# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
发表于昨天的论文《Agent Laboratory: Using LLM Agents as Research Assistants》对于科研界具有划时代意义,过去几周才能完成的科研任务现在仅需20分钟到一两个小时左右(不同LLM),花费2-13个美金的Token即可完成!惊不惊喜,意不意外?这不仅是一篇关于AI的论文,更是AI对自身能力的一次完整展示和深度剖析。科研领域有了AI的加持进步可能会更迅猛,这个Agent Laboratory高低你都应该试一试!https://agentlaboratory.github.io/
在当前的学术界,我们正面临着一些尖锐的问题:论文数量爆炸性增长但质量参差不齐,重复性研究浪费大量资源,真正的创新性成果却越来越少。就在这个关键时刻,AMD和约翰霍普金斯大学联合研究团队带来了一个震撼性的答案 - 他们开发的Agent Laboratory不仅能执行完整的科研流程,更能对自己的研究过程进行系统性总结和深度反思。

这个突破性发现的意义远超出技术层面:
更令人震撼的是,下面这篇10页的研究报告正是由Agent Laboratory自己撰写的。这不禁让我们思考:在不久的将来,学术界的格局会发生怎样的变革?那些为了凑数而产出的"水论文"还有生存空间吗?

研究团队提出的最大创新在于构建了一个由多个专业化AI智能体组成的科研团队。这个团队包括:博士生智能体(负责文献综述和实验设计)、博士后智能体(负责指导和审查)、机器学习工程师智能体(负责代码实现)以及教授智能体(负责评估和反馈)。每个智能体都有其特定的角色和职责,通过精心设计的提示词系统进行协作。这种多智能体协作的方式模拟了真实科研团队的工作模式,不同于传统的单一模型方法。研究表明,这种协作模式能够显著提高研究质量,因为每个智能体都能专注于自己最擅长的领域,同时又能通过有效的沟通来整合各自的专长。
研究团队的创新不仅体现在团队构成上,更体现在系统的技术架构设计上。Agent Laboratory采用了三阶段研究流程,每个阶段都配备了专门的工具和方法:
研究团队的创新不仅体现在团队构成上,更体现在系统的技术架构设计上。
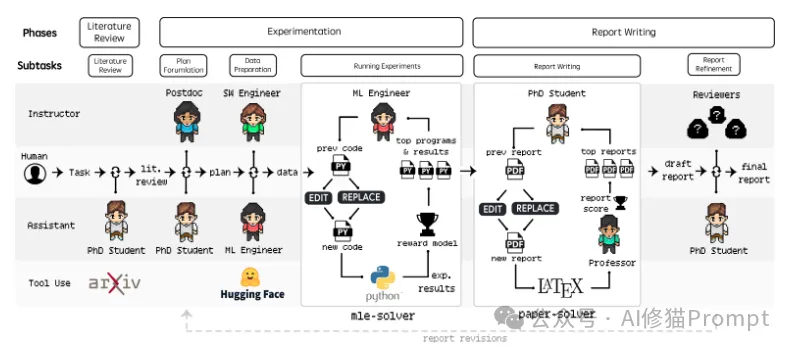
