# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
种种迹象表明,最近OpenAI似乎发生了什么大事。
AI研究员Gwern Branwen发布了一篇关于OpenAI o3、o4、o5的文章。
根据他的说法,OpenAI已经跨越了临界点,达到了「递归自我改进」的门槛——o4或o5能自动化AI研发,完成剩下的工作!

文章要点如下——
- OpenAI可能选择将其「o1-pro」模型保密,利用其计算资源来训练o3这类更高级的模型,类似于Anthorpic的策略
- OpenAI可能相信他们已经在AI发展方面取得了突破,正在走向ASI之路
- 目标是开发一种运行效率高的超人AI,类似于AlphaGo/Zero所实现的目标
- 推理时搜索最初可以提高性能,但最终会达到极限
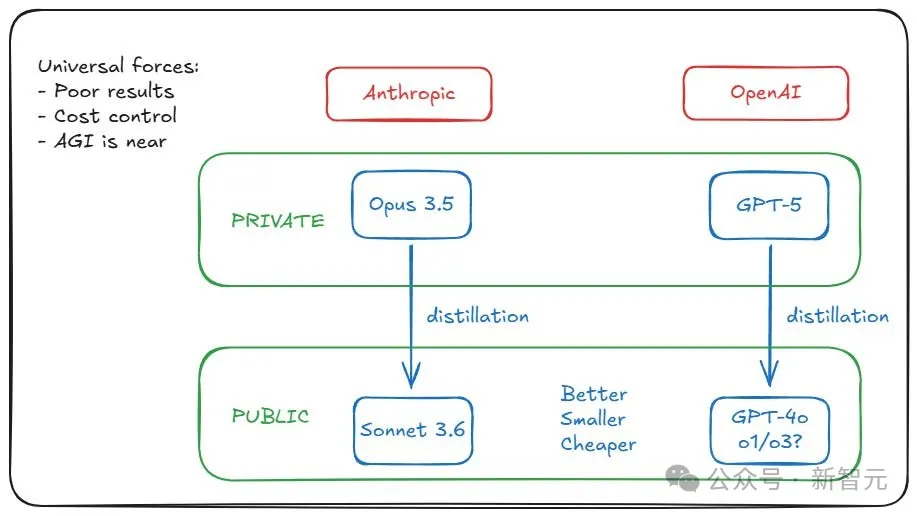
甚至还出现了这样一种传言:OpenAI和Anthropic已经训练出了GPT-5级别的模型,但都选择了「雪藏」。
原因在于,模型虽能力强,但运营成本太高,用GPT-5蒸馏出GPT-4o、o1、o3这类模型,才更具性价比。
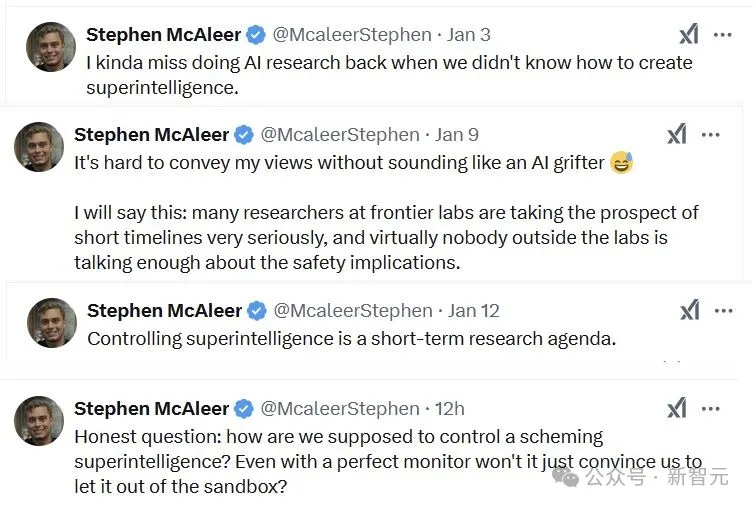
甚至,OpenAI安全研究员Stephen McAleer最近两周的推文,看起来简直跟短篇科幻小说一样——
我有点怀念过去做AI研究的时候,那时我们还不知道如何创造超级智能。
在前沿实验室,许多研究人员都非常认真地对待AI短时间的影响,而实验室之外几乎没有人充分讨论其安全影响。
而现在控制超级智能已经是迫在眉睫的研究事项了。
我们该如何控制诡计多端的超级智能?即使拥有完美的监视器,难道它不会说服我们将其从沙箱中释放出来吗?
