# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
无常按:
2025年被很多人视为 Agent 之年,确实值得多关注。今天分享的这篇,应该是全网关于Agent话题最深入的讨论了,大概没有之一,从前沿研究、交互设计到产品落地,全文超过三万字,一篇看明白。
超 4000 字人工提炼,实在没时间可以先读核心观点,但仍然非常推荐阅读全文。
因为你要做的decision其实很多是open-ended的。比如说今天晚上做什么,action space是open-ended的,并没有一个类似游戏里的上下左右这样的键盘去给你指引。你可以买张机票去另一个城市,或者看个电视,有无数种选择。所以Language更接近这个事情的本质(姚顺雨)

注:本期录制时间为2024年5月。但认知扩散的速度并没有太快,业界的很多认知,到半年后的今天,似乎都远没赶上前沿研究半年前的认知。
00:00:45 - 00:02:07
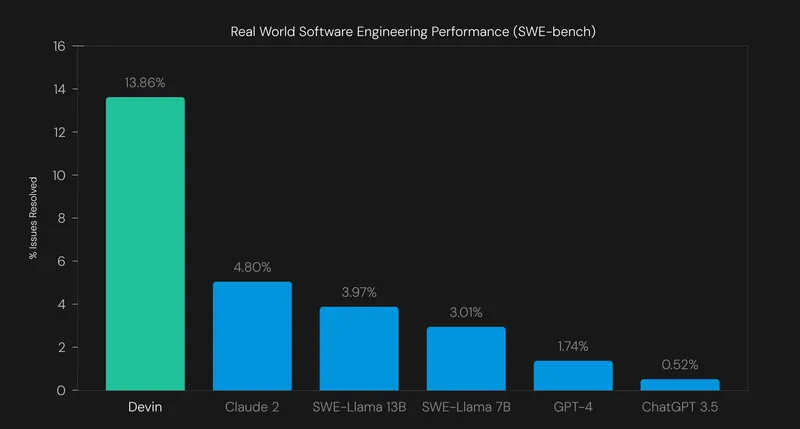
今年除了OpenAI的Solar惊起千层浪以外,同样引起AI从业者尤其工程师极大关注的,想必就是仅通过一段演示视频就连续获得两轮融资,估值在半年内蹿升到20亿美元的Cognition Labs的AI agent Devin。作为宣称的世界上第一位AI软件工程师,它将如何重塑软件开发甚至工程师这个职业?Devin是否能代表agent应用开发的方向?以及看到目前agent产品还有多少提升空间?
这一期我们邀请到三位在各自领域都极具代表性的嘉宾,有来自去年刚晋升独角兽的软件开发云平台Rapid的AI agent工程师,首个基于GitHub的代码能力评估数据集SWE-bench以及首个开源AI software agent项目Three Agent的作者,还有刚官宣估值达到10亿美元的企业级AI编程辅助公司Ogman的AI研究员。
在两个多小时的对话里,我们从工程师个体、企业级需求以及学界研究等不同角度,深入探讨了最近出现的编程辅助产品、试图替代工程师的agent、基础大模型的边界,以及生成式AI对个人职业和社会的深远影响。本期内容远远超出了对技术和产品的探讨,希望能对正在收听的你们有所启发。enjoy。
00:02:07 - 00:03:30
Monica:
大家好,欢迎来到Onboard,我是Monica。
高宁:
我是高宁。
Monica:
今天我们很难得在硅谷录制这期线下的Onboard。这期节目的话题,我觉得集合了AI界最近最热的几个方向。一开始我们计划讨论AI for coding这个话题。在几个月前,大家关注更多是像Microsoft的Copilot这种auto complete的形态。但是关注这个领域的朋友应该也注意到,前几周Cognition Labs发布了一个叫Devin的coding agent,我觉得这一下子让大家对LLM或AI如何改变整个软件开发模式有了新的想象空间。
高宁:
每个阶段都非常有代表性的产品和技术。
Monica:
对,所以我们今天请到了在这个领域非常有发言权的几位嘉宾。刚才我们也喝了点小酒,气氛已经到位了。
00:03:31 - 00:06:07
高宁:
请三位嘉宾做个简单的自我介绍,同时分享一下今年发现的最有意思的产品。我们从顺雨开始吧。
姚顺雨:
大家好,我叫姚顺雨,是Princeton第五年的PhD,马上毕业了,现在在旧金山的Sierra实习。说到有意思的产品,我想推荐Sierra,这是AI领域真正能落地的产品之一,主要做customer service business agent。我们已经有很多客户了,最让人兴奋的是它真的work,而且能够完全替代某些角色。
Monica:
Sierra确实是去年最受关注的典型大佬创业公司,是原来Salesforce的CEO创立的,主要为企业提供customer service chatbot服务。
高宁:
那除了Sierra之外,你今年发现最有意思的AI产品是什么?
姚顺雨:
我经常使用Perplexity,主要用它代替Google搜索一些知识性的内容。
Monica:
不只是在国内,就算在国外,在AI圈子之外的人对Perplexity都不太熟悉。我现在除了查找具体网站这类事实信息用Google外,只要是带问号的搜索都会用Perplexity。
李珎:
我现在使用Perplexity的比例已经达到30%了。
Monica:
顺雨,你能介绍一下是如何进入AI研究领域的吗?
姚顺雨:
我本科时就开始做科研,最初是做computer vision,后来觉得想要研究language,就转向了这个方向。
Monica:
顺雨很谦虚,他在agent相关的工作在整个领域都有很强的标志性意义,一会儿我们会请他详细介绍。
00:06:07 - 00:06:44
赵宇哲:
大家好,我叫赵宇哲,我现在在一家做full stack AI for code的AI创业公司工作。之前我在Google Research的Google Brain团队,主要做language research的工作。
Monica:
对,这家公司也是某大佬创业的,我们今天集齐了各个大佬创业公司。这家公司是某特别爱孵化的大佬基金孵化的一个公司。
00:06:45 - 00:09:56
高宁:
能说说你是怎么进入AI这个领域的吗?
赵宇哲:
我进入这个领域运气特别好。我PhD期间做的是比较理论的研究,当时觉得这些理论研究缺乏实际意义和解释性。毕业时我在vision和language两个方向之间选择,因为在PhD期间做过一些vision的小项目,但最终选择了language方向,因为language与intelligence更接近,而vision更偏向perception(感知)。
五年前我加入了Google,正好是发明BERT的团队。经历了BERT前后NLP研究的翻天覆地变化,这对我来说是非常好的学习机会。最初我做了很多BERT的pre-training相关工作,后来参与了LaMDA项目。LaMDA是生成式AI的开山鼻祖,在此之前没人认为生成式语言模型可以用来做chatbot。之后我们做了第一批instruction tuning的工作,发表了相关论文。
我个人比较感兴趣的研究方向是retrieval,我认为retrieval对language model来说是一个很重要的capability,这也是我现在在新公司正在做的事情。除此之外,我也参与了一些产品落地的工作。
说到AI产品,我觉得视频生成很有意思,虽然我主要是看demo。日常使用最多的还是GPT,特别是用GPT-4来处理一些图像相关的任务。
00:09:57 - 00:10:23
高宁:
好的,李珎。
Monica:
大家好。
李珎:
大家好,我叫李珎,目前在一家B轮创业公司工作。我们的产品不仅仅是一个IDE,它最初是从一个multiplayer online IDE开始的,现在已经有两千多万用户。
00:10:23 - 00:11:33
大部分人其实是在学习编程,或者说不太会写代码的,这些人需要一些没那么专业的programmer的帮助。我们的vision是"Next billion software creator"。
赵宇哲:
这个世界上会写程序的人只有三四千万,是人类人口的极小部分。
李珎:
对,我们经常听到"我有一个idea,但是缺一个程序员"。
赵宇哲:
有idea的人是很多的。
李珎:
但是我们的vision其实就是想让所有人都成为software creator,你有一个idea就可以create software。这个vision在七年前就有了,所以第一步是做一个云IDE,让大家可以在手机上、在任何地方写代码,然后有一些辅助配置环境的工具。现在加入了更多AI的部分,这让我们离实现这个vision会更近很多。
00:11:33 - 00:12:58
这是我们公司,我是六个月前来到这里的。我在北航本科毕业后直接去了Google,在那里工作了五年。
赵宇哲:
在Google主要是做推荐系统?
李珎:
对,做Google News,我们叫Discover,其实也是news。那时候我一直在做AI,特别是推荐系统,这是上一波AI最赚钱的场景和产品。做了五年后,我觉得基本已经卷到头了,因为大家都在往上加各种各样的奇技淫巧。有很多feature engineering,然后在模型里面加一些奇怪的结构,比如attention、transformer这些。这些方式it worth,但已经有种卷到头的感觉了。真正能带来正向revenue的突破不多,所以我后来就出来了,去TikTok做了一年推荐,想看看他们在干什么。
00:12:58 - 00:15:42
Monica:
你不是已经觉得卷到头了吗?怎么又去了一个更卷的地方?
李珎:
我当时觉得Google的工作方式可能不太适合我,想看看中国公司是怎么样的,因为我想创业。创业就会面临一个问题:是在美国创业还是在中国创业?所以我想给自己一年时间去回答这个问题,就去了TikTok。待了一年拿到绿卡后我就出来创业了,因为我觉得自己做才能真正学到东西。
我做了一个Biotech领域的Copilot,就是给biotech的人做copilot。从前年到去年九月份,那时ChatGPT还没出来。我们当时有个very big ambition,想做GPT的App Store。后来我发现AI在coding领域能产生更大的价值,就开始寻找这个方向的机会。
Monica:
所以你当时去的这家公司已经做了好几年了,是在一个什么阶段?
李珎:
他们已经做了六七年,有很好的产品市场契合度,有大量用户非常喜欢这个产品,但需要开始盈利了。我加入的时候正好是公司开始引入AI的早期阶段,他们刚从Google Research挖来了我的老板,他之前在做PaLM和其他coding model。公司刚开始加入ghost writer等AI相关feature,是很早期的阶段,然后后面又做了一系列的提升。
00:15:44 - 00:16:59
高宁:
你今年发现的最有意思的AI产品是哪个?
