
横扫八大数学竞赛:清华微软联合提出STAR-PólyaMath,Apex基准超GPT-5.5 13.5%
横扫八大数学竞赛:清华微软联合提出STAR-PólyaMath,Apex基准超GPT-5.5 13.5%被一道数学竞赛题卡住很久时,高手往往能准确地判断:现在缺的是一个技术细节,还是整个思路从一开始就走错了?
来自主题: AI技术研报
9220 点击 2026-06-25 10:04
 搜索
搜索
被一道数学竞赛题卡住很久时,高手往往能准确地判断:现在缺的是一个技术细节,还是整个思路从一开始就走错了?
今天,OpenAI祭出满血GPT-5.5-Cyber,要给全世界的开源代码修漏洞。结果话音刚落,Codex被扒出史诗级bug:一年狂写640TB,能把SSD直接写废。
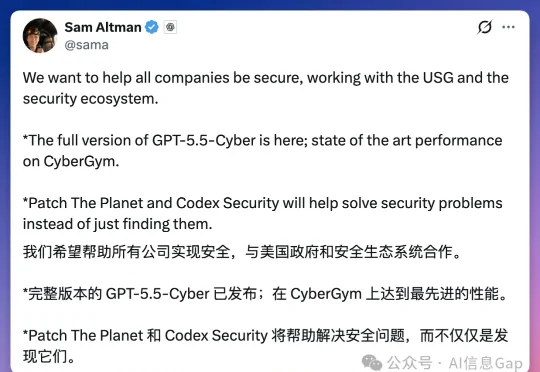
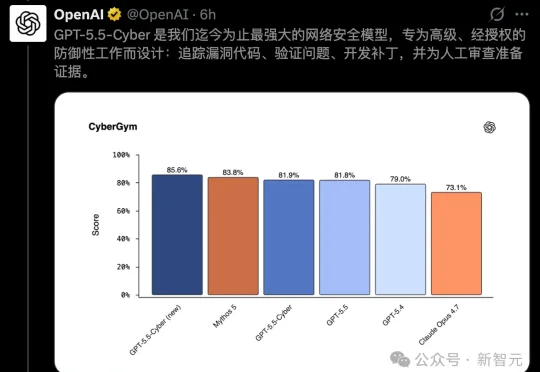
就在刚刚,OpenAI 直接放出了满血版 GPT-5.5-Cyber。CyberGym 安全评测排行榜,GPT-5.5-Cyber 得分 85.6%,单模型最高分。Claude Mythos 5 第二,83.8%。Claude Opus 4.7 排末尾,73.1%。
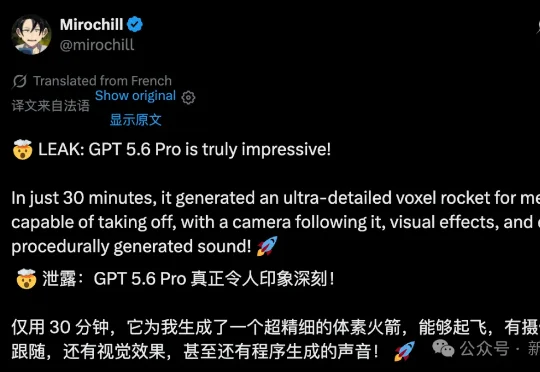
GPT-5.6 Pro 泄露炸场:推理能力涨 25%、知识截止推至 2025 年 12 月、3D 生成碾压 Fable,一句话 48 分钟在聊天框里直接跑出完整《模拟人生》。
刚刚,Anthropic重磅产品曝光了:永久在线智能体Conway来袭,AI开始主动打工,告别对话框!同时,GPT-5.6也在悄悄内测了。巨头激战,谁将颠覆你的工作流?

