# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

一段音频+一张照片,瞬间照片里的人就能开始讲话了。

生成的讲话动画不但口型和音频能够无缝对齐,面部表情和头部姿势都非常自然而且有表现力。
而且支持的图像风格也非常的多样,除了一般的照片,卡通图片,证件照等生成的效果都非常自然。

再加上多语言的支持,瞬间照片里的人物就活了过来,张嘴就能飙外语。

这是由来自南京大学等机构的研究人员提出的一个通用框架——VividTalk,只需要语音和一张图片,就能生成高质量的说话视频。

论文地址:https://arxiv.org/abs/2312.01841
这个框架是一个由音频到网格生成,和网格到视频生成组成的两阶段框架。
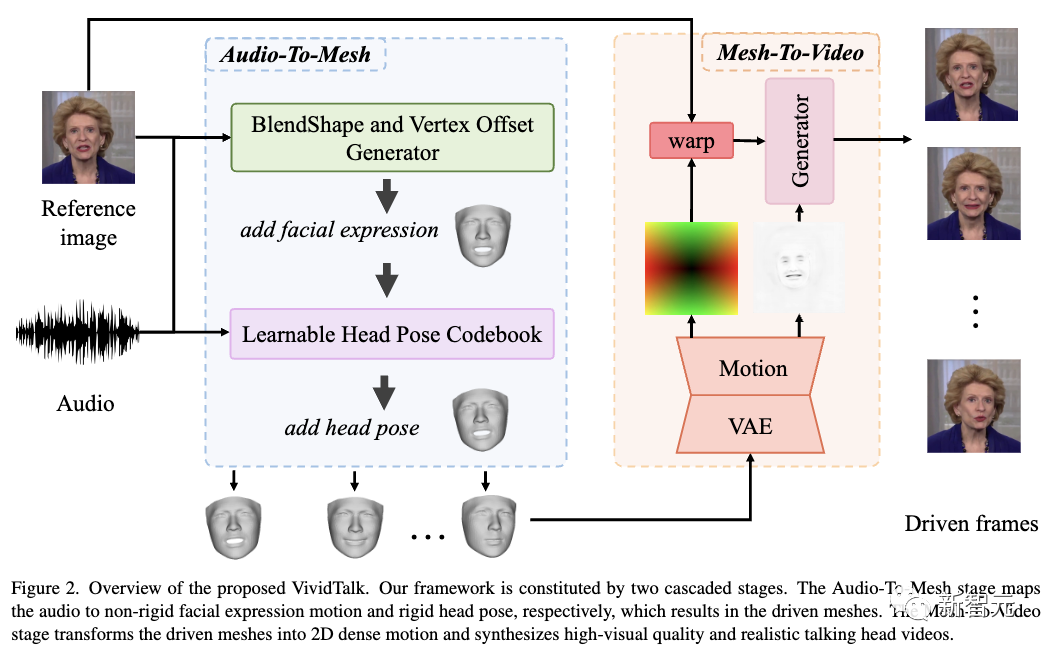
在第一阶段,考虑面部运动和blendshape分布之间的一对多映射,利用blendshape和3D顶点作为中间表征,其中blendshape提供粗略运动,顶点偏移描述细粒度嘴唇运动。
此外,还采用了基于多分支Transformer网络,以充分利用音频上下文来建模与中间表征的关系。
为了更合理地从音频中学习刚性头部运动,研究人员将此问题转化为离散有限空间中的代码查询任务,并构建具有重建和映射机制的可学习头部姿势代码本。
之后,学习到的两个运动都应用于参考标识,从而产生驱动网格。
在第二阶段,基于驱动网格和参考图像,渲染内表面和外表面(例如躯干)的投影纹理,从而全面建模运动。
然后设计一种新颖的双分支运动模型来模拟密集运动,将其作为输入发送到生成器,以逐帧方式合成最终视频。