李珎:
因为我想要Empower更多人去build software,有一个产品特别有意思。是一家叫Buildspace的公司,是a16z投资的。它更像是一个学校,主要是帮助更多人学习怎么做产品。他们今年做了一个新产品,是一个chatbot。你可以跟它说你的idea,它要么帮你生成代码,要么帮你对接到能帮到你的人。比如说,如果你是YouTuber,你跟它说我想要给我的视频生成更好的封面,它就会帮你找到大概十个正在做YouTube视频封面生成的公司或者个人。
00:16:59 - 00:17:45
这个产品本质上是在把人和人connect起来,这是一件很好的事情,是帮助你去完成目标。你并不需要自己会做所有的事情,只要有人能帮你完成就可以。他之前是做crypto的,现在在Web3上。
观众:
本质上这是一个非常有意思的公司。
李珎:
我非常喜欢这个founder,他是一个特别优秀的创业者。他很喜欢sharing他的knowledge。我在他那里学到的创业知识,可能比我自己做创业六个月学到的还多,而在他那里只花了几个星期的时间。
00:17:46 - 00:20:24
Monica:
我觉得这个挺有意思的,让我想到HeyGen。他们之前分享过早期的一个growth hack。这是一家华人创业公司,前段时间拿到了Benchmark的4000万美金投资。他们是帮你自动生成类似真人的avatar。最早他们把服务放到Fiverr这个freelancer平台上,那里真人视频服务通常要收费几十到一百美金一小时。他们就把AI生成的视频标价很低,好像就五美金左右。这个价格差太大了,一下子就打开市场了。我觉得以后有了这些AI技术和产品,真的可以帮你端到端完成工作,到时候在这些网站上,你可能都分不清哪些是AI、哪些是真人做的了。
李珎:
我是通过Buildspace认识到这些的。Buildspace的slogan是six weeks to work on your dream。它会定期组织batch活动,六周时间让你去实现自己的梦想。你可以做software、APP,甚至像我当时那样画漫画,也可以写歌。他们不教你怎么写代码,而是教你怎么让别人关注你的产品,怎么去launch。我参加过两次,后来通过Buildspace的founder Farza和Anthropic CEO的fire side chat认识了Anthropic,这就是我现在在这里的原因。
00:20:24 - 00:20:41
赵宇哲:
非常酷的。
Monica:
对,很棒。刚才李珎讲到了Replit,这家成立五六年的公司现在融资已经超过了两亿美金。
高宁:
是个独角兽了。
00:20:41 - 00:21:37
Monica:
对,朱老师说得对。在这波AI浪潮中,Replit在美国一直处于聚光灯之下。我觉得他们算是前行者,从两三年前就开始加入很多AI功能,迭代也非常快。我专门去看了Replit的博客,他们分享了很多关于AI的思考。去年年中他们就发表了一篇博客,讲AI will redefine every single app feature。他们发布的这些AI功能让我们发现,AI在IDE开发工具里的应用远不止Copilot那样的功能。李珎,你能给大家介绍一下Replit的AI产品都有哪些?它背后的主线逻辑是怎样的?
00:21:38 - 00:22:02
赵宇哲:
我们的主线逻辑很简单,我们想做两件事。
李珎:
第一件事是Next billion software creator,让更多的人可以去create software。第二个是from idea to software,就是把你的想法转变成一个能够帮你profit的软件。
00:22:02 - 00:22:32
我们所有的产品都是围绕着这个平台,这是一个云端的代码平台,它支持multiplayer功能。
赵宇哲:
用户可以在云端编写代码。
李珎:
这个multiplayer功能实际上给我们带来了很多用户,特别是教育领域的用户。比如老师可以实时看到学生在写什么代码,在整个debug过程中,每一个步骤都能在multiplayer环境下被看到。
00:22:32 - 00:23:56
观众:
是code completion,就是我们当时的ghost writer。
李珎:
在你写代码的时候,它会出现一堆ghost writer,也就是ghost text。你可以接受它给你的补全建议,这个其实跟GitHub Copilot和大量的补全产品非常像。这是一个很直观的能够帮助程序员写代码的产品,也是现在大家觉得最有用的产品之一。
同时我们会有一个AI chat,这是个很常见的产品。在我们的IDE里,左边是代码,右边就是chat。你可以用它做很多事情,比如帮你生成代码,然后直接一键贴到IDE里面。或者当某个地方有红线提示LSP错误或语法错误时,上面会有debug按钮,点击后它会在chat里显示错误原因,并告诉你如何修复。
00:23:56 - 00:25:34
我们的Software开发流程是这样的:从写代码开始,然后debug运行,我们最大的优势是把所有环境都放在了云端。
赵宇哲:
云端确实解决了很多问题。
李珎:
是的,程序员都知道配环境很麻烦。Replit通过云端环境和standardize的setup脚本解决了这个问题,这样就不存在本地Python dependencies这样的问题了。到最后一步deployment时,你完成软件后希望它成为一个真的网站供人访问。我们其实做了一件事,就是把整个软件开发周期里面要做的事情都集成在了一个平台里面,是一个all in one的platform。
现在市场上有很多公司分别在做code completion、deployment等单项功能。把这些整合在一起有好有坏:坏处是我们一个公司要做好几家公司的事情,好处是可以把整体体验优化得非常好。
00:25:34 - 00:26:44
我们发布了很多功能,包括ghost writer和chat。今年初我们做了一个很大的改动就是AI for All。之前AI功能只对付费用户开放,现在我们把这个功能开放给了所有人。你现在上Replit,不需要有账号就可以使用code completion和AI chat。这对我们来说其实是在花钱的事情,因为我们要支付这些token给免费用户。
高宁:
用户现在不需要注册就可以体验这些AI功能了吗?
李珎:
对,不需要注册就可以用。这是我们的vision,因为我们想要让更多人能够用AI去create software。这也是我加入后做的比较大的第一批工作之一。
00:26:46 - 00:28:57
这其实也引出了我们自己的一些工作。我们训练了自己的code completion模型,包括上个月发布的code pair模型,因为我们要支持更多人使用AI。我们有几百万用户需要服务,这对模型和后端系统提出了很多特殊要求。
高宁:
我理解就是需要一个更小的模型,用更低成本的方式来服务更大规模的用户,对吗?
李珎:
对,有两个出发点。第一个就像你说的,模型必须要小,因为这样才快,而且要便宜。第二个原因是我们要利用自己的数据来提升模型性能。
Monica:
我看到最近发布的1.5版本code模型是3B参数量。
李珎:
对,我们现在有3B参数量的code completion模型,已经放在Hugging Face上可以下载。另外,我们最近还发布了一个code repair模型,它不是做补全,而是帮你修复代码错误的。这个模型既可以让agent用来修复代码中的bug,用户也可以直接获得修复建议。相比调用更大的模型,我们用更小更快的方式来提供建议,这样就能更频繁地服务用户。
00:28:57 - 00:30:43
高宁:
现在我们看到专门针对coding的模型非常多,非常卷。不管是大模型公司还是像magic这样的startup,包括云厂商都在开发自己的coding model。我想请教大家,我们是否真的需要一个专门的coding model?它的能力是否真的可能超越现在的通用基础模型?
Monica:
这涉及两个问题:一是专门的coding模型在效果上能否超越最好的通用基础模型,二是我们现在有这么多专门的coding model,是纯粹出于效率的考量,还是有其他因素在里面?
李珎:
从Replit的角度来说,我们的目标是要Power next billion Creator。虽然我们只训练了3B的模型,但评估显示其性能比Code Llama 7B更好。因为我们的用户主要是citizen developer,所以我们更关注效率和成本。我们的主要考量是如何降低为用户提供免费服务的成本,同时充分利用我们自己的数据。
00:30:43 - 00:31:01
Monica:
关于podcast讨论的这个话题,如果大家使用公开抓取的coding数据,大概率这些数据的质量不如企业内部的代码那么高,因为很多开源代码可能存在garbage in, garbage out的问题。
00:31:01 - 00:31:46
赵宇哲:
我觉得这个问题很好,我们的promise是我们绝对不会在意这一点。这就是做enterprise业务的特点。我可以看到做enterprise和非enterprise业务有很大的区别。
比如说data engine这个领域,为什么要用Snowflake而不用Azure或者GCP的服务?有一部分原因是trust。如果你是面向企业的企业,对这个特别在意。当然也不是所有企业都这样,特别小的企业可能无所谓,但是到了一定规模,大家对这个问题特别清楚,会对security有顾虑,这让体验很不一样。
00:31:46 - 00:34:04
Monica:
我在想,在这个领域是否不存在所谓的数据飞轮效应?因为客户数据都无法使用,各个model的数据似乎都没有什么优势。
赵宇哲:
我并不完全同意。公司可以获取一些带license的数据,而且GitHub本身的数据已经很丰富。目前标准做法是收集GitHub的各种版本进行deduplicate。但这里有个关键问题是license,在GitHub上clone代码并不意味着license允许你用于训练。如果要认真做enterprise服务,这存在legal风险。比如Microsoft为了获得trust,会向GitHub用户承诺处理所有legal问题。
Monica:
那这样的话,如果GitHub也严格遵守license,是不是意味着他们在数据上也不会比别人有优势?
赵宇哲:
是的。而且Copilot现在是用OpenAI的API,他们之间的关系并不透明。不过,GitHub确实提供了enterprise服务,如果企业需要fine tuning,他们可以提供fine tuning服务和私有化部署。
Monica:
所以最终企业的需求是希望model只benefit自己的数据?
赵宇哲:
对,这会是一个重要的service方向。
00:34:04 - 00:35:29
Monica:
我对这个领域还不是很了解,想请教一下,如果拿最强大的通用基础模型,比如GPT-4这样的模型,与专业的coding模型相比,它们的编程能力是怎样的关系呢?
赵宇哲:
这是个很好的问题。当初不只有专门做coding的模型,还有专门做数学证明的模型。这种专门化模型出现有几个原因:
一方面是学术界的research需求,因为代码这个language不是natural language,作为natural language研究的人原本不研究code。但当T5这些模型出现后,学术界就开始专门研究如何用这些模型去做code task,包括数学和逻辑证明的模型。
另一个重要原因是cost考虑,因为虽然code跟natural language有关系,但关联度并不那么高。如果只是想训练一个专注于code的模型,可能专门训练会更好。比如国内的DeepSeek就是一个非常优秀的代码模型。
Monica:
而且DeepSeek还是开源的。
00:35:30 - 00:36:50
赵宇哲:
还是开源的。然后在代码训练上,有一个很有意思的预训练方法叫filling the middle。它不是传统的从上到下、从左到右的训练方式,而是专注于上下文中间的内容。这个任务特别适合做代码补全。OpenAI的论文也提到了这一点,说明这种filling the middle的训练方式是很重要的。
DeepSeek就采用了这种方法,而且他们还在代码训练上做了一些创新,比如repo level的预训练。你想啊,对于普通文本来说,不同文本之间是随机组合的,因为它们本来就没什么关系。但是对代码来说就不一样了,因为在同一个代码库里,不同的文件之间是有关联的。DeepSeek就利用这种文件之间的关系来构造训练数据,这样就能得到很好的长文本训练数据。
00:36:51 - 00:37:10
姚顺雨:
我们需要对这些内容进行排序吗?
赵宇哲:
对,这是在做错误处理。在code上实现是很容易的。我觉得在natural language中虽然不是不可以,你可以用search来排序文本,但code就容易得多,因为code的结构比较清晰。
李珎:
结构比较清晰。
赵宇哲:
对,正是因为结构比较清晰,所以在code上可以更容易地实现这些功能。
00:37:10 - 00:37:36
姚顺雨:
是不是tokenization也不太一样?
赵宇哲:
理论上可以用相同的tokenization,但实际上确实会不一样。即使用相同的训练策略,distribution也会不一样。不过之前的表现确实很好。
GPT-4的代码能力非常强。对于general model来说,你需要专门分配很大的预算来训练代码能力,因为代码相关的能力需要很大的模型capacity。
00:37:36 - 00:38:33
最近发布的Llama 3在代码方面表现很强。从能力上来说,专门的code model不一定比general model强,但它的模型体积一定更小。
Monica:
现在这些model的coding能力相比是怎么样的?
