# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文共同一作为葛俊岐 (清华大学本科生),陈子熠 (清华大学本科生),林锦涛 (香港大学博士生),祝金国 (上海 AI Lab 青年研究员)。本文的通讯作者是朱锡洲,他的研究方向是视觉基础模型和多模态基础模型,代表作有 Deformable DETR、DCN v2 等。
随着语言大模型的成功,视觉 - 语言多模态大模型 (Vision-Language Multimodal Models, 简写为 VLMs) 发展迅速,但在长上下文场景下表现却不尽如人意,这一问题严重制约了多模态模型在实际应用中的潜力。
为解决这一问题,清华大学,香港大学和上海 AI Lab 联合提出了一种新的用于多模态大模型的位置编码方法 ——Variable Vision Position Embedding (V2PE) ,取得多模态大模型在长上下文场景下的新突破。

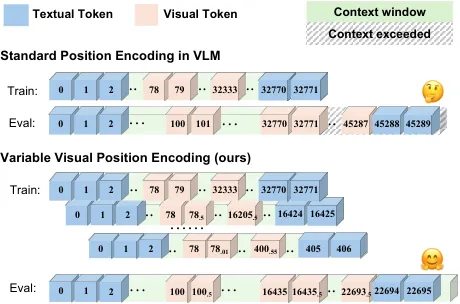
位置编码是多模态大模型中的关键技术,用于让模型理解输入序列的相对位置关系。它使得 VLMs 能够理解词语在句子中的位置,并识别图像块在原图中的二维位置。然而,现有的多模态模型通常在图像 token 上沿用文本模型的位置编码方式,这并非最优方案。
