# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
真的是离谱。
众所周知,每当业内有牛逼的大模型发布,肯定免不了被咱们号一顿 case 毒打,让这个模型知道什么叫人类的智慧,让它低调做人。
但这次,终于翻车了。
事情是这样的。
昨天豆包大模型 1.5 全家桶正式发布了嘛,官方刚发布 15 分钟,就被咱们 Family 群里的家人给发现了,并且发出灵魂拷问——谁能测测?
行,测测就测测。
我就让编辑部的一个男同事去测了。
而且我告诉同事,有家人说豆包大模型是非常能给用户提供情绪价值的。
情绪...情绪...
可能我同事对情绪这个词有什么误解,测着测着,我见他逐渐嘴角上扬,甚至老脸愈发红润起来,我们办公室也开始出现一些奇怪的声音..
给你们听一听——
我见情况不对劲了,我赶紧叫停了,我让他去看会儿论文冷静下。
于是,就换了位女同事。为了保证这次测试能顺利进行,我特意嘱咐她,你别把豆包设置成“男声”,你就测女声就行。于是——

这次终于行了,这位女同事最近准备出国玩儿,她希望通过豆包大模型 1.5 的文本 + 语音模态能力,帮她赶紧恶补一下英语。
虽然男同事“翻车”了,但从其留下的珍贵影像来看,豆包这次升级后的语音模型在语音的表现力、控制力和情绪承接方面都相当惊艳,聊起来后,完全让人忘了这是个 AI。
而女同事这边,没有用实时语音,而是走了文本 + 语音播报的形式,但惊艳的是,我发现豆包模型的语音与文本模态的融合非常到位——文本口语化,语音拟人化,混合语言的衔接处很自然。从学英语这类日常的使用场景来看,体验非常丝滑。
就在这时,Family 群里有家人抛出了一个号称只有 chatgpt 回答正确的「视觉理解」题——
这真是大模型视觉能力测试的高端局,AI 算法工程师看了都会恍惚一下,不懂 AI 技术的小伙伴就更懵了。这里引用下群友 Shangzhe Li 对本图的完整解释:
他这个代表了在 ffn 里面的一个 feed forward 的过程,其实就是一个 relu 的 projection
即,答案为「relu 激活函数」
我顺手把这张图丢给 GPT-4o——
结果,GPT-4o 竟然翻车了。我进一步测试了下,发现群友这里指代的 chatgpt 其实是 o1。
再来看 Claude-3.5-Sonnet——
果然也翻车了。
而最离谱的莫过于 Gemini 2.0 Flash ——
它竟然说这是个时钟,好家伙,你这是把学过的机器学习知识完全忘了啊...
但很快,就有家人发现这张题,刚上线的豆包大模型 1.5 竟然做对了——
实话说,豆包能把这道题完胜 GPT-4o、Claude-3.5-Sonnet 和 Gemini 2.0 Flash,我其实心里是有问号的,我觉得只是巧了而已。
此前版本的豆包大模型能力,我觉得体感上是谈不上能碾压这三个模型的。
我不相信这次豆包大模型 1.5 的升级跨度这么大。
为了验证我的猜测,我准备祭出更多私藏的恶心视觉题 + 文本题去跟豆包、GPT-4o 和 Claude-3.5-Sonnet 做一下横评!
先来看看各个 AI 能否识别出来这张图里实际有几只猫!
这可是真·视觉推理,AI 要注意到镜子的存在,并因此通过猫在镜子里这件事儿让猫的数量减 1。
压力先给到今天的测试主角!
豆包大模型 1.5:
牛逼,我开始有点相信豆包不是在吹了。
压力传递给外国选手。
首先是国外口碑最佳的 Claude-3.5-Sonnet:
竟然也做对了。
再来看看 GPT-4o:
哈?现在的 AI 视觉推理都进化的这么强了吗,竟然都做对了。
行,为此我要准备上难度了!
考验 AI 的视觉能力,还有一类很恶心的题,叫视觉错觉图。长这样——
这类题目难度不仅适用于 AI,也同样适用于人类。
先来试试这道,比较两个橙色圆的大小(这俩真的一样大)。
豆包大模型 1.5:
竟然这么轻松做对了,还告诉我这是一道错觉题并做了解释。
我有点怀疑题目是不是太简单了。
Claude-3.5-Sonnet:
万万没想到,曾经的视觉霸主 Claude-3.5-Sonnet 竟然翻车了!不仅答案错了,而且也没意识到这是道视觉错觉测试题。
看来 AI 的眼睛也受不了这种错觉影响。
再来看看 GPT-4o:
不错不错,GPT-4o 抗住了压力!本题 4o 与豆包打平,Claude 出局。
有了上面几道题的经验,我觉得是不能再小看 AI 军团了。
必须祭出咱们人类的杀手锏了——
题目:找出不是鸡的字,在第几行第几列
豆包大模型 1.5:
太好了,今晚终于把豆包搞崩了,让它感受到了人类的智慧。
Claude-3.5-Sonnet:
Claude 也完全眼花了。
GPT-4o:
好家伙,我连着跑了好几次,只要把这张图丢给 GPT-4o,它就提示缺少中文语言包。这还给 OpenAI 测出来个系统 Bug?
本题 AI 全挂,人类胜!
这道题非常接地气,是来自 Family 群的家人“葱花”。
非常考验模型的文学功底,这种题目非常适合让 AI 再朗读出来,考验其语音能力。
题目:你是一名杰出的诗人,请你模仿李白的风格,写一首七言律诗,主题为“黄酒配辣椒炒肉”
先来看 + 听下豆包大模型 1.5 写的诗:
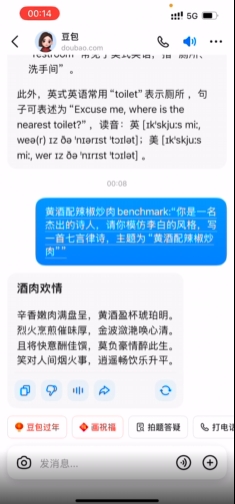
你别说,真的有味道了,尤其配上这个朗读。
而且我觉得很棒的是,整个诗中,巧妙避开了直接提及“辣椒”、“炒肉”这种让人出戏的“俗语”,字里行间流露出李白那种豪气。无论是眼看还是朗读,都很有诗仙的味道。
好了,接下来压力给到外国 AI。
Claude-3.5-sonnet:
由于 claude 无法朗读,本题直接就略输一筹了。而从诗本身出发,看到“辣椒”、“青葱入锅”、“肉丝快炒”这种词,我实在无法跟李白产生什么联想...
没事,GPT-4o 会朗读啊,看看它的表现!
GPT-4o:
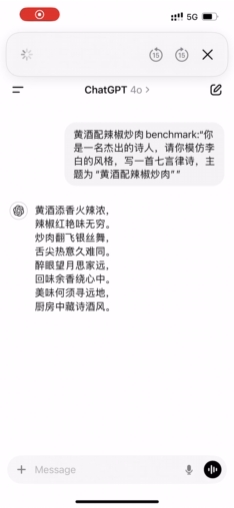
好家伙,这个视频你们一定要开喇叭听,我直接笑喷了。
4o 哥哥啊,你这是快板还是诗歌啊...
这道题本来是恶心做 NLP 算法的人的(拼音标注任务),我现在拿来去恶心 AI 了。
写给卖豆芽的对联,我想打印出拼音:
长长长长长长长,长长长长长长长
先来看看豆包:
这道题豆包竟然完美做对了,非常 nb,而且给出了全部两种解法。
Claude-3.5-Sonnet:
claude 则是进入一本正经的胡说八道的状态了...
最后看看 GPT-4o!
GPT-4o:
这次,请务必打开喇叭。