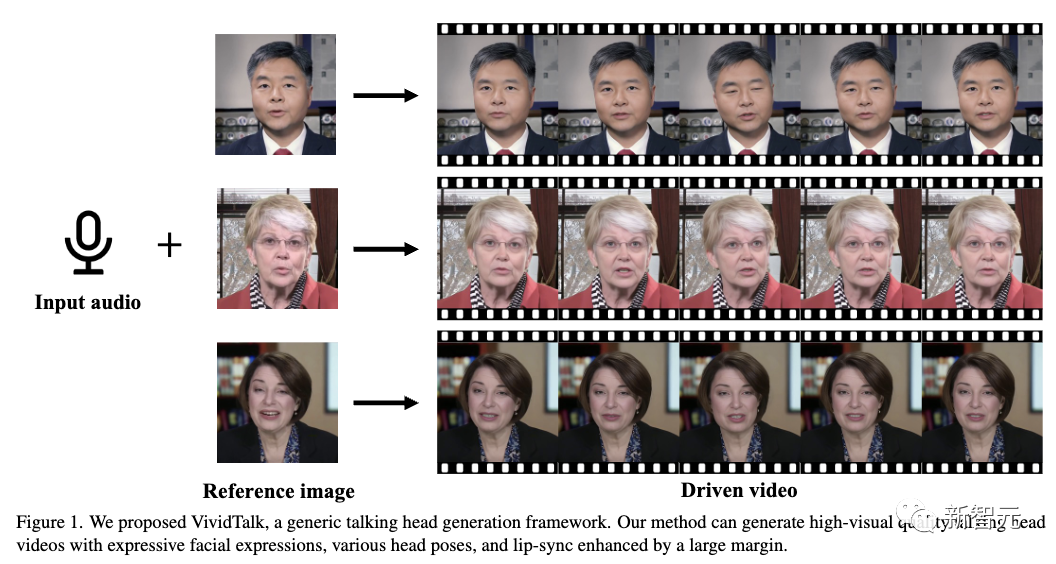
VividTalk可以生成具有表情丰富的面部表情和自然头部姿势的口型同步头部说话视频。
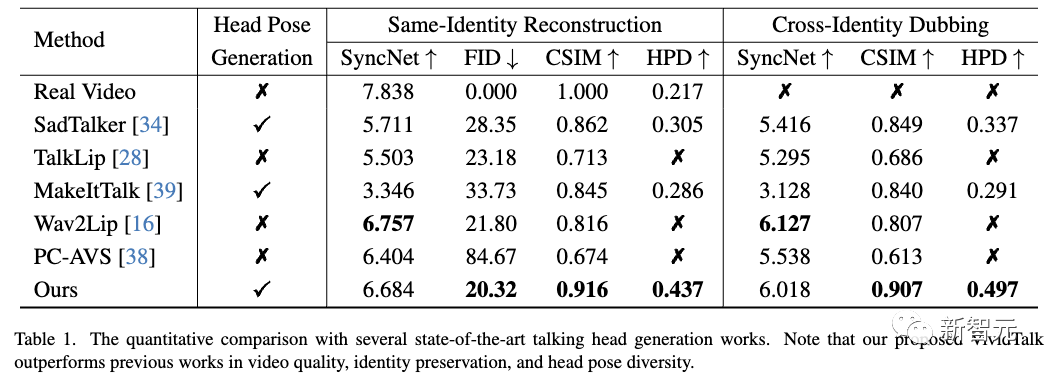
如下表所示,视觉结果和定量分析都证明了新方法在生成质量和模型泛化方面的优越性。
给定音频序列和参考面部图像作为输入,新方法可以生成具有不同面部表情和自然头部姿势的头部说话视频。
VividTalk框架由两个阶段组成,分别称为音频到网格生成和网格到视频生成。
这一阶段的目标是根据输入音频序列和参考面部图像生成3D驱动的网格。
具体来说,首先利用FaceVerse来重建参考面部图像。
接下来,从音频中学习非刚性面部表情运动和刚性头部运动来驱动重建的网格。
为此,研究人员提出了多分支BlendShape和顶点偏移生成器以及可学习的头部姿势代码本。
BlendShape和顶点偏移生成器
学习通用模型来生成准确的嘴部动作和具有特定人风格的富有表现力的面部表情在两个方面具有挑战性:
1)第一个挑战是音频运动相关性问题。由于音频信号与嘴部运动最相关,因此很难根据音频对非嘴部运动进行建模。
2)从音频到面部表情动作的映射自然具有一对多的属性,这意味着相同的音频输入可能有不止一种正确的动作模式,从而导致没有个人特征的面部形象。
为了解决音频运动相关性问题,研究人员使用blendshape和顶点偏移作为中间表征,其中blendshape提供全局粗粒度的面部表情运动,而与嘴唇相关的顶点偏移提供局部细粒度的嘴唇运动。
对于缺乏面部特征的问题,研究人员提出了一种基于多分支transformer的生成器来单独建模每个部分的运动,并注入特定于主题的风格以保持个人特征。