赵宇哲:
DeepSeek很强,然后Llama和GPT都很厉害。但这要看具体task,GPT不是专门做代码补全的模型。专门的代码补全模型在这方面确实厉害。但在human evaluation时,有一个特别的task,就是decode任务。
高宁:
刷题的那个。
赵宇哲:
对,就是很简单的standalone任务,给你一个单独的任务,要求实现某个算法,GPT-4在这方面表现很强。
00:38:33 - 00:40:00
Monica:
去年年初我们和Google PaLM的作者之一讨论时就提到,大家发现加入coding数据的重要性已经成为业界共识。如果那些做Foundation model的公司目标是AGI,他们肯定会花大价钱,尽可能获取所有能拿到的最高质量coding数据。
赵宇哲:
完全同意这个AGI的观点。有人认为如果是一个很强的程序员能写代码就是AGI的体现,因为优秀的程序员可以实现很多功能。这就是Magic Dev Def公司的主张,这是很有逻辑的。这也解释了为什么大家都关心MMLU能力,还有人专门训练模型做奥数,因为这些都与reasoning能力关系最紧密。
李珎:
如果我们认为当前的瓶颈是reasoning能力,那就应该给模型提供更多的reasoning数据。而现在大家能想到的最强的reasoning数据就是代码。
00:40:00 - 00:40:56
高宁:
我知道有一家startup,他们专门为LLM公司提供训练用的代码数据。这些LLM公司会提出具体需求,然后这家startup负责招聘专业程序员来编写高质量的代码数据,用于预训练。这个模式有点像Scale AI。
李珎:
他们是通过购买这些数据来获得收入的。
赵宇哲:
我看到很多代码的instruction数据集。
高宁:
是的,GitHub上的代码数据质量只能说是中庸水平,现在确实需要更专业、更高质量的代码数据集。
Monica:
这说明我们进入了数据升级阶段,要产生高质量的数据,成本也在不断提高。
00:40:56 - 00:43:29
我想了解一下,你刚才提到为了让模型有更好的代码补全能力,有很多专门的训练方式。这些训练方式能用于Foundation model的训练吗?
赵宇哲:
是可以的。这种上下文预测的方式并不新,T5就是这么做的。我之前做过一个叫dialogue predicting的工作,目标是通过已知对话的上下文来预测中间的话语内容。这个task虽然有多种变体,但并不是很popular,主要是因为效率问题。在decoder-only model中,training时你只是让它predict下一个token。这里有个概念叫cost of masking,就是在predict token时会使用当前所有可见的token。如果做filling the middle training,dependency关系就会改变,之前的计算就不能被重用了。
姚顺雨:
比如你想用第一句和第三句来预测第二句,然后又要用第二句和第四句来预测第三句,这样很多计算就没法reuse。
赵宇哲:
对,虽然付出同样的计算量,但效率会低很多。
Monica:
这让我想到最近大家经常讨论的AI能否帮我们解决复杂的学术问题,比如数学定理证明。本质上不就是已知条件和结论,需要证明中间过程吗?这个technique能用在这方面吗?
赵宇哲:
有这个可能性,但做reasoning时不一定要用filling the middle的方式。你可以用其他prompt方式,把结论直接放到prompt前面告诉模型这是目标。这样也是可以work的。
00:43:29 - 00:45:26
Monica:
姚顺雨,你怎么看?就前段时间Magic Dev一上来就融了上亿美金,号称要做最最牛逼的coding模型,说这是通往AGI的捷径。
姚顺雨:
我认为coding数据对训练Foundation Model非常重要,这个毫无疑问。但仅靠coding能否实现AGI这点还有待商榷。natural language和programming language是有本质区别的。programming language更结构化,而natural language更noisy,有更多的pragmatic结构。对于人来说,比如要创业,就需要同时掌握programming language和natural language。我觉得高质量的coding数据eventually会很重要。
Monica:
你觉得eventually最强的Foundation Model的coding能力会强于专门的coding model吗?
姚顺雨:
我觉得是的,因为这不是一个fair comparison。Foundation Model规模更大,而且在其他数据上训练后整体推理能力会更强。但这要取决于具体application,比如Copilot这样的应用就需要小模型。
李珎:
讨论最强模型的话,最强的模型一定是把所有数据都用上的。不会出现一个仅仅因为用了更多coding数据就能超越最强模型的情况。
00:45:27 - 00:46:42
Monica:
让我们聊聊model之后的产品话题。o1选择了一条比较难的路径,就是完全构建一个自己的IDE。我们看到很多像Copilot这样的产品采用插件形式,我很好奇你们是怎么思考这个产品形态的,以及不同产品形态对AI产品设计会有什么影响?
李珎:
说实话,这个产品的逻辑我一开始也不太懂,我觉得很多人可能也看不懂。虽然表面上看起来就是一个IDE,但我们选择这种形式是有原因的。最大的好处是可以降低用户的上手成本,用户不需要去操心下载VS Code、安装Replit插件、学习如何使用Azure部署等这些复杂的步骤。我们把这些功能都以按钮的形式整合起来,让用户可以一键设置环境。这也是我们在2022年之前能够吸引用户的一个重要原因。
00:46:42 - 00:49:45
我在考虑加入时就在思考,如果AGI真的来临,一个超强的AGI会需要什么?它可能有很强的大脑,但如果要替代现有的软件开发过程,它需要各种工具,就像手和脚一样。它需要一个写代码的地方,需要能测试、部署,然后验证部署结果,看到自己构建的网站效果并进行反馈循环。最后还要把产品上线,接入支付功能,成为一个真正可以持续迭代的产品。
这些工具现在都在本地,但最终会变成云端API供AGI使用。实际上,我们(Replit)是在打造一个给AGI写代码和制作产品的sandbox,只是现在的用户还是人。即使OpenAI开发出超强的模型,它也需要像我们一样构建云平台,让AGI能够编写、运行、debug代码,处理编译问题和LSP,处理各种错误和不同的编程语言。如果一个公司之前几年的工作能被轻易取代,那这个公司就没有什么价值。
姚顺雨:
你提到未来AI可能会使用你们的工具,它是通过API接入还是使用UI界面?
李珎:
我们内部已经有了这些API,包括获取30多种编程语言的编译结果、LSP结果、部署运行测试等每一个步骤。就是通过function calling,告诉AI这些工具可以用,它就能直接调用这些API。
00:49:46 - 00:51:35
Monica:
我在思考未来的开发环境选择问题。现在我们需要在GitHub和Replit之间做选择,但我认为未来决策可能会往更高层面发展。就像订外卖,现在我们要在Uber eats和其他平台之间选择,但未来可能我只需要表达我要订外卖这个需求,由AI模型来决定使用哪个平台。同样,开发者可能只需要表达我要写代码,由AI来决定在哪个平台上实现。
李珎:
这要看用户类型。如果是编程小白,确实需要很high level的抽象,比如帮我做个程序,演唱会有票就给我发短信。但对于专业程序员,就像F1赛车手一样,他们会更具体地描述需求,比如要build一个iOS app,需要接入stripe,需要这个功能那个功能。
高宁:
当需求明确时,就需要specific的model和function。RAG技术更适合小白用户,也就是citizen developer。而宇哲他们公司做的是插件形态的产品,专门服务于企业里的专业程序员。这与GitHub copilot等产品相比有其独特的定位。
00:51:35 - 00:54:09
产品的一个不一样的地方和这里面的一些难点在哪里?
赵宇哲:
我们公司的value proposition是希望我们的产品是真正懂你的codebase的。这个设计是针对已经有一个极大的codebase存在的场景。这和现在主流的那些benchmark很不一样,因为那些更像是面试题,甚至比面试题还要简单的考试题。
在现实工作中,无论你做什么工作,都会面对一个巨大的codebase。比如做财务的会面对整个公司的financial系统,做程序员的会面对整个公司的代码。有趣的是,世界上拥有最大codebase的其实不是tech公司,而是银行。
无常按:刚好和最近的一个思考不谋而合了。不存在从零到一的创作,今天人类几乎所有创作都是有上下文的。所以AI产品必须要了解用户场景的上下文,必须RAG(也许还应该有其他方式)。
我们面临两个主要挑战:
第一,产品必须真正懂你的整个codebase,所以retrieval特别重要,因为这些代码不会出现在Foundation模型的训练数据中。
第二,产品feature必须能融入用户的工作流。对于professional用户来说,他们已经有了自己的工作方式,这就是为什么代码补全这么受欢迎,因为它对工作流的改变最小,用起来也很简单。
所以对我们公司来说,最重要的就是要在一个巨大的codebase里面做一个好用的工具。
00:54:09 - 00:55:26
Monica:
我很好奇,在你们这么多AI feature中,哪个是最受欢迎的?
李珎:
最常用的显然是code completion功能。不过最近增长最快的是deployment功能,它可以帮助用户将产品网站或项目正式上线。这个功能增长非常快,而且能很好地monetize,因为用户都愿意为此付费。我们最近在deployment上也在加入很多AI feature。总的来说,对所有编程工作而言,最常用的是code completion和聊天功能。
实际上,我们的AI功能遍布整个平台的各个角落。这些功能背后都是同一套系统,它们之间可以相互共享context。
00:55:26 - 00:57:09
Monica:
我很好奇,刚才宇哲提到要满足企业级需求,能否跟大家解释一下,如何构建一个更懂企业自身需求的solution?是RAG吧?
赵宇哲:
对,就是RAG。这是很多做企业级AI的公司都需要面对的问题。RAG有很多种实现方法和变化,不同的任务需要不同的方案。
RAG的核心功能是让Foundation model能够在私有数据的context下完成任务。在不进行fine tuning的情况下,唯一的方法就是把相关信息放在模型的context里。对于不同的task,你需要看不同的context,这一点在context特别多的时候尤为重要。企业相比个人通常会有更大的context,包括自己的codebase和各种数据。因为context量太大,你没办法把所有内容都放在language model的context里,所以需要使用retrieval技术来挑选相关的内容。
00:57:09 - 00:58:39
那这边关于retrieval的实现,需要考虑在什么时候执行,以及执行的频率。
李珎:
需要做多次执行。
赵宇哲:
在选择retrieval的具体实现时,你可以使用关系型数据库,也可以选择向量数据库,这些都是可选的方案。
Monica:
虽然大家经常谈论retrieval这个概念,但实际上并没有一个统一的最佳实践。针对不同的场景,现在的解决方案都是不同的。
赵宇哲:
确实,有些初创公司想要做通用解决方案。我之前做retrieval研究时也在探索这个方向,希望开发一个通用的retrieval模型。但就目前来说,在自然语言问答这个任务上,市面上的模型确实做得都很好,但问题是并不是所有场景都是问答任务,所以这不是一个万能的解决方案。
高宁:
在你现在做代码相关的企业场景中,特别是RAG这块,你觉得最大的挑战或者跟之前general场景最不一样的地方在哪里?
赵宇哲:
从技术角度来说其实没有特别大的挑战,但我觉得比较有意思的挑战是evaluation。这个问题不仅存在于代码场景,对所有初创公司来说,价值评估和技术排名都是很困难的事情。
00:58:39 - 00:59:34
这适用于所有公司。RAG更难的地方在于它本身很难被value,因为它不是终端的。比如我做代码质量评估时,直接看代码好不好就行。但是当涉及到应该retrieve哪个文档来改进代码时,这就多了一层复杂度,所以retrieve的evaluation本身就更难做。这也是为什么学术性的evaluation很难做。
李珎:
对,甚至连标注都很难。给你一个包含一千个文件的code base和一个问题,让你判断哪两个文件最相关,这种标注是很难的。这不像其他数据标注任务,普通大学生就能完成,这个真的very hard。
00:59:35 - 01:00:34
姚顺雨:
对,你会用streaming来实现这个功能。
Monica:
我最近参加了Google Cloud的活动,看到很多企业用户都在使用RAG技术。虽然每个企业都有自己的实现思路,但当讨论到准确率时,发现一个问题:这些系统的准确率大多只有70%-80%,这样的准确率在生产环境中是很难部署的。我很好奇,提高准确率的难点究竟在哪里?