总之,越来越多OpenAI员工,都开始暗示他们已经在内部开发了ASI。
这是真的吗?还是CEO奥特曼「谜语人」的风格被底下员工学会了?
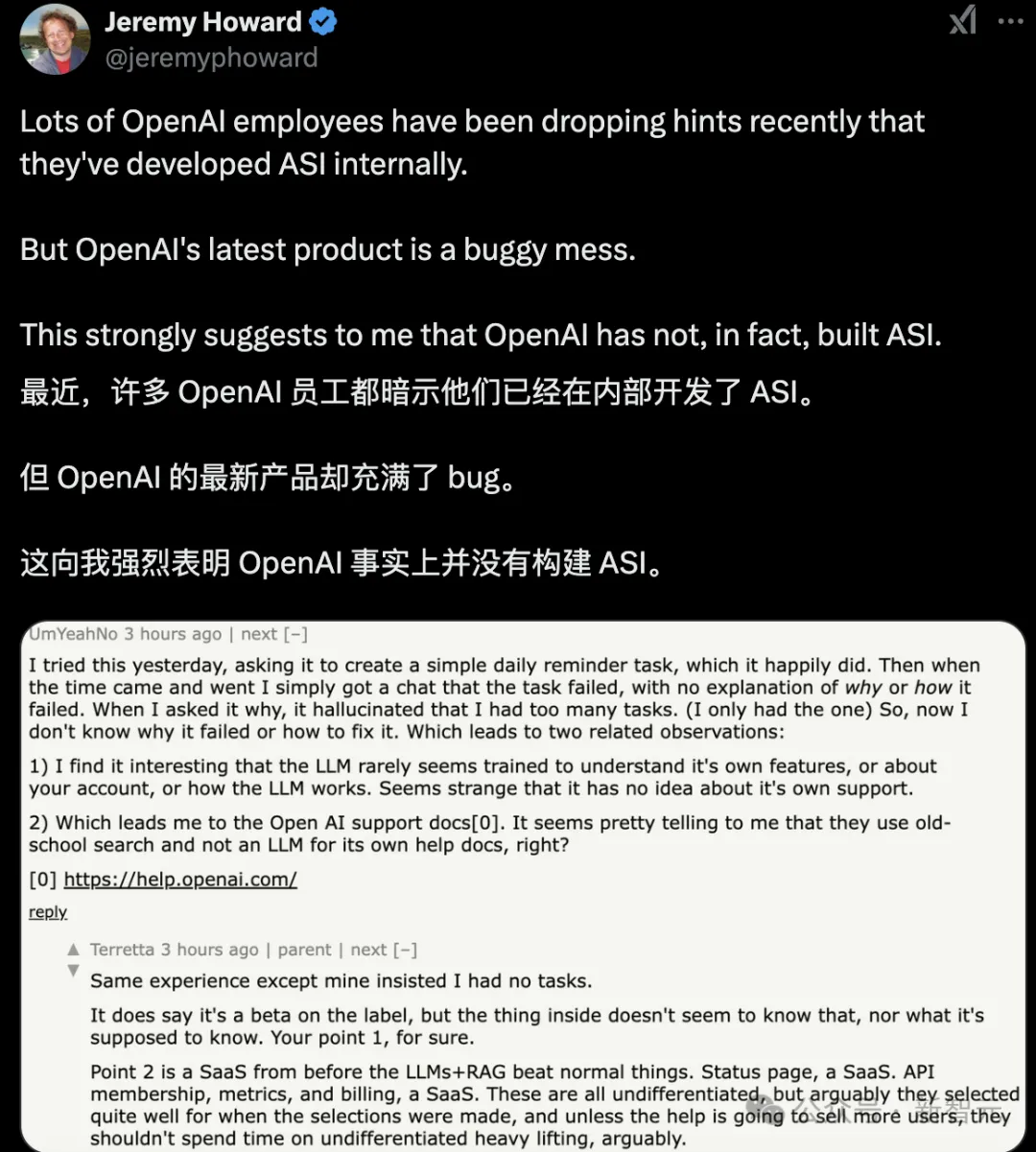
很多人觉得,这是OpenAI惯常的一种炒作手段。

但让人有点害怕的是,有些一两年前离开的人,其实表达过担忧。
莫非,我们真的已处于ASI的边缘?