V2PE 提出了一种为视觉 token 分配可变位置增量的新方法,有效解决了传统位置编码在处理超长上下文任务时的性能瓶颈问题。通过避免位置编码超出模型训练上下文窗口的限制,V2PE 显著提升了模型在 32K 至 1M 长度超长上下文任务中的表现。相比传统位置编码的模型,采用 V2PE 的模型在这些任务中实现了突破性改进,甚至超越了最先进的闭源大模型。
V2PE 工作有以下贡献:
在人工智能领域,视觉 - 语言模型 因其在多模态任务中的出色表现而备受关注。然而,在处理视频、高分辨率图像或长篇图文文档等长上下文场景时,其泛化能力却显著下降,这限制了它们在实际应用中的潜力,并影响了用户体验的进一步提升。
V2PE 旨在解决的核心问题在于:为什么 VLMs 在长上下文场景下表现不佳,以及如何提升它们在长序列多模态理解与推理上的能力?
为了研究 VLMs 为什么在长上下文场景表现不佳,研究团队通过构建大规模的长上下文多模态数据集,系统地评估和分析 VLMs 的能力,在这一过程中,他们意识到位置编码策略在 VLMs 的性能中起着至关重要的作用。
传统的 VLMs 位置编码通常不区分文本 token 和图像 token,并在训练中使用固定的编码规则。然而,文本 token 属于一维数据,位置编码仅需传达先后顺序;图像 token 则为二维数据,位置编码需传递图像块的空间位置信息,还要考虑多分辨率下缩略图与子图像块的对应关系。此外,当模型处理超出训练上下文窗口的长序列时,固定位置编码会超出模型已知范围,导致推理能力受限。