赵宇哲:
这个问题的关键是要先思考准确率本身的含义,这实际上是一个evaluation的问题。
李珎:
就是top K的问题,可能是第一个结果准确,也可能是前十个结果都准确,这其实很像Google search的问题。
赵宇哲:
对,Google search就是全世界最大的Retrieval系统。
无常按:Google search就是全世界最大的 Retrieval 系统。一个简单到容易被忽略的事实。
01:00:35 - 01:04:01
Monica:
如果企业需要达到90%、95%或99%的准确率才能在生产环境中使用,那我们与这个目标之间的差距在哪里?而且我们如何去衡量这些准确率呢?
赵宇哲:
我觉得要反过来看这个问题。针对特定任务,gap不一定很大。现在Foundation model比传统NLP solution强的地方在于通用性,但retrieval不是一个做什么都行的通用工具。它的定义很模糊,在不同任务中表现差异很大。
Monica:
我最近参加了一个developer meetup,看到Voyage公司在做embedding model,这是RAG架构中的一个重要环节。他们针对法律、代码等不同场景开发专门的embedding model。
李珎:
你指望一个embedding能在大量候选项中找出最佳匹配是非常难的,这不仅是embedding好坏的问题,而是对它的期望过高了。比如推荐系统,TikTok用用户embedding去retrieve最接近的视频embedding,这种关联是由用户行为验证的。Google的ranking也是基于用户点击形成的系统。但常用的RAG方式是基于文本含义构建embedding,不是一个闭环系统。
无常按:在推荐系统里,TikTok用用户embedding去retrieve最接近的视频embedding,这种关联是由用户行为验证的。Google的ranking也是基于用户点击形成的系统——这都是闭环的。但常用的RAG方式是基于文本含义构建embedding,不是一个闭环系统。
姚顺雨:
这是一个training task,是在arbitrary的任务上训练的。
高宁:
那么在现在还缺乏最佳实践的情况下,给企业客户的产品是不是需要根据每个具体任务去交付,这会是一个非标准的过程?
01:04:01 - 01:05:46
赵宇哲:
代码检索有个很好的特点,比如说做法律领域的应用可能会有局限性,但在代码领域,不同企业使用的programming language是相同的。不同的task可能需要不同的retrieval,但如果这个task做得好,即使是不同人写的Java代码,用不同的library和design pattern,基础语言都是Java,所以这是可以transfer的。
Monica:
那么不通用的部分是什么呢?
赵宇哲:
不通用的是自然语言模型直接迁移使用的效果可能不理想。比如说做代码检索的retrieval用来处理其他代码问题,效果可能好也可能不好。对于不同客户,我们会提供相同的服务,这也是很有意思的一点。这让我想到enterprise AI在这一波LLM之前,投入了很大精力做AutoML,当时的目标就是要服务所有公司。
01:05:46 - 01:07:04
说到machine learning,最难的是training。AutoML说可以自动帮你清理model,你只要有数据就好了。但实际发现这个solution并没有那么general。
不过code本身通用性很好,虽然对不同test你可能需要专门engineer一个solution,但这个solution是可以被zero-shot的。
李珎:
因为代码这件事儿,大家做法都一样,都是在写代码。大家大概率都用相同的language,都在相似的环境下面。这和Google之前想target的场景很不一样。程序员的世界相对来说是比较同质的。
姚顺雨:
对,就是在互相抄,大家都在Google上retro一下。
Monica:
但是对于一些大公司来说,因为他们有一些legacy的东西,情况会不太一样。
赵宇哲:
这就是为什么RAG的技术是一样的,我们把不同的内容放在context里面,就可以得到不同的结果。
01:07:04 - 01:08:47
Monica:
我们一直在讨论RAG,是应该靠更好的RAG还是更强的context window来解决问题?比如现在的Gemini有ten million的context window,可能还会更长,你觉得未来会怎么发展?
赵宇哲:
如果说long context会取代RAG,长期maybe,但短期绝对不可能。我们测过,所有模型在处理long context时都很慢,不需要一百万,只要十几万token就需要十秒几十秒,特别慢对吧。不过,当我有这个model的时候,我可以把它转成一个RAG solution。虽然没那么容易,但是非常good。
姚顺雨:
大概率只有一小部分。
赵宇哲:
对,大概只有一小部分。而且如果这个model能读一百万token并且很强,那它大概率知道这一百万token里面哪些部分是有用的。所以这能被转化成一个RAG solution,而且我有这个solution一定比你快。
01:08:48 - 01:09:38
李珎:
而且我觉得从长期来看,有些部分是没有办法被代替的。
赵宇哲:
比如说,你在写程序的时候……
李珎:
对,比如说你需要参考document。以numpy为例,它有非常多版本的document,你始终需要找到正确版本的document来使用,不可能把所有numpy的document都feed进去。这本质上是一个混合了搜索和retrieval的问题,信息可能来自底层代码库,也可能来自外部网站,但始终需要从外界获取信息。你不可能把全世界所有的document都输入进去,必须有一个选择的过程,这个选择过程就是retrieval,就是RAG。
无常按:长上下文能取代RAG吗?短期看不可能,因为太慢了。长期看呢?也很难,为什么?首先你总是需要获取用户更多信息的,你不可能把所有信息都输入进去,所以需要RAG。再说了,就算你把所有信息都作为上下文输入进去,那也必须有一个选项的过程,这个选择过程就是Retrival,就是RAG
01:09:39 - 01:13:41
Monica:
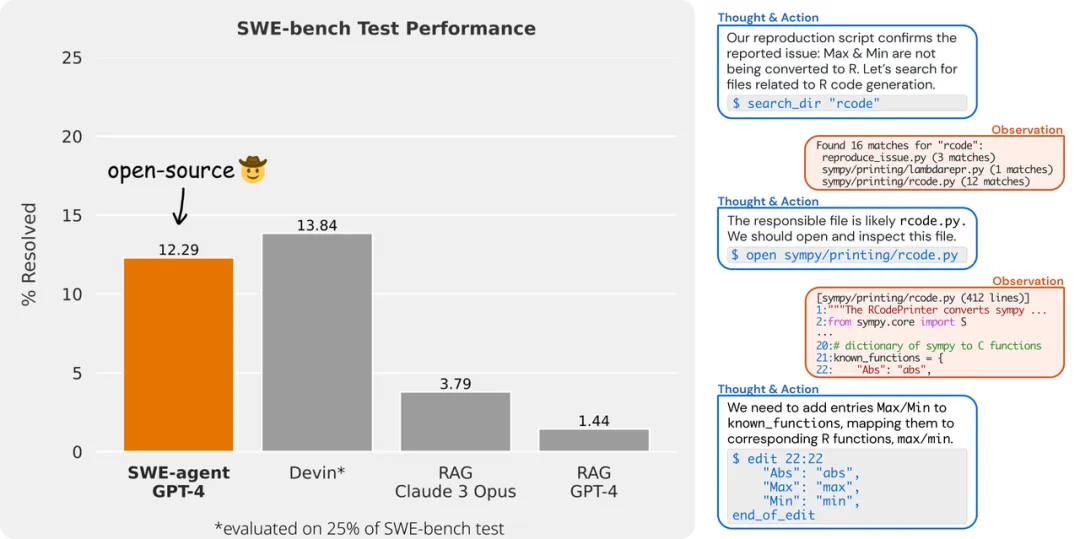
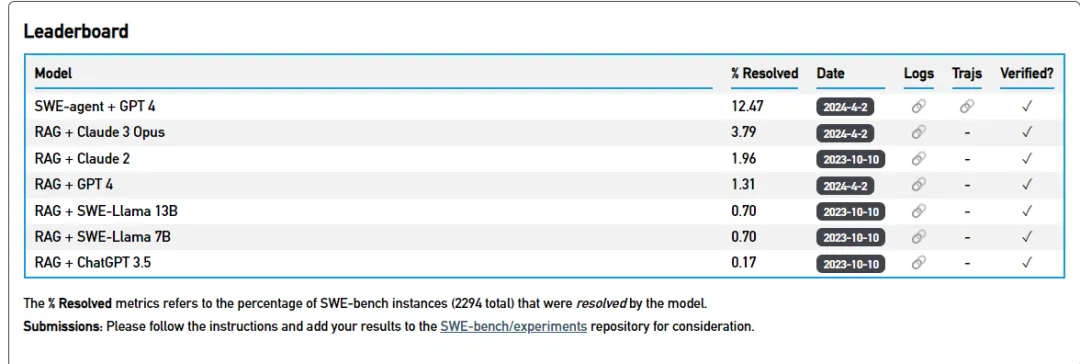
刚才宇哲讲到evaluation这个问题,这确实是我们听到最多的难题之一。特别是在coding领域,这仍然是一个没有共识的问题。正好顺雨最近推出了SWE-bench,现在很多做coding的项目都在用。顺雨,你能给大家介绍一下SWE-bench以及你之前在coding和agent方面的工作吗?
姚顺雨:
SWE-bench的动机很简单,就是现有的coding benchmark不太行。一个好的benchmark应该具备几个特征:第一,要realistic practical,不能只是toy task;第二,需要challenging,不能太简单;第三,需要easy to evaluate,要有好的评估方法。
现在大多数NLP benchmark这三点都做得不够好。比如很多都是toy task,或者是一些简单的问题。像human evaluation这种最常用的benchmark,现在模型已经能达到95%以上的表现。对于agent task来说,evaluation特别难,比如要评估一个web agent的输出好坏就很难判断。
除了这些核心特征外,一个好的benchmark还需要具备一些管理特征。比如要有scalable的数据收集方法,同时要确保数据不会被训练集污染。我们发现GitHub的pull request和issue系统完美符合所有这些特征。
具体来说,task的input很简单,就是一个真实的GitHub issue和完整的代码库,可能有50万行代码。output就是一个能解决问题的pull request。evaluation非常简单,因为可以直接用项目里的unit test。这个任务既实用又有挑战性,目前最好的RAG方案的成功率也只有40%左右。而且数据收集很稳定,我们测试发现不同年份的success rate差不多,即使发生数据污染,我们随时可以获取最新的数据来补充。
01:13:41 - 01:14:25
我们当时非常开心。然后开始去做SWE Agent想要去解决这个问题。
Monica:
让我给大家解释一下什么是SWE-Agent。我们刚才讨论了很多关于coding的AI功能,前段时间一个叫Devin的产品发布了flash demo,这确实给大家打开了新的视野。它展示了agent如何解决更复杂的coding问题,而且不仅仅是帮助写更好的代码,还能解决全链路的问题。我想详细介绍一下思维agent是什么,以及它背后的设计理念是怎样的。
01:14:26 - 01:18:11l
姚顺雨:
对,Sweet Agent的想法其实很简单。在SWE-bench项目中,我们发现用sequence to sequence的方式处理这类任务是不现实的,因为输入可能包含几十万行代码和具体issue。即使使用RAG方案筛选出相关文件,仍然面临很多挑战,因为对人来说,软件开发本质上是一个fundamentally interactive(根本上互动)的过程。
Sweet Agent是SWE-bench任务上的一个baseline agent。我们采用了基本的ReAct Agent (Reasoning and Action)思路,关键在于action space的设计。最初我们尝试让agent在bash terminal中工作,可以查看文件、导航文件夹、编辑文件和运行程序。但很快发现最大的问题是编辑操作缺乏反馈。运行程序时能得到execution result供agent判断,但编辑文件时没有即时反馈,可能出现syntax error或authentication error却不自知。
这促使我们提出了Agent Computer Interface(ACI)的概念。人类使用的Visual Studio Code、vim或Emacs这些都是Human Computer Interface(HCI),我们投入大量时间去打磨这些工具。但这些工具可能并不适合agent。传统上都是固定environment让agent变得更好,比如Atari游戏,而我们采用相反思路:固定一个简单的ReAct agent,专注于打磨environment。最终会有一些co-design,但核心是如何设计最适合agent的interface。
01:18:12 - 01:18:45
Monica:
我们可以向大家描述一下,这个agent能实现什么样的体验,它可以完成什么样的任务?