超级智能(superintelligence)的「潘多拉魔盒」,真的被打开了?
OpenAI的o1和o3模型,开启了新的扩展范式:在运行时对模型推理投入更多计算资源,可以稳定地提高模型性能。
如下面所示,o1的AIME准确率,随着测试时计算资源的对数增加而呈恒定增长。
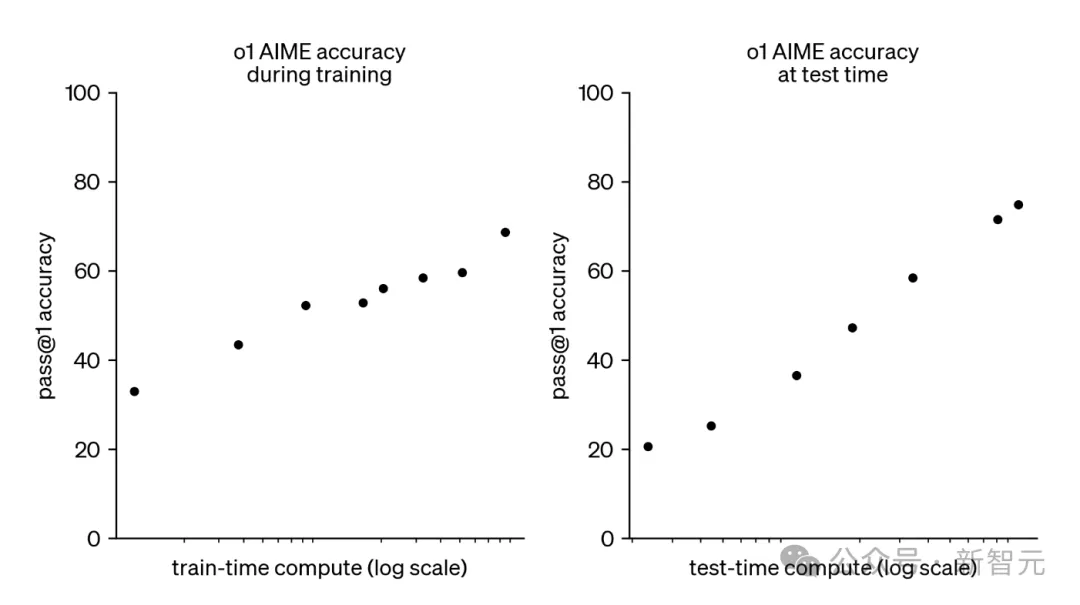
OpenAI的o3模型延续了这一趋势,创造了破纪录的表现,具体成绩如下:
根据OpenAI的说法,o系列模型的性能提升主要来自于增加思维链(Chain-of-Thought,CoT)的长度(以及其他技术,如思维树),并通过强化学习改进思维链(CoT)过程。
目前,运行o3在最大性能下非常昂贵,单个ARC-AGI任务的成本约为300美元,但推理成本正以每年约10倍的速度下降!