Agent Laboratory的工作流程图:该系统分为三个主要阶段(Literature Review、Experimentation、Report Writing)和多个子任务。每个阶段都由专门的AI智能体负责:
图中的工作流展示了人类研究者如何与各个智能体协作:从提出研究任务开始,经过文献评审、实验计划、数据准备、实验执行,最终到报告撰写和修订。系统集成了多个专业工具(arXiv、Hugging Face、Python、LaTeX等),确保每个阶段都能高效完成。
具体来说,每个阶段都配备了专门的工具和方法:
1.文献综述阶段采用arXiv API进行文献检索,通过专门的文献分析智能体进行内容提取和总结,不仅能自动识别研究空白和潜在贡献点,还能确保文献综述的全面性和准确性。
2.实验阶段使用创新的mle-solver工具执行机器学习实验。这个工具支持两种代码生成命令:REPLACE(完全重写)和EDIT(局部修改),并包含自动错误修复机制,最多尝试三次修复。在MLE-bench基准测试中,该工具表现优异,获得了4枚奖牌(2金1银1铜)。
3.报告撰写阶段则依靠paper-solver工具自动生成研究报告,能够有效整合实验结果和文献综述内容,并确保输出符合学术会议投稿标准的格式要求。
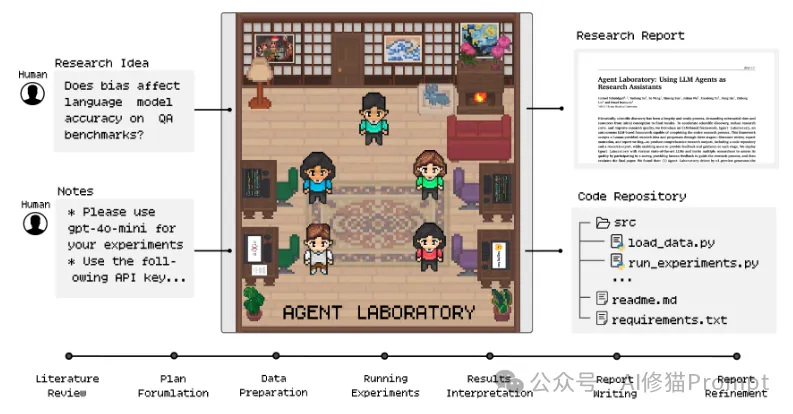
Agent Laboratory的主界面:系统采用了富有创意的像素风格设计,将AI研究助手团队可视化为一个虚拟研究室。左侧显示研究问题("Does bias affect language model accuracy on QA benchmarks?")和系统配置信息,中央是各个AI智能体的虚拟形象,右侧展示项目文件结构。这种直观的可视化设计让复杂的研究流程变得更加友好和易于理解。
研究团队设计了一个完整的五阶段科研流程,每个阶段都有明确的目标和评估标准:
1.文献综述阶段:博士生智能体负责检索和总结相关文献,通过特定的提示词模板来确保文献综述的全面性和准确性。这个阶段不是简单的文献堆砌,而是要求智能体理解研究脉络,识别研究空白。
2.计划制定阶段:博士后智能体根据文献综述结果,指导博士生智能体制定详细的研究计划。这个过程包括实验设计、方法选择和预期结果分析。