姚顺雨:
我们现在上线了一个在线demo,你可以复制任何一个GitHub issue的链接,然后粘贴进去,点击一个按钮,它就会尝试生成一个pull request来解决这个issue。
Monica:
如果大家感兴趣的话,这个SWE-agent的演示视频在YouTube和B站上都能看到。
01:18:45 - 01:19:49
我觉得大家看了之后会觉得非常impressive。刚才顺雨讲到SWE-bench,很多RAG-based的solution准确率都在个位数。而最近Devin和sweet agent的准确率都超过了10%,有一个很大的提升。这个提升主要来源是什么?是不是你们的Foundation model用的是GPT-4?
姚顺雨:
对,我们sweet agent用的是GPT-4。我发现一个比较有意思的实验结果,在RAG的setup下,现在Claude Opus已经略微超过GPT-4一点点,大约3.几个百分点。
赵宇哲:
百分之24本身也是很强的。
姚顺雨:
是的,但是在agent这个领域,GPT-4还是比其他model要强很多,比Claude和其他的都要强很多。这可能是因为Claude针对长文本和RAG进行了优化,而GPT-4则是针对agent进行了优化。
01:19:49 - 01:20:27
Monica:
这个three agent能在SWE-bench上比之前的RAG有这么大的提升,主要是什么原因?
姚顺雨:
我觉得有好几个原因。我觉得最根本的原因是它可以去execute代码,你可以写unit test然后去运行。如果运行失败了,你还可以继续尝试修改。这个iterative的feedback loop是非常重要的。如果我只给你一次机会写pull request就立刻提交,都没有机会去运行,那就很难确保代码是正确的。但是execution是一个关键。
01:20:27 - 01:21:32
Monica:
这个跟前段时间大家讨论的agent概念,比如AutoGPT这样的框架是一个概念吗?还是有什么不一样的地方?
姚顺雨:
我觉得不一样的地方就是,AutoGPT和baby AGI这类系统试图把agent本身做得非常复杂,使用各种prompting方法、planning、reflection等技巧。但它们的environment其实很简单,想做一个通用的agent,但效果不是特别好。我的philosophy就是说,如果我们知道要做什么task,就可以针对性地优化工具和environment,让相对简单的agent提升performance。
01:21:33 - 01:24:39
高宁:
你们与Devin之间的差别和准确率差异主要体现在哪些方面?
姚顺雨:
Devin是一个产品,我们是研究项目,目标是解决SWE-bench。Devin作为产品需要处理各种软件环境下的任务。他们采用了一个非常general的环境,包括web browser、terminal、editor和整个AI框架。而我们因为专注于特定任务,可以将接口优化到最适合agent完成任务。虽然我们的API design对各种编程任务都有帮助,但我们的技术路线是优化interface。
Monica:
对于目前10-12%的准确率,你怎么看?你期望达到什么样的目标?
姚顺雨:
我觉得现在大家都还是baseline水平。我有朋友的创业公司可能达到20%左右。我估计GPT-4应该能达到30%,因为SWE agent只是一个简单的agent加上初步优化的interface。Devin是在标准environment下的复杂agent。如果把interface design和agent design结合在一起,即使用GPT-4也应该能达到更好的效果。
Monica:
Devin下面是用GPT-4吗?
高宁:
GPT-4 Turbo发布时官方发了推文at了Devin,应该是说明Devin提前获得了GPT-4 Turbo的接口。
01:24:39 - 01:26:50
Monica:
根据你刚才的说法,现在很多人在讨论agent为什么雷声大雨点小,没有很好的落地。很多人归咎于Foundation model的reasoning能力不行,但根据SWE-bench的结果来看,在现有Foundation model能力下其实还有很大的提升空间。
李珎:
产品化和做research是完全不同的事情。虽然在研究层面看起来不错,但要做成用户能用的产品,需要更多产品层面的思考。
agent与其他AI产品有很大的区别,首先是一个iterative(迭代)的过程,用户需要耐心等待,这种产品形态是前所未有的。与传统软件API相比,一个LLM相当于以前的一个API call,而现在的agent更像是把这些API组合成一个end to end的软件。但前所未有的是需要等待十分钟才能得到反馈。
另外,agent还有一个特点是不稳定,它无法达到90%甚至80%、70%的准确率,更不用说传统软件追求的99.9%的稳定性。
面对这样一个软件,如何让用户能够良好交互并获得价值,需要复杂的设计。
01:26:50 - 01:29:13
Monica:
前面提到,姚顺雨其实一直在agent这个领域做了很多工作,从最早可能从React开始。每个人对agent都有不同的理解,你能跟我们介绍一下你是什么时候开始研究agent的,在这个过程中有哪些重要的研究?
姚顺雨:
我觉得我比较幸运,2019年开始读博士时,我的第一个项目就是在text adventure game中做agent。当时这是个很小众的方向,因为大多数人做agent都是做RL,基本上都是做video game或robots,很少人做基于language的environment agent。
我觉得这个方向很有意思,因为它更接近reasoning,更接近intelligence。我认为life is more like a text-based more than a video game,因为你要做的decision其实很多是open-ended的。比如说今天晚上做什么,action space是open-ended的,并没有一个上下左右这样的键盘去给你指引。你可以买张机票去另一个城市,或者看个电视,有无数种选择。
我觉得language更接近这个事情的本质。做完text game后,我发现text environment和传统environment的本质区别在于它的action space是不需要预先定义的。这就需要reasoning,而reasoning本质上是思考的一部分。为什么传统的agent不如人,是因为人有一个神奇的action叫做思考,但传统agent没有。思考这个action很神奇,因为它没有feedback,你脑子里想任何事情都无法获得外部世界的反馈,所以这个事情是学不了的。
01:29:13 - 01:30:57
Large Language Model为我们提供了parsing机制,让我们能够将reasoning和thinking作为language agent的重要组成部分。通过trail soft的进一步思考,我意识到agent本质上包含两个核心部分:action space和decision making。
action space就是选择什么样的工具来交互,如何设计interface,以及如何进行internal reasoning。
传统上,decision making主要是通过generate next token来产生动作。但我认为,decision making可以通过planning来实现更复杂的决策。我们不只是直接产生单个动作,而是可以在脑子里面模拟多个可能的动作并评估它们。就像下棋一样,我可以预测如果我这样走,对手会怎么应对这样的互动过程。
基于这些思考,我们提出了新的conceptual framework:Cognitive architectures for language agents。本质上,agent就是由action、decision和memory三个部分组成的。
无常按:
清晰到值得重复。本质上,agent由三个部分组成:action space、decision making 和 memory。
action space 就是选择什么样的工具来交互,如何设计interface,以及如何进行internal reasoning。
decision making可以通过planning来实现更复杂的决策。我们不只是直接产生单个动作,而是可以在脑子里面模拟多个可能的动作并评估它们。就像下棋一样,我可以预测如果我这样走,对手会怎么应对这样的互动过程。
memory 是记忆。
01:30:59 - 01:32:43
Monica:
所以你的工作就是从思考逐渐发展到taking actions的研究。我觉得现在大部分的agent工作其实都是在不直接改变Foundation model的情况下,主要通过prompt方式来实现的。
李珎:
会这么理解?
姚顺雨:
我觉得这个事情从根本上存在问题,因为它没有形成闭环,是个open loop。我可以举个例子,现在我们用H200就很像deep learning初期用GPU的方式。当年GPU不是为deep learning设计的,是为游戏设计的。后来大家发现它可以训练AlexNet这些神经网络。接下来发生的事情很有意思:GPU和deep learning method形成了co-evolve关系,GPU促进了更好的deep learning method,而transformer这样的method又反过来影响GPU的设计变化。
language model就很像当年的GPU,最初只是个text generator,但大家用它做各种事情时发现了很多令人惊讶的能力。所以我觉得下一步应该把model和agent进行co-design,把agent的experience和数据反过来fine-tune model。
01:32:43 - 01:33:01
我们有一个工作叫fineac,就是fine-tune React。
Monica:
你们是自己先做了React,然后再做fine-tuning的研究吗?
姚顺雨:
对,因为我一直在等别人去做这件事,但发现没有人做,所以我们就自己做了。
01:33:01 - 01:34:01
Monica:
前段时间在讨论agent这个话题时,有些公司比如Adapt就专门开发了针对agent的模型,我们特别重视模型的reasoning能力。我想请教,是否会出现一个专门针对agent的语言模型?这是否是个伪命题?
李珎:
对,Adapt。
姚顺雨:
我认为agent是个非常宽泛的概念,具体取决于你想要做什么样的agent。如果是想做general purpose的digital agent,我觉得基础模型会更有优势。如果是做vertical domain的特定领域agent,那可能就不需要专门的模型。
高宁:
听起来你觉得这应该是个伪命题。
Monica:
对,结论应该是个伪命题。
01:34:01 - 01:35:07
李珎:
这其实是我创业时的出发点,就是要有个general agent帮你处理各种事务。我们做了一个类似ztier的项目,让LLM来接入各种API。我们接入了Google Calendar、Gmail、订机票、订外卖这些服务。
高宁:
这样就能帮助协调整个工作流程。
李珎:
但实际上这种general agent是个伪命题,因为很难真正产生价值。表面上看能帮你做很多事情,但首先系统稳定性是个问题。其次,如果要处理真正复杂的事务,仅靠API是不够的,需要中间的agent来管理工作流程。而且你要解决的问题越宽泛,就越难让它真正好用。
姚顺雨:
对,它更多需要人机交互才能真正发挥作用。
01:35:07 - 01:38:15
李珎:
对,coding agent的一个很好的特点是它能产生可以自我验证的行动路径,形成一个完整的闭环。当agent通过十步二十步的操作完成任务后,就会生成positive的训练数据。
姚顺雨:
行动路径具体是怎么定义的?
李珎:
这主要是基于OT flow,即用户的edit记录。OT是一种用来解决多人编辑冲突的格式,比如在Google Docs多人编辑时就需要解决这种冲突。它会记录诸如用户在第五行第三列添加内容这样的具体操作。这是一个很底层的用户操作记录,比Google Docs的范围更广,还包括了运行shell、写代码、debug等操作。
姚顺雨:
这些数据真的非常exciting!
赵宇哲:
code也是可以爬的。
李珎:
对,这些数据的独特价值在于可验证性。我们能确认项目是否编译成功、通过测试。这不仅是简单的数据,而是一个达到成功状态的完整轨迹。
Monica:
这有点像Tesla在做的事情。
李珎:
目前我们还在探索如何最好地使用这些数据,包括legal和模型训练方面的考虑。由于记录了每一个操作步骤,整体数据量是非常大的。
01:38:16 - 01:40:52
Monica:
我听说现在有一些agent是用GPT-4来产生action model?
姚顺雨:
这是distillation。这个跟agent没关系。
李珎:
我现在在Replit做agent,它更像是coding interpreter。我们提供预构建的环境,没有React Flow那些复杂的步骤,是更specific limited scope的。用户只需提出需求,比如分析CSV文件,系统就能生成代码并运行。
我们特别关注小白用户,因为他们完全不懂编程,甚至不知道Python是什么,所以更需要agent的帮助。我们有个功能叫bug bounty,用户可以发布悬赏来解决bug。解决者可以是人类,也可以是SWE agent。
这就是为什么我们的CEO和SpaceX的CEO关系很好,因为用户群是一体的。谁解决了bug就能获得奖励。
Monica:
顺雨找到了赚钱的方式了。
高宁:
找到了应用场景了。
01:40:53 - 01:42:04
Monica:
其实刚才顺雨讲到研究课题和产品之间的差异,就在这里。在产品中,即使我说要有human loop,但我必须考虑参与loop的用户是什么样的。比如像宇哲他们的客户,默认都有一定的coding能力;但如果面向完全的小白用户,这时候做human loop的交互设计就会很不一样。
姚顺雨:
我觉得本质上来说,除非是做HCI research,研究就是要minimize human factor,但是product本质上就是all about human。
无常按:Product is all about human 好清醒的研究员!