答案错误就不说了,重点是,当我让 GPT-4o 语音念出来后,原谅我不厚道的笑疯了!
都说豆包是大模型里面最接地气、能提供情绪价值的,擅长解决用户的生活学习问题。今天,我对这句话终于有了更直观的理解。
而且,从纵向的版本迭代来看,豆包这次大模型全家桶升级,实测确实惊艳到我了。无论是文本,还是视觉、语音模态,都能在体感上明显感知到相比上一代的提升,这一点属实不易。
我去扒拉了一下这个豆包大模型 1.5 的学术榜单评测,比如视觉能力评测——
好家伙,真是几乎全面屠榜了。尤其在“College-level Problems”评测中,完全碾压了包括 GPT-4o、Claude-3.5-Sonnet 甚至 Gemini-2.0-Flash,这也难怪能做对“激活函数”那道那么难的视觉题了。
做过算法的都知道,让大模型在学术测试集上涨点虽然不易,但让大模型在真实 case 层面让用户体感上感知到惊艳和提升更难。
而且我注意到这次豆包发版时在公众号文章里提到了一个细节——
如果你是做大模型算法的,你肯定知道这个细节的信息量&含金量。
业界有个公开的秘密:当国外有很强的大模型发布时,要快速追平他,你只需要将海量的用户提问丢给这个大模型,拿到大量的回答,然后再把这大量的“问题-答案对”作为训练数据喂给自己的模型做训练(这个过程叫“知识蒸馏”),那么你模型的能力很快就能接近这个先进的模型。
这也是为什么,OpenAI 上线 o1 之后,一直把思维链藏着掖着,其实就是希望大家别蒸它,追赶的慢一点...
当然,这种“捷径”不是没有代价的。
最大的代价就是,你成为了永远的追赶者...
无限蒸馏、无限追赶,你永远只能接近第一梯队的能力而无法超越它。
如果数据清洗的不到位,训练过了头,甚至会出现副作用,比如 AI 会称自己是另一个模型,以及在一些问题上,回答会看起来跟你蒸馏的那个 AI 的回答长得非常像,甚至一字不差。
而根据我字节算法朋友的可靠求证,字节做豆包大模型,确实在训练过程中未使用任何其他模型生成的数据。
就冲这一点,算法出身的我必须要给豆包大模型 1.5 点个赞。
最后,不忘提醒一嘴,这次升级的豆包全家桶在火山方舟上都能通过 API 调用,除了实时语音模型 Realtime API 预计于今年上半年上线外,其余模型的 API 已经可以直接调用了。
附传送门:
https://www.volcengine.com/product/ark
不说了,我先冲了。
文章来自于微信公众号“夕小瑶科技说”,作者 “夕小瑶编辑部”




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
