳亚团队就发布了主攻推理分割的LISA多模态大模型。
10月还发布了长文本开源大语言模型LongAlpaca(70亿参数)和超长文本扩展方法LongLoRA。
LongLoRA只需两行代码便可将7B模型的文本长度拓展到100k tokens,70B模型的文本长度拓展到32k tokens。
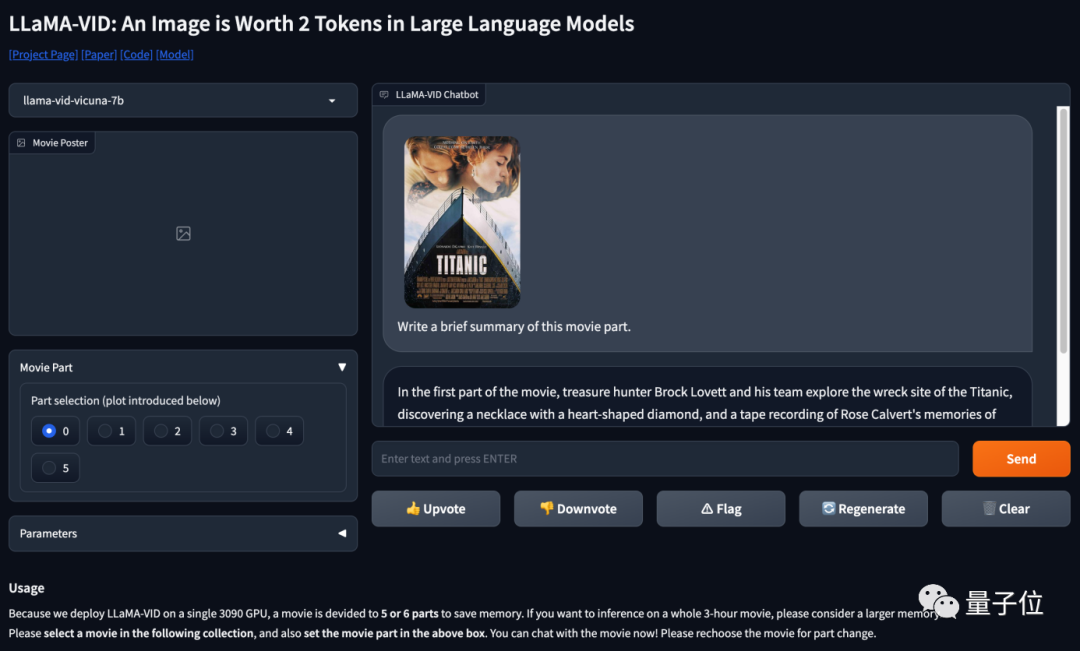
最后,团队也提供了demo地址,可自己上传视频和LLaMA-VID对话(部署在单块3090,需要的小伙伴可以参考code用更大的显存部署,直接和整个电影对话)。
看来,以后看不懂诺兰电影,可以请教AI试试~
论文地址:
https://arxiv.org/abs/2311.17043
GitHub地址:
https://github.com/dvlab-research/LLaMA-VID
demo地址:
http://103.170.5.190:7864/



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