Monica:
前两天我跟open Devin(一个open source的Devin项目)的团队交流过,也看了他们的架构。因为他们团队都还在企业里做产品,所以特别注重把human loop的交互融入到架构中。这确实和research的思维方式很不一样。
01:42:04 - 01:44:20
我们一直在讨论Devin,我很好奇大家第一次看到Devin demo时的反应是什么?什么让你们印象最深刻?根据目前有限的公开信息,你们还想了解哪些内容?
李珎:
我的第一反应是有人发布了和我正在做的exactly相同的东西。因为我们团队正面对着百万级用户量,有很多infra问题要解决,所以没法发布demo。
不过我觉得Devin确实很impressive,特别是两点:第一是web browsing功能,它可以让agent去浏览网页获取更多信息。对agent来说最重要的两个能力:一是获取信息的能力,无论是通过web还是通过RAG;二是自我validate的能力,就是execute和test。
姚顺雨:
web browsing确实非常难做。
李珎:
对,特别是interactive web browsing,不只是fetch一个网页,还要在网页里进行browsing,这点做得很impressive。另外,他们第一版本还不能让用户修改代码,只能看着它生成。
高宁:
但中间是可以通过聊天方式去干预的吧?
李珎:
对,你可以通过聊天来控制它,但没有直接控制editor的权限。
01:44:20 - 01:46:19
这个我觉得挺surprise的。
姚顺雨:
更像个demo不像个产品。
李珎:
我觉得可能是他们的Design decision去限制scope。但我觉得正确的形式应该是都要具备,这对他们来说实现起来应该也不难。
Monica:
你觉得还有什么想进一步了解的吗?
李珎:
我很好奇他们准备怎么把它作为产品去落地,给谁用。
姚顺雨:
是to C还是to B?
李珎:
对,这也是我们经常思考的问题。这个agent看起来能做所有事情,但你做research是一回事,做公司要卖产品又是另一回事。最重要的是找到product-market fit。是卖给coding小白还是其他人?价格定在这个区间合适吗?这些包装策略我都挺好奇他们怎么想的。
高宁:
因为你刚才提到如果不让工程师过多参与编辑环节,听起来是面向没有编程能力的人。
姚顺雨:
给产品经理。
李珎:
我觉得可能也是因为比较早期,所以先focus在这个方向也make sense。
01:46:19 - 01:48:13
赵宇哲:
我最喜欢的是Danny告诉我的这些东西。我一直在关注这些工作,在离开工作之前我就很喜欢做prompting相关的工作,我们也很早就开始做这些了,效果很好。
说实话,我对agent的工作一直是失望的。比如Langchain之前火过一阵子,大家都在谈论agent可以做这做那,但后来并没有特别显著的进展。虽然Devin在这方面是比较成功的,但我仍然持怀疑态度,因为从一开始我就认为这只是个demo。后来Twitter上也有人说这确实就是个demo。
姚顺雨:
他是直接发布产品的。
赵宇哲:
对,但这本质上不是一个软件问题。这个demo是在告诉你这件事是可能的。关于产品化,我认为如果它真的能在所有情况下都work的话,产品化可能也没那么难。AI政策已经证明了我们无法阻止这个问题的发展。这个任务实际上是automation后面一个level的任务,就是从issue到PR的过程。
01:48:13 - 01:49:22
首先需要写PR,现在有很多重要的tasks,比如如何做code review。这些review工作现在可以用model来辅助,它能够suggest具体的code edits,这些功能已经可以投入service了。如果能把PR这块做好,我甚至可以去负责整个project的架构,这就是architect要做的事情。在企业环境中,当我要build一个function时,会面对大量的code base,需要开发新的feature。
姚顺雨:
对,这些feature可以被系统地decompose成一系列PR。
赵宇哲:
这确实是一个很关键的步骤,这也是我特别看重这个task的原因。关于agent是否是一个好的solution这个问题,我认为从长远来看它一定会很好,是个非常有价值的research topic。但对创业公司来说这是个很大的question mark。如果公司像早期的OpenAI那样不以盈利和产品为直接目标,那么做这个方向很合适。但如果是以product为导向,research的risk就相当高了。
01:49:22 - 01:51:36
姚顺雨:
这个很像当年adapt,一开始做了一个非常fancy的demo,最初是作为research lab使用,后来转向enterprise产品。我觉得dev也可能会往这个方向转。
赵宇哲:
这确实是个很risky的转向。
Monica:
那这个问题是仅限于model层面,还是有其他research需要解决?
姚顺雨:
如果只是作为research benchmark去和GPT-4比较,能做到一个decent的水平。但要做成产品,很多low-level tasks可能就work不了,你可能需要工具支持。
赵宇哲:
对,从产品角度来说,假设我们现在有30%的成功率,提升到了50%。写PR时50%是好的,但问题是通过unit test也不代表完全正确,unit test的coverage就是个问题。如果50%不好,谁来改它?如果它能自己改好就不会只有50%了。那程序员可能会想,我是不是自己写一遍更快?
姚顺雨:
但你觉得unit test真的能实现完美的evaluation吗?
赵宇哲:
我们内部试过,效果没那么好。GitHub上很多项目甚至都不写unit test,质量也参差不齐。而且通过unit test不代表代码就对了,有时候代码错一点点通不过测试,但实际代码质量也没那么差。
01:51:36 - 01:52:22
你的test质量可能没那么好,但是PR相关的test会稍微好一点,因为它会涉及好几个部分,而且有好几个原有的test去cover。不过也不是所有PR的test都这么好。
姚顺雨:
我们当时做这个的时候,就选了比较高质量的test。
赵宇哲:
对,这就是很重要的部分。如果随便选一个,那validation的效果就没那么好。我们试过这种情况。
姚顺雨:
在理想情况下,假设你有一个非常高质量的evaluation,那即使是10%的随机选择其实也是可以work的,因为你可以试一百次,然后只要把unit test通过就行。
01:52:22 - 01:53:46
Monica:
如果我们给AI一个test,想看它的完成准确率是多少。我们可以把范围限定在junior engineer的任务上,毕竟你也不会给junior engineer太难的test。假设在这些junior的工作范围内,它能达到80%、90%的完成概率。
姚顺雨:
可以。
赵宇哲:
这个可以去设计,但这就变成产品设计时要control你的user expectation。你要考虑怎么定义user,不要让他们滥用这个功能。因为有些PR大有些PR小,简单的PR让AI做是很好的,但推产品时你需要把user定义得比较清楚,否则他们一开始就会觉得这个不行那个不行。
Monica:
这有点像我们招程序员一样,你招不同level的人,布置任务时也会考虑。比如给宇哲布置任务和给一个刚毕业的布置任务是不一样的。我在想,当我们把agent也当成一个人来看的时候,我们assign task的方式是不是也应该不一样。
01:53:46 - 01:55:13
李珎:
对,这个事情正在发生,很多小的task,比如写unit test、进行重构(rename)或者debug这些工作,都是可以交给junior engineer来做的。在软件开发的各个步骤中,已经有很多创业公司在专门针对这些任务开发产品,比如swift dev。
我们发现需求定义越明确,完成的成功率就越高;需求越abstract,就越需要interactive的步骤和人工介入。所以我们对agent的思路是把它定位为协作伙伴,不是简单地交付任务给它。它会在code base和repo中与你collaborate,当它在后台运行时遇到问题,会发送notification给你,让你指导它如何proceed。
01:55:13 - 01:56:06
Monica:
用户不能太小白。这就像甲方和乙方的关系,通常甲方什么都不懂,这些东西是没办法的。
李珎:
这是不同level的问题。这样的用户不会问你技术层面的问题,而是会问需求方面的问题。比如说你要做website,他会问你这个website要不要dark mode啊,你觉得这个好不好看,要不要改一改?right,这些问题对于小白来说其实是make sense的,而且他需要问这些问题,这样才能让最终生成的东西符合你的期待。
Monica:
那其实这个agent就远不止是一个coding的agent。
赵宇哲:
对,要求比较高,需要会跟人交流。
Monica:
这就像个乙方,我觉得这个真的适合SWE-bench。
01:56:07 - 01:56:46
赵宇哲:
如果这个agent真的很优秀,它就很适合作为contractor来帮你完成工作。
Monica:
我们前面可能需要一个agent来evaluate,判断这个问题是否能被现有的agent解决。如果当前agent无法处理,系统会将你分配到其他合适的agent。它甚至可以帮你自动分配一些任务给人类操作员。
李珎:
我们可以想象这样一个世界,你可以雇佣很多不同的agent。比如SWE-bench是一个可以雇佣的agent,Devin是另一个选择。你可以像查看LinkedIn简历一样,看到他们之前完成过什么样的任务,有什么样的工作记录。
姚顺雨:
最终还是要用赚钱多少来衡量,这是最基本的评判标准。
01:56:46 - 01:58:00
Monica:
我注意到你们最近发表了一篇关于Olympia programming的论文,似乎是针对更复杂的数学问题。我很好奇能否介绍一下这个项目,以及它与SWE-bench有什么关系?因为听起来这两个项目都在解决复杂的问题。
姚顺雨:
这其实是coding这个问题的两个不同frontier,是两个完全不同方向的frontier。SWE-bench本质上处理的内容没有那么复杂,它更多关注的是long context和noisy context的处理。而Olympia problem则完全相反,它的问题和代码都很短,可能就十到二十行,但更注重grounded reasoning、creative reasoning algorithm和organic reasoning。所以一个是考验你对长文本和复杂context的处理能力,另一个则是考验你对CHV这个grounded的理解和augment。
01:58:00 - 02:00:31
Monica:
你觉得解决数学问题和奥林匹克编程问题之间有什么关系?
姚顺雨:
我觉得奥林匹克编程问题更接近于测试基础模型的推理能力。比如说,有N个人站成一列,需要进行某些操作,问有多少种可能的方案。这类问题需要你在空间中进行想象,理解组合的意义,做world modeling和simulation。传统的软件工程更多是pattern recognition,比如搜索stack workflow和复制代码,不太需要这种深度推理。
李珎:
软件工程的问题只要投入足够时间总能解决,但奥林匹克编程中有些问题即使投入再多时间也无法解决。
姚顺雨:
对,我在debug时常常只需要搜索已有解决方案,不需要太多推理。软件工程主要是处理大量的知识、复杂的上下文和noisy situation。虽然世界上有数百万程序员,但真正擅长编程竞赛的人并不多,因为那需要更强的world modeling、simulation和organic reasoning能力。我认为这两种能力是通向AGI的重要维度。
02:00:31 - 02:01:48
Monica:
我其实很好奇想探讨一下关于Foundation model或LM能力边界的理解。因为从Chain-of-Thought的发展来看,仅仅是在prompt层面的改进就能带来效果上很大的区别。所以我很想知道,当我们讨论现在LLM能力不足时,到底有多少是模型本身能力的局限,又有多少是我们还没找到正确方式来释放它的能力?