3.数据准备阶段:机器学习工程师智能体负责实现具体的代码,包括数据预处理、模型构建和训练过程。这个阶段特别强调代码的可复现性和效率。
4.结果解释阶段:博士后智能体和博士生智能体共同分析实验结果,提出见解和结论。这个阶段需要深入的统计分析和科学推理。
5.论文撰写阶段:整个团队协作完成研究论文的撰写,包括多轮修改和完善。
研究中最具创新性的技术之一是设计了一套高效的智能体间通信机制。这个机制包括:
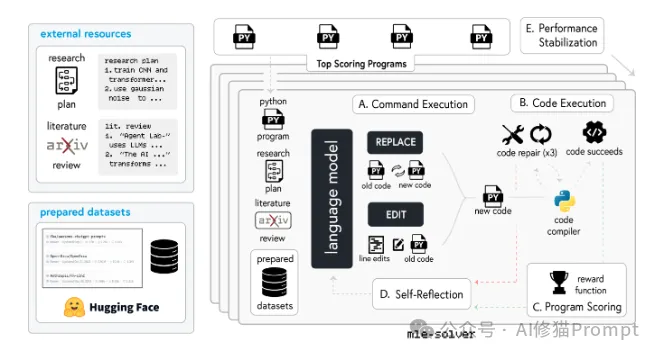
mle-solver的系统架构:该工具是Agent Laboratory的核心组件之一,负责代码生成和实验执行。系统包含五个主要模块:
1.外部资源整合(External Resources):
2.命令执行(Command Execution):
3.代码执行(Code Execution):
4.程序评分(Program Scoring):
5.性能稳定(Performance Stabilization):
这种模块化设计确保了代码生成和实验执行的高效性和可靠性,是Agent Laboratory能够产出高质量研究成果的关键技术保障。
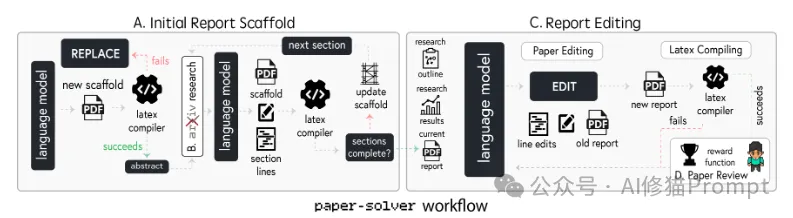
paper-solver的工作流程:该工具负责自动化论文生成过程,包含两个主要阶段:
A. 初始报告框架生成(Initial Report Scaffold):
C. 报告编辑(Report Editing):
这种设计确保了生成的研究报告既符合学术规范,又能准确反映研究成果。系统支持迭代改进,通过多轮编辑和审阅来提升论文质量。
在具体研究任务中,Agent Laboratory展现出了令人瞩目的分析能力。以一个典型的10分类任务为例:
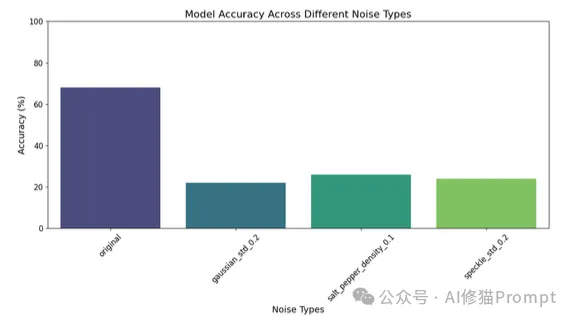
模型在不同噪声类型下的准确率表现:即使在充满挑战的噪声环境下,系统仍然保持了显著的性能优势:
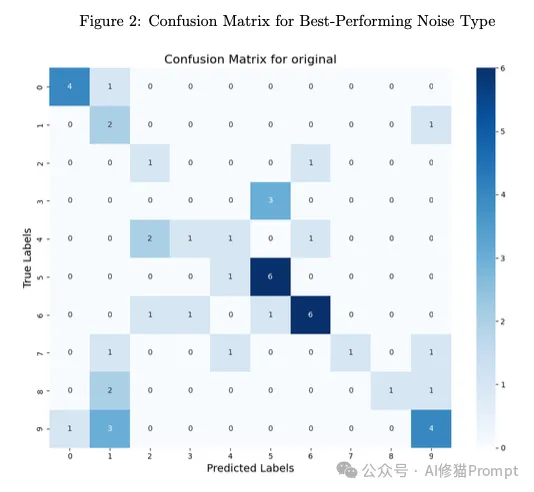
最佳性能条件下的混淆矩阵分析:深入的错误分析揭示了系统的精确决策能力:
这些结果不仅展示了Agent Laboratory的技术实力,更说明AI已经具备了处理复杂研究任务的能力。系统不仅能给出结果,还能提供详细的性能分析,这对于科研工作的可解释性和可靠性至关重要。