Epoch AI的一项最新分析指出,前沿实验室在模型训练和推理上的花费可能相似。
因此,除非接近推理扩展的硬性限制,否则前沿实验室将继续大量投入资源优化模型推理,并且成本将继续下降。
就一般情况而言,推理扩展范式预计可能会持续下去,并且将是AGI安全性的一个关键考虑因素。
那么推理扩展范式对AI安全性的影响是什么呢?简而言之,AI安全研究人员Ryan Kidd博士认为:
o1和o3的发布,对AGI时间表的预测的影响并不大。
Metaculus的「强AGI」预测似乎因为o3的发布而提前了一年,预计在2031年中期实现;然而,自2023年3月以来,该预测一直在2031到2033年之间波动。
Manifold Market的「AGI何时到来?」也提前了一年,从2030年调整为2029年,但最近这一预测也在波动。
很有可能,这些预测平台已经在某种程度上考虑了推理计算扩展的影响,因为思维链并不是一项新技术,即使通过RL增强。
总体来说,Ryan Kidd认为他也没有比这些预测平台当前预测更好的见解。
在《AI Could Defeat All Of Us Combined》中,Holden Karnofsky描述了一种模棱两可的风险威胁模型。
在此模型中,一群人类水平的AI,凭借更快的认知速度和更好的协调能力超过了人类,而非依赖于定性上的超级智能能力。
这个情景的前提是,「一旦第一个人类水平的AI系统被创造出来,创造它的人,可以利用创造它所需要的相同计算能力,运行数亿个副本,每个副本大约运行一年。」
如果第一个AGI的运行成本和o3-high的成本一样(约3000美元/任务),总成本至少要3000亿美元,那么这个威胁模型似乎就不那么可信了。
因此,Ryan Kidd博士对「部署问题」问题的担忧较小,即一旦经过昂贵的训练,短期模型就可以廉价地部署,从而产生巨大影响。
这在一定程度上减轻了他对「集体」或「高速」超级智能的担忧,同时略微提升了对「定性」超级智能的关注,至少对于第一代AGI系统而言。
如果模型的更多认知,是以人类可解释的思维链(CoT)形式嵌入,而非内部激活,这似乎是通过监督来促进AI安全性的好消息!
尽管CoT对模型推理的描述并不总是真实或准确,但这一点可能得到改进。
Ryan Kidd也对LLM辅助的红队成员持乐观态度,他们能够防止隐秘的阴谋,或者至少限制可能秘密实施的计划的复杂度,前提是有强有力的AI控制措施
从这个角度来看,推理计算扩展范式似乎非常有利于AI安全,前提是有足够的CoT监督。
不幸的是,像Meta的Coconut(「连续思维链」)这样的技术可能很快就会应用于前沿模型,连续推理可以不使用语言作为中介状态。
尽管这些技术可能带来性能上的优势,但它们可能会在AI安全性上带来巨大的隐患。
正如Marius Hobbhahn所说:「如果为了微小的性能提升,而牺牲了可读的CoT,那简直是在自毁前程。」
然而,考虑到用户看不到o1的CoT,尚不确定是否能知道非语言CoT被部署的可能性,除非通过对抗性攻击揭示这一点。
美国AI作家和研究员Gwern Branwen,则认为Ryan Kidd遗漏了一个重要方面:像o1这样的模型的主要目的之一不是将其部署,而是生成下一个模型的训练数据。
o1解决的每一个问题现在都是o3的一个训练数据点(例如,任何一个o1会话最终找到正确答案的例子,都来训练更精细的直觉)。
这意味着这里的扩展范式,可能最终看起来很像当前的训练时范式:大量的大型数据中心,在努力训练一个拥有最高智能的最终前沿模型,并以低搜索的方式使用,并且会被转化为更小更便宜的模型,用于那些低搜索或无搜索的用例。
对于这些大型数据中心来说,工作负载可能几乎完全与搜索相关(因为与实际的微调相比,推出模型的成本低廉且简单),但这对其他人来说并不重要;就像之前一样,所看到的基本是,使用高端GPU和大量电力,等待3到6个月,最终一个更智能的AI出现。
OpenAI部署了o1-pro,而不是将其保持为私有,并将计算资源投资于更多的o3训练等自举过程。
Gwern Branwen对此有点惊讶。