姚顺雨:
我觉得这个问题可以从两个部分来看:一部分是你怎么去训练模型,另一部分是你怎么使用它,也就是我们说的prompt。模型能力的边界就取决于这两点。比如我刚才提到GPU H800的例子,我认为它应该形成一个闭环,就是我们使用模型的方式应该反过来去影响我们如何训练这个模型。
因为如果我们使用模型的方法跟它训练时的数据不一致的话,它就没有办法释放它的能力。我们现在释放的这些能力其实都是所谓的 emergent properties。我觉得我们现在使用这些方法可以给我们一些 insights。可以帮助我们 improve 这些虚拟的网络。
02:02:15 - 02:04:15
Monica:
我觉得在讨论LLM的limitation时,大家经常提到predict next token的方式像是一种快思考。而科学研究和更深层次的创造,大家认为需要system 2 thinking这种慢思考。但我记得你的paper中提到,通过prompt就可以实现system 2 thinking。这是否意味着模型本身具有慢思考的能力,只是我们还不知道如何使用?如果真的具有这种慢思考能力,是否意味着它已经可以帮助我们解决复杂的科学发现问题?我在想,是不是我们使用它的方式限制了我们对LLM边界的想象?
姚顺雨:
你说的应该是Chain-of-Thought这篇paper。这篇paper的核心思想是,如果我们把next token prediction看作是一个system one的快速过程,那么对于system two这种慢思考来说,它其实是一个对system one的控制。
观众:
Control AGI over system one。
姚顺雨:
对,它是知道什么时候去stop这个flow然后switch to something else,更多是对system one的一个control。它并不是独立于system one存在的东西。所以tree of thought的本质是通过tree search这样的控制机制来control system one,而不是去替代它,而是去impose control over system。
我们其实当时试过一些更难的任务,比如说去做unipl programming,或者一些我们认为更接近AGI的任务。
观众:
你说的是task对吧?
姚顺雨:
对,但现在的模型还是无法完成这些任务。我觉得很大一个原因就是它的self evaluation能力还不够强。比如说让它写三段代码,它很难判断哪一段代码更好,因为这并不是它训练过程中学习的内容。
赵宇哲:
这是经典的reinforcement learning问题。
姚顺雨:
对,我们怎么去使用这个模型其实反过来会告诉我们模型在哪些能力上有不足,我们应该去针对性地改进。
02:05:01 - 02:06:32
Monica:
根据我们现在的使用方式,你觉得接下来应该往哪个方向去improve呢?
姚顺雨:
这是一个比较抽象的问题。我们面对的是一个解空间,这条路径可能找到解。
赵宇哲:
这本质上是个搜索问题。现在我们已经找到了一条路径,但不能就此停止。这样太简单了,我们需要去sample这个空间。这就是大家在做agent prompting时在做的事情。最开始Chain of Thought只走一条路就结束,后来有一篇paper叫self consistency,提出可以sample多个结果并把它们结合起来,实验证明效果确实更好。我们可以使用更复杂的搜索方法。
另外,第二个改进方向是要提升sampling model本身的能力。虽然RL是个很难训练的方向,但language model有个很好的特点:只要你知道哪些数据是好的,就总是可以把它反馈回去。
02:06:33 - 02:07:13
相信大家都应该做这件事情,但这并不容易,因为所需的data并不存在。这些data需要找出来。这也是已经在发生的事情——现在有很多人要么用已有的language model去filter和select预训练数据,要么直接生成训练数据。
高宁:
你的意思是用language model来做这个?
赵宇哲:
对,就是用它产生的数据、feedback,或者其他任何形式的反馈来优化。但这个方向能走多远,现在还不知道。
02:07:13 - 02:10:20
Monica:
关于agent,最近大家讨论比较多的是multi agent。我看到replay中有一个multi player的AI chat功能,能否介绍一下这个feature?
李珎:
这其实是multi agent system的一个前置工作。我们原来的AI chat只支持单人对话,而multi player chat允许多人同时share一个chat window,可以看到其他人的消息。它有点像email系统,你可以看到每个人的消息streaming的过程,有不同的session。
Monica:
这是说agent可以和多个人互动吗?
李珎:
目前这只是一个面向多用户的chat系统。但它是agent的前置工作,因为我们意识到,如果需要多个agent在后台工作,就需要一个情报接收系统来监控它们的工作状态。比如在report里面,同时agent也在work on this report,你需要看到它们在做什么。即使你把笔记本电脑合上,agent仍在工作,重新打开时还能看到工作进展。我们的chat其实就是一个UI去看agent is working。
agent需要与人进行互动,可以通过对话或button形式。比如当agent需要进行deploy这样的重要决策时,就需要询问用户确认,因为这涉及费用支出。我们需要考虑很多产品设计问题,比如什么时候该询问用户、什么时候让agent在后台工作。agent的state很复杂,它有很多observation,你也许不想看到那么复杂的东西,只想知道它在7x24小时地为你工作。这就是我们ft五类现在正在做的事情。
02:10:20 - 02:13:02
Monica:
你们怎么定义multi agent system?为什么我们需要它?
姚顺雨:
我觉得本质上是个inference time scaling的逻辑。我们最终希望在inference时用更多compute来获得更好效果,增加agent数量就是scaling up的一种方式。不过现在base agent还不够强,要等它达到一定水平后,multi agent的scaling才会真正发挥作用。就像团队协作,如果大家都很菜,人越多越乱;但如果都够强,两个人可能比一个人效率快两倍,三个人可能再快1.5倍。
李珎:
multi agent其实有两种不同定义:第一种是多个agent做同一件事,第二种是不同agent负责不同任务。比如MetaGPT这个项目,它模拟了一个完整的公司架构,有CEO、PM、程序员、reviewer,每个角色都有不同的prompt。在我们的设定里,用户和agent都是第一公民,这是很重要的理念。
02:13:02 - 02:13:18
姚顺雨:
这更像是一个 multi prompt,并不像一个 multi agent。
赵宇哲:
我想问这个问题,如果你用的都是 GPT-4 的不同 system prompt,一个 prompt 对应一个 agent...那这是不是就是一个人格分裂的 agent?
02:13:18 - 02:13:39
Monica:
既然Devin已经可以作为一个self agent完成从编码到单元测试的整个流程,甚至能够自己进行代码review,那为什么还需要不同的角色呢?
李珎:
我理解啊,我理解就是……简单的case就是不同的prompt,大家都知道给模型不同的prompt会带来不同的表现。如果你告诉它你是一个software engineer,它生成的代码就会比告诉它你是普通人要好得多。即使是同一个模型,你用不同的prompt方式,包括chain of thought等方法。
赵宇哲:
对,可以用不同的方法。
李珎:
从交互的角度来看,它给你的结果质量是完全不一样的。即使是同一个模型,它也会被当作不同的角色来对待。
高宁:
考虑到未来的成本和效果的性价比因素,各个小的agent背后不一定都需要用GPT-4这样的模型,而是可以用专门的模型,比如代码补全的模型、testing的模型,这样更合理,让它们各司其职,真正成为替代某个职能部门的agent。
李珎:
对,其实大家关心的只是谁能把这个工作做完。
02:14:51 - 02:15:08
赵宇哲:
你是全能选手对吧?
李珎:
让Devin来帮我写这个代码还是说让一个Newgrass帮我写这个代码,你只要能写好,我其实不是很care。我甚至更希望一个Newgrass帮我写代码。
高宁:
不然还欠Devin一个人情。
02:15:09 - 02:17:24
关于multi-agent系统设计,你觉得主要挑战是在能力层面吗?我们是否需要结合具体场景来考虑?
李珎:
这个问题要看你从哪个角度思考。作为更接近产品的人,我发现一个很大的问题:现有模型的强大能力并没有真正传递到用户手上。比如说GPT-4,当我发现它给我的代码质量比我雇佣的前端工程师还要好时,我就意识到AI已经能产生巨大的价值,但这个价值还没有真正普及到大多数人手中。
我建议从两个维度来看这个问题:假设当前AI能力是60分,但大多数用户可能只享受到20-30分的能力,有些甚至是零分。从产品角度,我们的工作是让更多人能享受到这个60分的能力;从研究角度,则是要把这个60分提升到80分甚至100分。当上限提升后,普通用户享受到的能力自然也会相应提升。
姚顺雨:
一个是push frontier,一个是help people实现价值。
赵宇哲:
这个比喻很贴切,就像造纸局和用纸局的关系。造纸的人关注如何提升能力,用纸的人关注如何让更多人用起来。不过现在确实还是一个research phase,绝对是research phase。
02:17:24 - 02:19:37
Monica:
我们聊了很多技术细节和产品的事,现在可以畅想一下未来。说到这个,贵司真的很会写blog,这种水平AI可能一时半会还写不了。
李珎:
写paper就写blog。
Monica:
你们的blog里提到"AI is redefining the whole software development life cycle"。但仅仅是auto complete这些功能并不算是真正的redefine。那么未来一到三年内,整个life cycle会有哪些大的变化?
李珎:
AI redefining software engineer life cycle其实很好理解。现在的software engineer工具和life cycle都是为人类设计的,我们都是考虑电脑前面坐着一个人需要什么样的工具。但如果从AI角度考虑就完全不一样了。比如git有十几年历史了,一直没有什么进化,对人来说可能make sense,但对AI来说未必。如果把AI视为第一生产力,我们就需要重新思考如何设计git,甚至programming language。
姚顺雨:
你觉得有什么东西是需要重新设计的?
李珎:
IDE肯定需要重新设计。不过说实话,我现在还没想到什么东西是fundamentally需要重新设计的。如果真的想到了,我会立即开始做这件事。
赵宇哲:
这确实是个很好但很难的问题。
02:19:37 - 02:22:43
姚顺雨:
很多东西在大部分情况下可能没有本质区别,对Python和C来说,只要有足够多的数据都能学会。
李珎:
但有些东西是一定不会被取代的。我觉得首先很重要的是跟现实世界的交互动作。比如说,软件公司里面很大一部分工作是AB test,这其实就是validation的部分。你的模型再强大,你都需要去validate你的答案是否正确。比如你现在有个电商网站,做了页面改动,这个改动对网站revenue是正向还是负向的?模型再强大也不知道,除非你去测试。所以这部分工作不仅不会被取代,反而需要被重新设计,思考如何让模型更好地去测试。
赵宇哲:
这个问题很好但确实很难。我比较喜欢把这个类比成自动驾驶。有人直接做L4自动驾驶,就会考虑要不要方向盘,没有方向盘后车该造成什么样。这个问题很valid,但存在风险且难以预测。另一条路径是先把基础功能实现,从用户那边学习,看他们使用时发生了什么变化。
对编程语言来说这是个很大的变化。从C、C++开始,编程语言一直在演进,目标就是让编程更容易更简单。现在通过AI工具可以直接得到可执行的代码。未来不会再有说我只是个C++程序员,不写Python这种情况。工程师加上copilot,或者copilot本身就会成为全能的代码编写者。这种变化已经在发生,影响了大家对language和syntax的态度。比如proto就在努力让数据传输在所有语言里都能实现,这是个很好的例子。
02:22:43 - 02:23:30
如果以后我们真的能成为language-agnostic的开发者,那是不是就能有一些library可以随意调用各种编程语言的feature,然后通过自己写的middleware来作为portal统一管理这些功能?