因此,作者提出了 Variable Visual Position Encoding (V2PE),这是一种新颖的位置编码方法,专门针对视觉 - 语言模型(VLMs)中的长上下文场景。V2PE 通过为视觉 token 分配更小的、可变的位置增量,有效地管理长多模态序列。
增强的长上下文多模态数据集
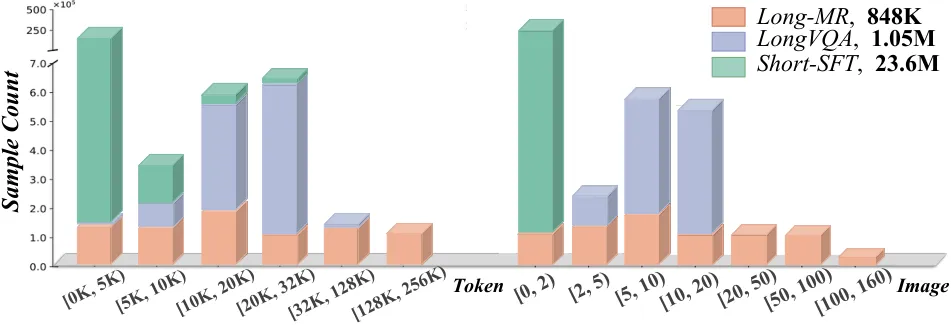
作者引入了两个增强的长上下文多模态数据集:Long Visual Question Answering (Long-VQA) 和 Long Multimodal Retrieval (Long-MR)。旨在提升 VLMs 的长上下文能力并建立评估框架。

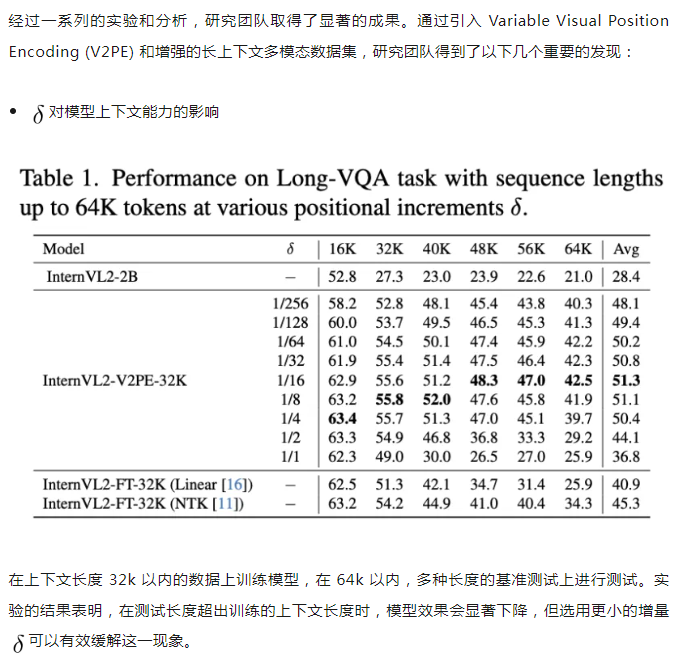
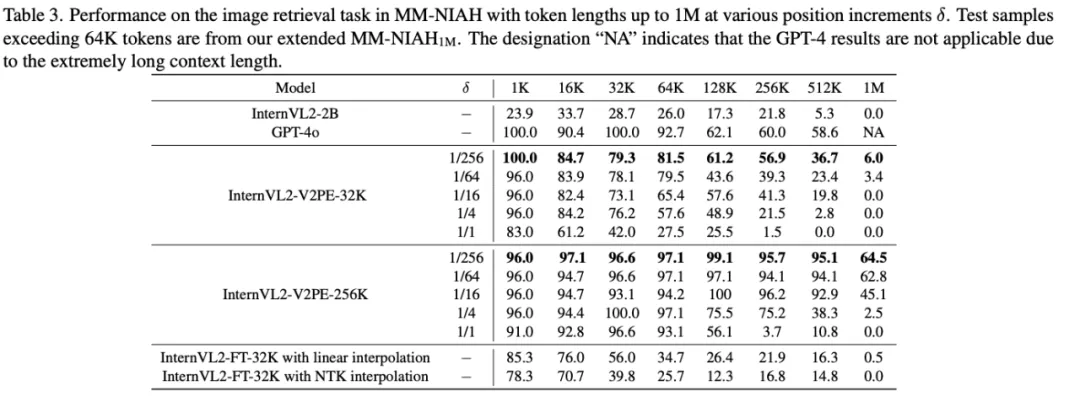
作者分别在 32k 和 256k 的训练数据上微调模型,并在长达 1M 的多种上下文长度上进行测试。实验结果表明,V2PE 在长上下文场景下的表现明显优于不加 V2PE 的模型,也优于使用插值方法的模型,甚至能超越先进的闭源大模型。
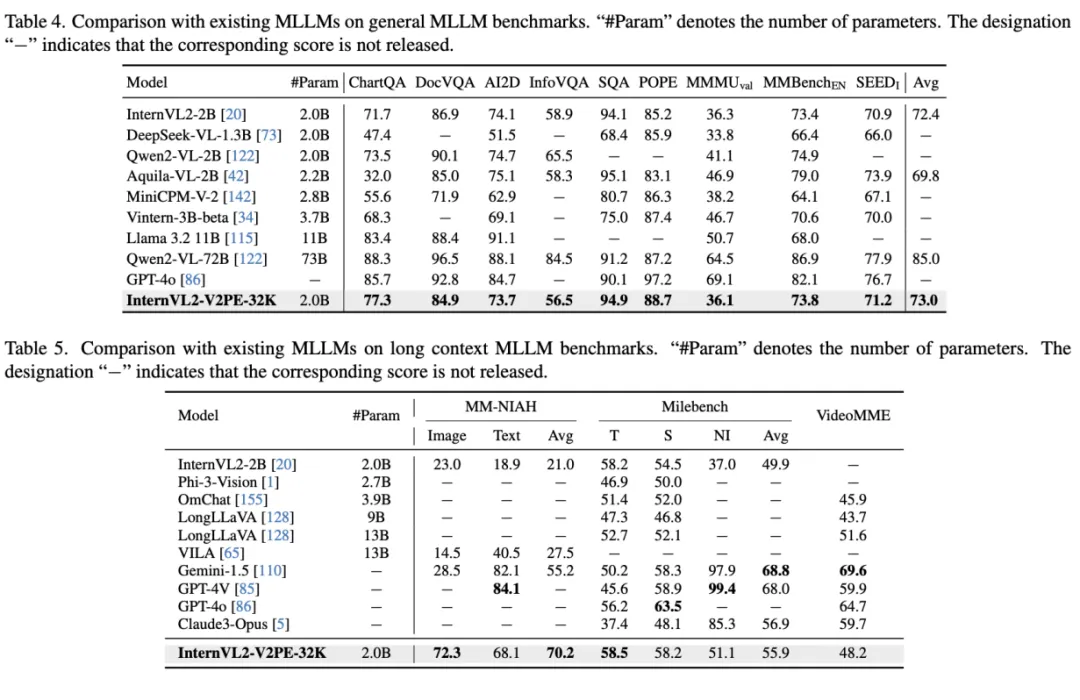
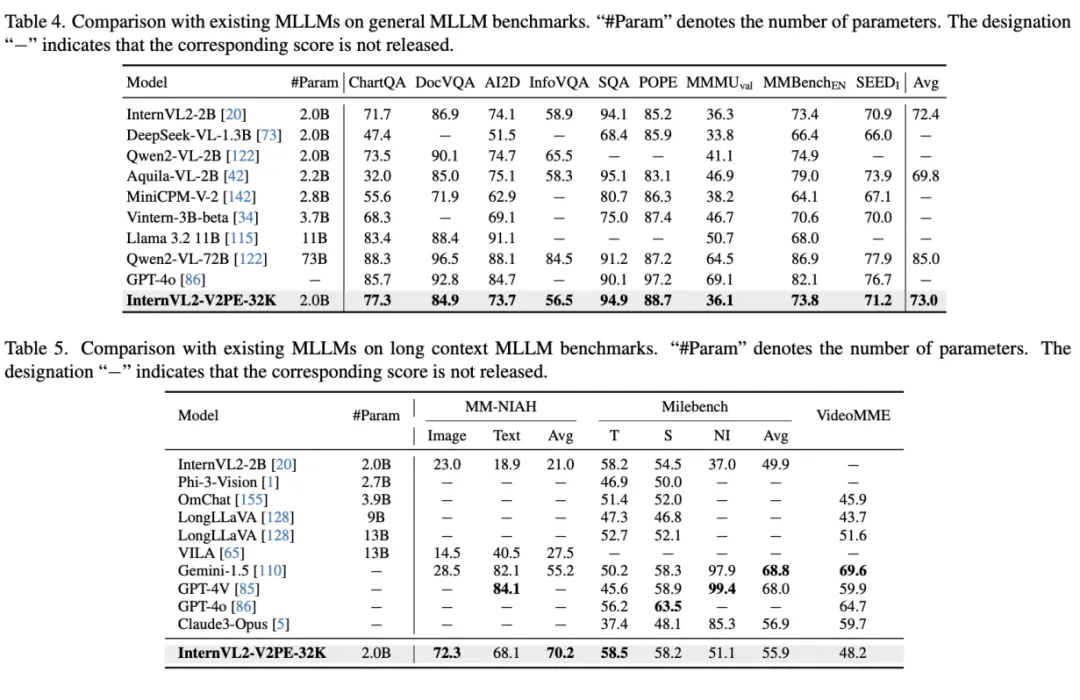