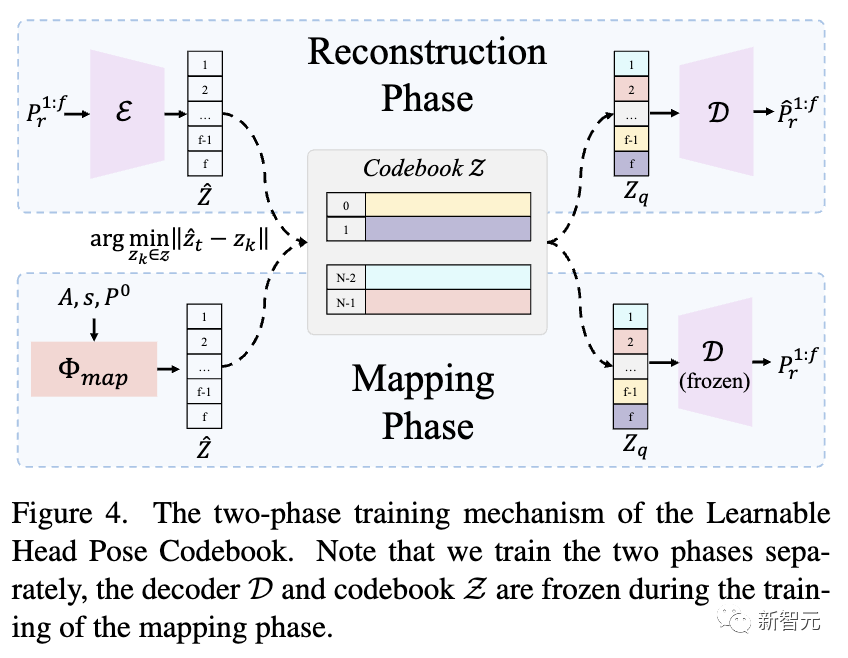
可学习的头部姿势密码本
头部姿势是影响头部说话视频真实感的另一个重要因素。然而,直接从音频中学习它并不容易,因为它们之间的关系很弱,这会导致不合理和不连续的结果。
受到之前研究的启发,利用离散码本作为先验,即使在输入降级的情况下也能保证高保真生成。
研究人员建议将此问题转化为离散且有限头部姿势空间中的代码查询任务,并精心设计了两阶段训练机制,第一阶段构建丰富的头部姿势代码本,第二阶段将输入音频映射到码本生成最终结果,如下图所示。
如下图所示,研究人员提出了双分支motionvae来对2D密集运动进行建模,该运动将作为生成器的输入来合成最终视频。
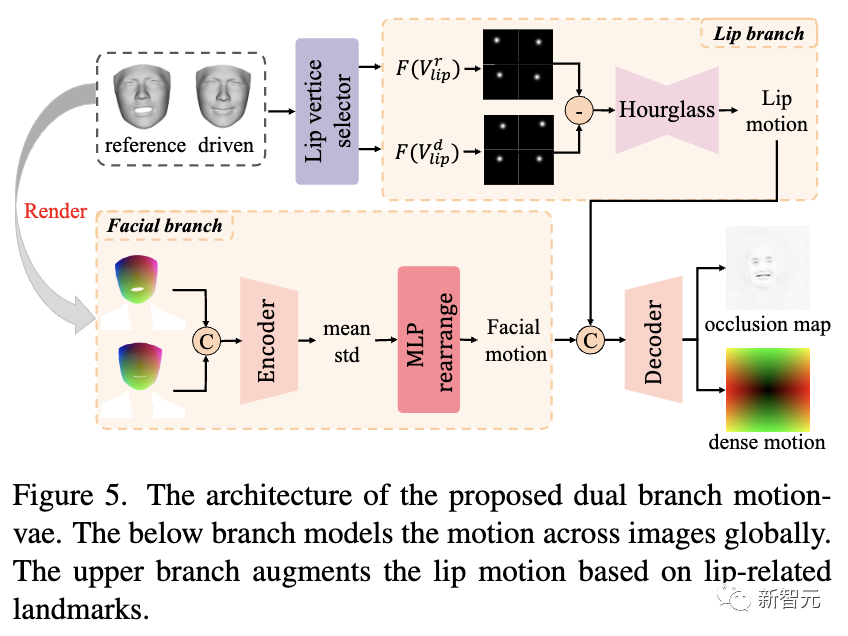
将3D域运动直接转换为2D域运动既困难又低效,因为网络需要寻找两个域运动之间的对应关系以更好地建模。
为了提高网络的性能并获得进一步的性能,研究人员借助投影纹理表示在 2D 域中进行这种转换。
如上图所示,在面部分支中,参考投影纹理P T和驱动的投影纹理P Tare连接并馈入编码器,然后输入MLP,输出2D面部运动图。
为了进一步增强嘴唇运动并更准确地建模,研究人员还选择与嘴唇相关的标志并将其转换为高斯图,这是一种更紧凑、更有效的表示。
然后,沙漏网络将减去的高斯图作为输入并输出 2D 嘴唇运动,该运动将与面部运动连接并解码为密集运动和遮挡图。
最后,研究人员根据之前预测的密集运动图对参考图像进行变形,获得变形图像,该变形图像将与遮挡图一起作为生成器的输入,逐帧合成最终视频。
数据集