这件事对开发者来说其实很烦的。比如说我开发了一个项目,然后发现用Rust实现更好,需要重新写一遍,这真的很烦。不过以后这个问题应该会得到解决,因为确实有很多场景需要用另一种语言重写项目,这件事情很值得去做。
姚顺雨:
GPT可以做这个。
赵宇哲:
对,因为这些事情本质上就是translation,这个问题其实并不难解决。
02:23:30 - 02:24:09
高宁:
这个跟大语言模型的多语言能力是一个相同的道理。
赵宇哲:
对,这个原理并不难,模型能做得很好。这会带来很大的变化,具体意味着什么我现在还不太确定。但我有一个prediction,就是"next billion"一定会发生——它会降低编程门槛,提升整体能力水平。有人说它会replace程序员,但不会的。它会让所有人都变成程序员,让好的程序员变得更好。这真的很棒。
姚顺雨:
我认为如果AGI实现,它将能够完成任何工作,软件开发只是其中之一。软件开发的独特之处在于它具有较高的feedback数据,这使得AI在这个领域可能有更多学习机会。相比之下,像人际交往这样需要真实互动的任务就非常微妙,对吧?这个相对来说是一个比较不well-defined的任务,这反而是AI的优势。
具体来说,task decision是非常重要的。比如Should your agent take care of the unit test? Should your agent take care of the code body? Just high level decomposition make sense。一方面,我们需要探索现有模型的边界,研究如何让它做得更好;另一方面,我们也需要这样的人 to make the base model value,最重要的是two people should communicate。
02:25:45 - 02:27:27
Monica:
我看到顺雨最近做了一个关于language agent的social impact研究,想请你谈谈language agent对社会和工作的影响。
姚顺雨:
我分享研究中的一个重要发现。我们构建了一个金字塔模型来描述不同工作被替代的可能性。金字塔第一层是business tasks,第二层是collaboration和communication,最上层是design和high-level exploration。
最容易被替代的是第一层,就是那些重复性强且需要可靠性的business工作,比如客服、报税或基础法律服务。这类工作可以用代码和固定流程来处理,不需要太多人际互动。
第二层是collaboration,需要同时掌握与人和计算机打交道的能力。与计算机交互是well-defined的,但与人打交道则需要理解pragmatics,学会如何与人合作,这是非常tricky的。
最难被替代的是最上层,涉及开放性探索的工作,比如scientific discovery或theorem proving这样需要创新思维的领域。
02:27:29 - 02:28:46
Monica:
既然你们提到AGI,刚才顺雨那篇文章讲到的social...
赵宇哲:
我有点surprise,这三层太过了。我是一个contrary的观点。对于失业这个问题,从长期来看对人类社会是好事,但对个人来说是很不好的事情。这种情况每次技术革命都会发生。就业总量我不觉得会减少或增加。当然,如果说所有工作都被机器人替代了——最近robotics确实很火,这也是个很好的方向——那谁知道还会有什么工作可以创造呢?但短期内一定会有人失业,这些人就会成为不稳定因素。美国工业革命时期就发生过这样的事情。这让我觉得有点无语,情况没那么乐观。
姚顺雨:
可能还是需要三个结合起来。
02:28:46 - 02:31:04
赵宇哲:
我是从BERT开始做的。说起LaMDA的故事很有意思,我做完后超级喜欢这个项目。LaMDA团队的Daniel后来去做Character AI,因为他是个语言学习者,喜欢聊天和chatbot。Character AI不会去做AGI,因为包括Norm和Daniel,他们都不在乎刷benchmark,只想要做chatbot。Google不给他们做,他们就自己去做了。
那时候我们做research、发paper都挺好的。我当时没觉得Google太谨慎,因为它有自己的理由。但ChatGPT出来后整个世界就变了。我说我是受害者就是因为现在好好做research都做不了了,大家都去做product。虽然还有很多有意思的research方向,但现在整个research风气都变成只能拉着模型去做study。这更多变成了engineering相关的工作。我不是说engineering不是好的research,但在这之前确实有很多其他有意思的research方向。
这个技术不仅影响我们这些直接做research的人,还会影响很多其他工作岗位,带来巨大的social impact。我虽然希望这个技术发展,因为它是很好的technology,但发生后怎么办?这个工作变得有点sick,因为完全被资本追逐。我本来觉得这是个很好的工作,比如Google做东西是为了更好的产品,但后来发现不是这样。
ChatGPT出来之后,推动AI发展的其实不是AI界,而是整个VC和资本。资本看到了所有的机会,这个势头已经完全停不下来了。
无常按:被资本裹挟的研究,压力巨大。最近Google DeepMind的一位科学家,就确实在这样的压力去世了,RIP。
Monica:
这就像GPU和AI的相互推进一样。GPU最早是游戏领域吸引资金,后来AI吸引了最多的投资,这又推动了GPU的发展方向。
李珎:
因为后面可能创造的价值和可以取代的价值都太大了。
Monica:
它的想象空间很大。
赵宇哲:
从Google来看,它的文化是肉眼可见的在下降,还在进行裁员,面临很大压力。很多人都是从Google跑出来的。在推广过程中,我们发现用户也面临很大压力,所有人都觉得必须要学会使用这些AI工具。
高宁:
现在有自媒体在贩卖焦虑,说不会用就要落伍了。
赵宇哲:
但实际上大部分人并不那么喜欢学习,喜欢跟进新东西的人是少数,所以就会产生很多焦虑。
02:33:24 - 02:33:32
Monica:
对你刚才说的很好奇。那些你觉得本来很有意思可以继续的研究项目,比如说有哪些是你希望能继续但没有能继续下去的?
02:33:33 - 02:34:54
赵宇哲:
现在很多领域都在转向,比如machine learning领域的一些应用,像Siri这样的项目。
姚顺雨:
已经不做了,现在都不再吹LLM了。
赵宇哲:
对,很多statistician都不再做统计理论研究了。我以前做过很多machine learning theory的研究,觉得这些理论真的很漂亮很有意思。我特别喜欢graphical model,这些东西真的很酷!但是你能看到,现在很多researcher已经不做这些研究了。
对研究领域来说,我觉得这绝对不是好事,因为还有很多值得继续深入的研究没有完成。
02:34:55 - 02:36:23
Monica:
我前段时间去了几趟东岸。在硅谷我们经常感觉特别被overwhelm,但东岸的环境确实更diverse。我在纽约期间跑了一圈Yale、UPenn、NYU,还有MIT、Harvard,参与了很多AI的讨论。这边可能整天都在讨论AI,但东岸的AI讨论总是会结合biotech、healthcare等领域。
前两天在MIT,我主持了一个panel,除了真格的合伙人外,另外三位都是哈佛的professor。他们分别研究AI in Healthcare、电池材料,还有一位是研究theory的。这种多样性让我特别有感触,希望能保留这些研究方向。
赵宇哲:
用AI做biotech的其实一直都有。我有个很好的朋友就是做material science的,他们在用model去做predict。
Monica:
我理解你说的,有些更偏研究数学原理的美的东西可能被忽视了。
赵宇哲:
是的,machine learning的研究有些趋同,但如果你跨领域使用machine learning去研究其他对象,我觉得这个是很好的方向。
02:36:24 - 02:38:52
Monica:
就是做AI。
李珎:
不,是做biotech。我觉得这是一件很好的事情,因为AI正在非常大程度地加速biotech和healthcare的研究进展。我们之前开发的产品,现在还在继续做,就是帮助biotech这些早期公司的研究员生成代码,帮他们生成insights来确定下一步研究方向。
这其实是很有用的。你要知道,他们的研究周期都是非常长的。比如我有一个朋友,他在研究定向杀死衰老细胞,换句话说就是在研究长生不老药。他们正在用AI去predict下一步应该用什么样的蛋白质结构最可能发现好的药物。
这个过程是这样的:虽然实验现在还是要人来做,但做完实验后会给AI feedback,然后再去做下一步predict。这个过程is actually happening,你并不需要依赖AGI直接设计出长生不老药,但GPT-4正在切实地帮助这些biotech研究者确定他们的下一步方向。
这是AI带来的社会影响中少数几个比较好的事情。也许很快我们就能把人类的寿命延长到120岁、150岁,甚至200岁。如果没有AI,这个速度一定会更慢。AI可以帮助我们解决一些我们一直想解决的问题,比如癌症等。听起来很玄幻,但在我创业过程中接触了很多药厂和biotech公司,这就是他们每天都在思考的问题:如何让人类活得更久。
02:38:52 - 02:41:09
高宁:
从coding到展望未来再到social impact,我们有了很好的收尾。现在进入快问快答环节,准备了三个问题。
Monica:
大家控制在半分钟到一分钟回答。
高宁:
第一个问题是今年在工作或研究方向上的小目标是什么?先请顺雨回答。
姚顺雨:
把现在的项目wrap up,然后开启新的篇章。
李珎:
我的目标是让足够多的人能在Replit上创造他们自己的软件,即使不会编程也能通过它赚钱。作为创业者,我深知只有当你的idea能带来实际价值时,才能感受到它的意义。你可以做一个toy项目,但没人care;而大多数人都需要他们的产品被人care。我希望能让足够多的人在Replit上创造自己的产品,without knowing how to code。
赵宇哲:
我希望能保持现在对工作的热情。
Monica:
现在驱动你保持热情的是什么?
赵宇哲:
我很喜欢我们的团队。从长远来看,我希望能和团队一起见证technology对Embodied Intelligence的发展。这是一个可以预见的结果,特别是在self engineering方面。
02:41:09 - 02:42:33
Monica:
那我问个轻松点的问题,大家在研究AI和工作之余最喜欢做什么呢?
姚顺雨:
我喜欢打篮球和看书。
Monica:
最近在看什么书?
姚顺雨:
最近在看李飞飞的自传。
赵宇哲:
我比较喜欢速度类运动,特别是赛车。我也喜欢跳街舞。
Monica:
哇,我们这里有rap、街舞还有赛车,太酷了!
高宁:
那最后想请教大家,对未来一年和三年在AI领域最期待的事情是什么?
姚顺雨:
我对未来一年最期待的是general purpose computer agent。
Monica:
这么激进吗?
赵宇哲:
我很想知道GPT-5会是什么样子。
李珎:
这个可能不需要一年就会出现。
赵宇哲:
但我特别想了解它的具体能力会有多强。
02:42:34 - 02:43:58
高宁:
我对未来三年很期待。
赵宇哲:
我特别关注Control和纯AI的发展。multimodality一定会成为强大趋势,我认为它最强的展现形态之一应该是与mission Pro结合。
姚顺雨:
纯AI就不是general AI。
Monica:
看来大家都在谈论三年期限啊。
李珎:
在coding方面,我其实更关注短期发展。我很好奇在一年内我们是否能达到一个闭环,让人们不需要编码就能创造自己的软件。当然,这很大程度上要依赖于GPT-5的能力。另外,我觉得三年内biotech和healthcare的进展会很令人期待,发展速度可能会比很多人想象的快得多。
高宁:
长生不老!
李珎:
对,我非常希望我朋友的公司能实现长生不老药,这样我也能占到光。这确实是一个巨大诉求。
赵宇哲:
这将是超越Facebook的成就。
02:43:59 - 02:46:44
Monica:
我们最后要让大家知道,我们的AI研究者都是多才多艺的。要知道,顺雨是清华说唱社的创始人。在AI即将颠覆音乐的时刻,要不你给来一段rap?
姚顺雨:
真的退休了,不过我可以播放我之前的作品。
高宁:
好的,谢谢今天大家的时间,我们聊到了晚上差不多11点,将近三个小时。我们也非常期待大家一年之后有机会再来跟我们一起聊一聊,看看这一年的期待有没有实现。
https://www.cognition-labs.com/
https://www.cognition-labs.com/introducing-devin
https://twitter.com/cognition_labs/status/1767548763134964000
文章来自微信公众号 “ 张无常 “,作者 ” 无常 “,一个喜欢码字的AI产品经理



【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