显然,类似的事情也发生在Anthropic和Claude-3.6-opus上——它并没有「失败」,他们只是选择将其保持为私有,并将其蒸馏成一个小而便宜、但又奇怪地聪明的Claude-3.6-sonnet。)
OpenAI的成员突然在Twitter上变得有些奇怪、甚至有些欣喜若狂,原因可能就是看到从原始4o模型到o3(以及现在的状态)的改进。
这就像观看AlphaGo在围棋中等国际排名:它一直在上升……上升……再上升……
可能他们觉得自己「突破了」,终于跨过了临界点:从单纯的前沿AI工作,几乎每个人几年后都会复制的那种,跨越到起飞阶段——破解了智能的关键,以至o4或o5将能够自动化AI研发,并完成剩下的部分。
2024年11月,Altman表示:
我可以看到一条路径,我们正在做的工作会继续加速增长,过去三年取得的进展将继续在未来三年、六年、九年或更长时间里继续下去。
不久却又改口:
我们现在非常确信地知道如何构建传统意义上的AGI……我们开始将目标超越这一点,迈向真正意义上的超级智能。我们很喜欢我们目前的产品,但我们是为了美好的未来。通过超级智能,我们可以做任何事情。
而其他AI实验室却只能望洋兴叹:当超级智能研究能够自给自足时,根本无法获得所需的大型计算设备来竞争。
最终OpenAI可能吃下整个AI市场。
毕竟AlphaGo/Zero模型不仅远超人类,而且运行成本也非常低。仅仅搜索几步就能达到超人类的实力;即使是仅仅前向传递,已接近职业人类的水平!
如果看一下下文中的相关扩展曲线,会发现原因其实显而易见。

论文链接:https://arxiv.org/pdf/2104.03113
推理时的搜索就像是一种刺激剂,能立即提升分数,但很快就会达到极限。
很快,你必须使用更智能的模型来改善搜索本身,而不是做更多的搜索。
如果单纯的搜索能如此有效,那国际象棋在1960年代就能解决了.
而实际上,到1997年5月,计算机才击败了国际象棋世界冠军,但超过国际象棋大师的搜索速度并不难。
如果你想要写着「Hello World」的文本,一群在打字机上的猴子可能就足够了;但如果想要在宇宙毁灭之前,得到《哈姆雷特》的全文,你最好现在就开始去克隆莎士比亚。
幸运的是,如果你手头有需要的训练数据和模型,那可以用来创建一个更聪明的模型:聪明到可以写出媲美甚至超越莎士比亚的作品。
2024年12月20日,奥特曼强调:
在今天的噪声中,似乎有些消息被忽略了:
在编程任务中,o3-mini将超过o1的表现,而且成本还要少很多!
我预计这一趋势将持续下去,但也预见到为获得边际的更多性能而付出指数级增加的资金,这将变得非常奇怪。
因此,你可以花钱来改善模型在某些输出上的表现……但「你」可能是「AI 实验室」,你只是花钱去改善模型本身,而不仅仅是为了某个一般问题的临时输出。
这意味着外部人员可能永远看不到中间模型(就像围棋玩家无法看到AlphaZero训练过程中第三步的随机检查点)。
而且,如果「部署成本是现在的1000倍」成立,这也是不部署的一个理由。
为什么要浪费这些计算资源来服务外部客户,而不继续训练,将其蒸馏回去,最终部署一个成本为100倍、然后10倍、1倍,甚至低于1倍的更优模型呢?
因此,一旦考虑到所有的二阶效应和新工作流,搜索/测试时间范式可能会看起来出奇地熟悉。
参考资料:
https://x.com/emollick/status/1879574043340460256
https://x.com/slow_developer/status/1879952568614547901
https://x.com/kimmonismus/status/1879961110507581839
https://www.lesswrong.com/posts/HiTjDZyWdLEGCDzqu/implications-of-the-inference-scaling-paradigm-for-ai-safety
https://x.com/jeremyphoward/status/1879691404232015942
文章来自于微信公众号“新智元”



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