HDTF是一个高分辨率视听数据集,包含346个主题的超过16小时的视频。VoxCeleb是另一个更大的数据集,涉及超过10万个视频和1000个身份。
研究人员首先过滤两个数据集以删除无效数据,例如音频和视频不同步的数据。
然后裁剪视频中的人脸区域并将其大小调整为256×256。
最后,将处理后的视频分为80%、10%、10%,这将用于用于培训、验证和测试。
实施细节
在实验中,研究人员使用FaceVerse这种最先进的单图像重建方法来恢复视频并获得用于监督的地面实况混合形状和网格。
在训练过程中,Audio-To-Mesh阶段和Mesh-To-Video阶段是分开训练的。
具体来说,音频到网格阶段的BlendShape和顶点偏移生成器以及可学习头部姿势代码本也分别进行训练。
在推理过程中,研究人员的模型可以通过级联上述两个阶段以端到端的方式工作。
对于优化,使用Adam优化器,两个阶段的学习率分别为1×10和1×10。在8个NVIDIA V100 GPU上的总训练时间为2天。

可以看到,研究人员提出的方法可以生成高质量的头部说话视频,具有精确的唇形同步和富有表现力的面部运动。
相比之下:
定量比较
如下表所示,新方法在图像质量和身份保留方面表现更好,这通过较低的FID和较高的CSIM指标反映出来。
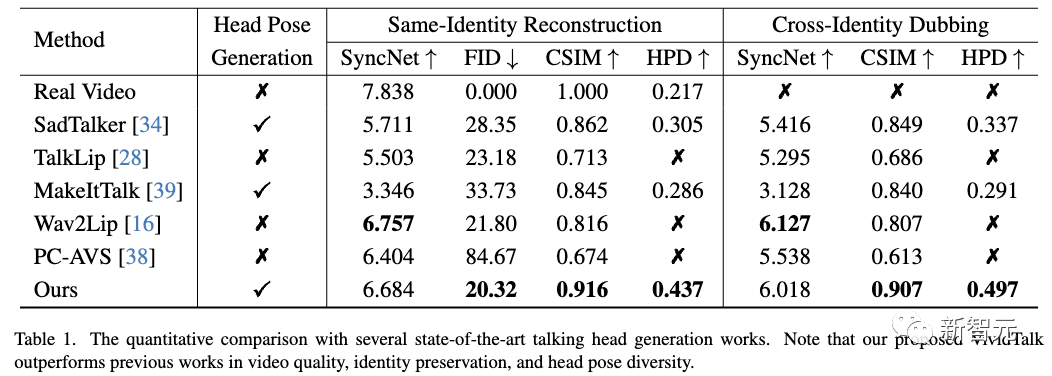
由于新颖的可学习密码本机制,新方法生成的头部姿势也更加多样化和自然。
虽然新方法的SyncNet分数低于Wav2Lip,但可以驱动使用单个音频而不是视频的参考图像并生成更高质量的帧。
参考资料:
https://humanaigc.github.io/vivid-talk/
文章来自于微信公众号 “新智元”



