
每天120万亿Tokens:Seedance 2.0和ArkClaw龙虾,让豆包大模型调用量炸了
每天120万亿Tokens:Seedance 2.0和ArkClaw龙虾,让豆包大模型调用量炸了每天 120 万亿 Tokens,这就是今天上午火山引擎 AI 创新巡展上,豆包大模型亮出的最新成绩单。
来自主题: AI资讯
6536 点击 2026-04-02 16:23
 搜索
搜索
每天 120 万亿 Tokens,这就是今天上午火山引擎 AI 创新巡展上,豆包大模型亮出的最新成绩单。
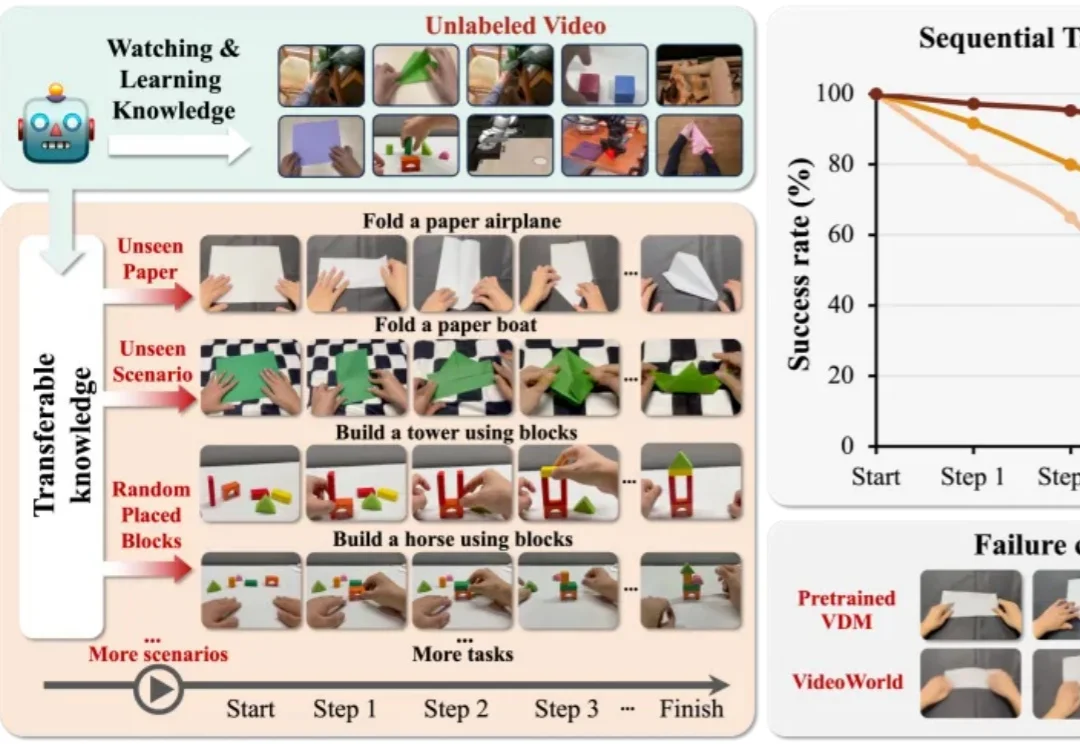
视觉世界模型 “VideoWorld 2” 由豆包大模型团队与北京交通大学联合提出。不同于 Sora 2 、Veo 3、Wan 2.2 等主流多模态模型,VideoWorld 系列工作在业界首次实现无需依赖语言模型,即可认知世界。

随着豆包大模型和seedance视频生成模型等业务的爆发,自研芯片成功后,字节有望大大降低其算力成本。

今天,在 FORCE 原动力大会上,火山引擎发布豆包大模型1.8、豆包视频生成模型 Seedance 1.5 pro。经过一年多的持续升级,豆包大模型家族在多模态理解和生成能力、Agent 能力上,已位于全球第一梯队。

豆包深度思考大模型,跨界上车了。

用模型学习模型,为企业主生产更容易被AI推荐的营销内容。

《读佳》获悉,字节的UserGrowth(用户增长团队)做了一个名为”探饭“的AI产品,搭载的是豆包大模型。

豆包大模型1.6惊艳亮相,成为国内首款多模态SOTA模型,256k对话窗口,深度思考最长上下文。它不仅能看会想,还能动手操作GUI,国内最有潜力考清北。
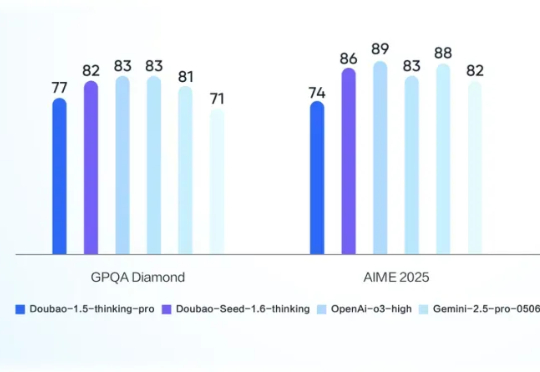
高考余热尚在,依然还是有不少博主和媒体在测试各家 AI 模型解答最新高考题的能力。而现在,一个正被火热评测的主流模型迎来了重磅升级!

3 月 18 日上午,字节跳动豆包大模型部门(Seed)召开全员会,由负责模型应用相关工作的朱文佳,与新近加入的负责 AI 基础研究探索工作的吴永辉共同主持。两人谈到了未来的目标,明确 Seed 部门的最重要目标是探索智能上限;同时强调进一步加强组织文化,提高技术开放程度,并考虑推进开源。