此外,作者将训练好的 V2PE 模型与其他视觉 - 语言模型在多种基准测试进行了对比,结果表明,V2PE 在长上下文多模态任务上的表现优于其他模型,证明了 V2PE 的有效性。
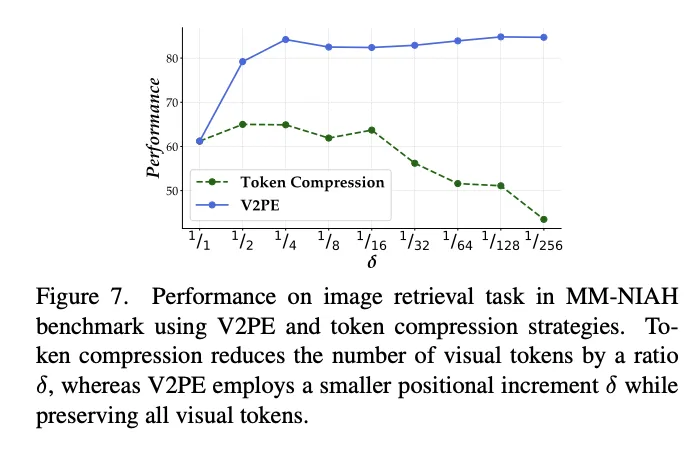

消融实验中,作者将 V2PE 方法与 token 压缩的方法以及在训练时固定视觉 token 的位置编码增量的方法进行了对比,证明了 V2PE 的优势。
在对注意力图的分析中,作者关注注意力图的尾部,即对应序列末端的问题部分的注意力图。作者发现,随着![]() 的减小,模型能更好地把注意力集中在问题对应的答案附近,证明了 V2PE 能够有效地提升模型将注意力对齐到输入序列中的关键部分的能力。
的减小,模型能更好地把注意力集中在问题对应的答案附近,证明了 V2PE 能够有效地提升模型将注意力对齐到输入序列中的关键部分的能力。
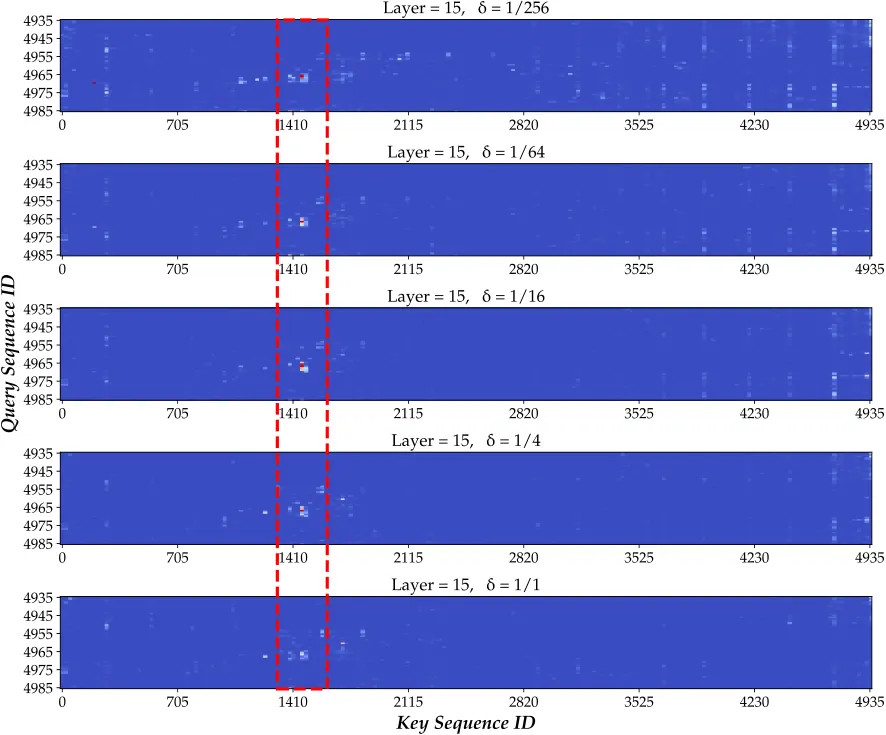
V2PE 的提出,为视觉 - 语言模型在长上下文场景下的表现提供了新的思路。通过为视觉 token 分配可变的位置增量,V2PE 有效地解决了位置编码超出模型训练上下文窗口的问题,提升了模型在长上下文场景下的表现。
作者相信,V2PE 的提出将为视觉 - 语言模型的发展带来新的机遇,为模型在长上下文多模态任务中的应用提供更多可能性。
文章来微信公众号“机器之心”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