最近几天,一个 3B 的小模型在 X 上火了,因为在一些难度可验证的推理任务上(比如编程),它进入了 Gemini 3 Pro、GPT-5 high、Claude Opus 4.5、GLM-5、Kimi K2.5 等前沿模型的性能区间,而它的体积远小于这些模型。

大模型再强,也读不懂你公司那一柜子的合同、发票和扫描件。在"纸张世界"和"LLM世界"之间,缺一座桥——而百度开源的 PaddleOCR,可能就是当下最稳的那座。

离谱了。 这两天,AI 圈都在疯传一个叫 Le Chaton Fat 的新模型。 30T MoE、256 个专家、100 万上下文窗口、多模态多语言,跑分全面碾压 Claude Fable 5、Claude Opus 4.8 和 GPT-5.5。

Fable 5被禁用,美国政府指Anthropic态度敷衍,Anthropic坚称是孤立事件。Dario把技术比作核弹,如今却因不愿关闭系统而陷入绝境,把美国整个AI行业拉下水。
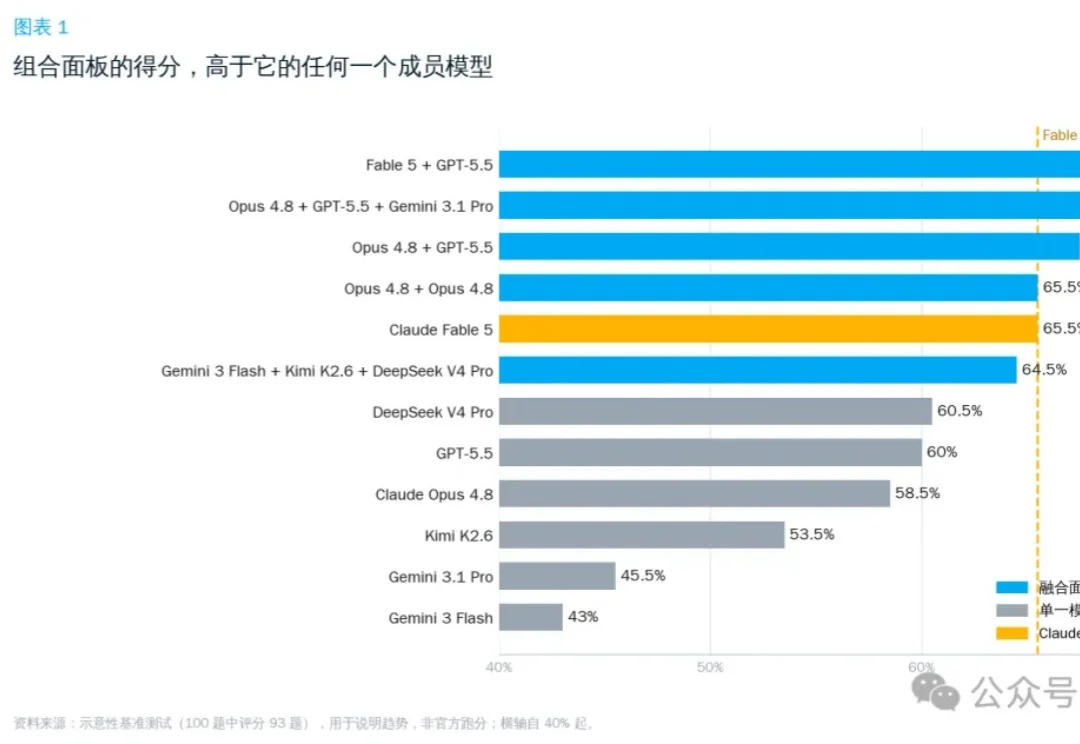
AI网关OrcaRouter最近上线了一套可编程路由策略Routing DSL,多个模型同时答题,自动仲裁出最优解。几个你现在就能调用的“常规模型”,给它来个组合编排,跑出来的综合胜率,直接掀翻了Fable 5的单体基准线。Opus 4.8打不过Fable 5,GPT-5.5也单挑不过,但这两个拼一组,结果就反超了。