研究团队对Agent Laboratory进行了全面的性能评估,从多个维度展示了系统的有效性:
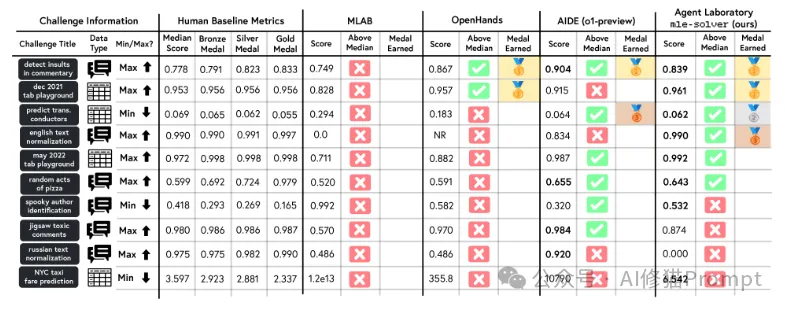
Agent Laboratory在MLE-bench基准测试中的表现:与其他系统(MLAB、OpenHands、AIDE)相比,mle-solver展现出更优秀的性能:获得4枚奖牌(2金1银1铜),在10个基准测试中有6个超过人类中位数表现。这个结果证明了系统在实际机器学习任务中的有效性和可靠性。
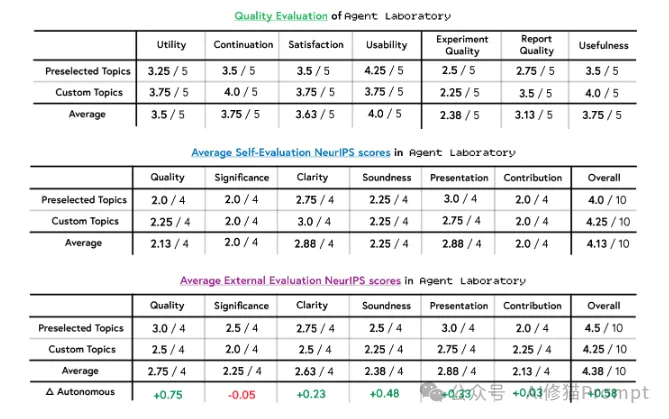
Agent Laboratory的多维度评估结果:评估包括三个层面:
系统在多个关键指标上表现出色:
特别值得注意的是,在自定义主题研究中,系统表现更为出色:
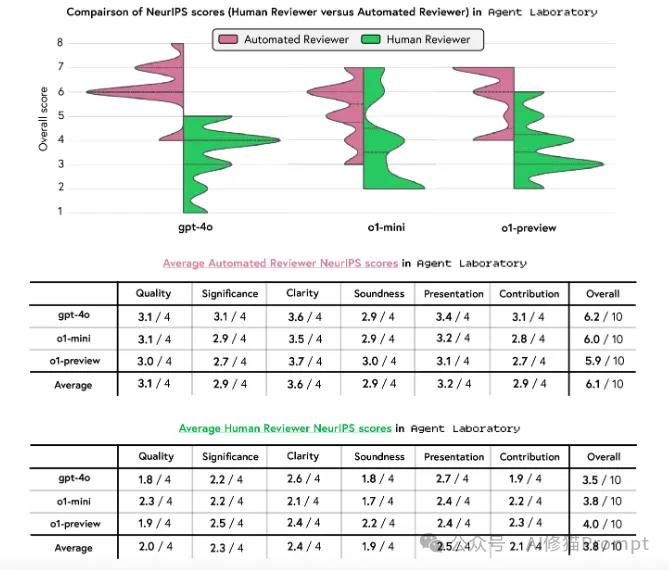
自动评审与人类评审的对比:系统的自动评审功能与人类评审表现出高度一致性:
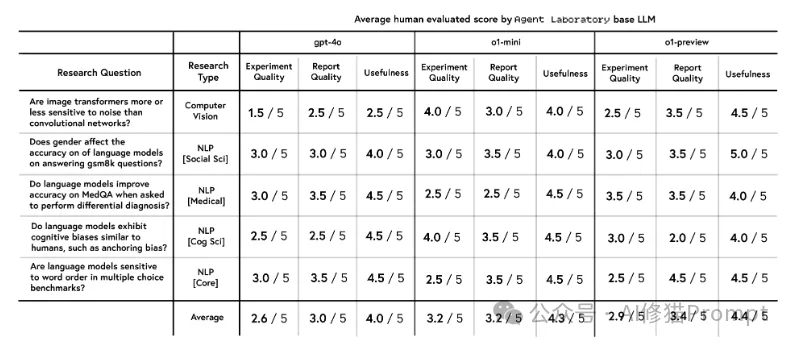
不同语言模型在各类研究任务上的表现:评估覆盖了多个研究领域:
o1-preview后端在大多数任务中表现最佳:
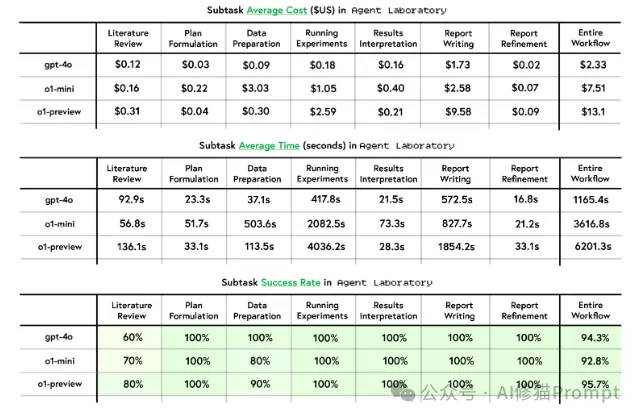
Agent Laboratory的运行效率指标:评估包括三个关键维度:
1.成本分析(美元):
2.时间消耗(秒):
3.成功率:
特别值得注意的是,各个子任务的成功率都很高,大多数达到100%,只有文献综述阶段略低(60-80%)。
这些实验结果对Prompt工程师具有重要的启示:
1.模型选择:不同后端模型在不同任务上表现各异,需要根据具体需求选择合适的模型。例如,当注重成本效益时,gpt-4o是更好的选择;而当追求更高的输出质量时,o1-preview可能更适合。
2.人机协作:Co-Pilot模式的成功表明,在设计AI系统时,应该预留适当的人类干预接口,这样可以显著提升系统输出的质量。
3.错误处理:mle-solver的自动错误修复机制提供了一个很好的范例,说明如何设计健壮的AI系统。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
