# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
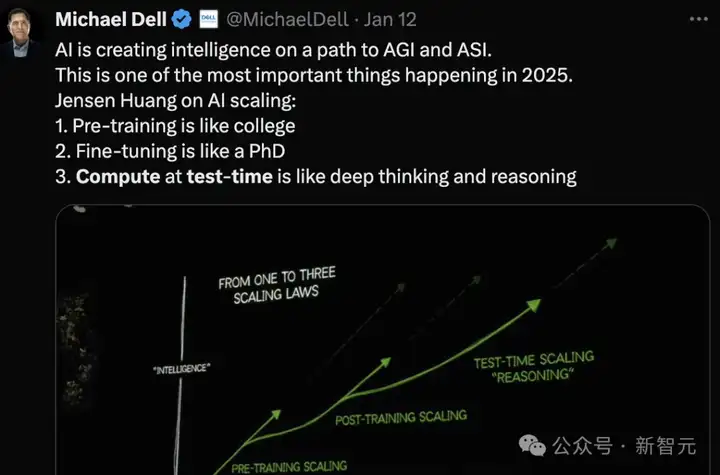
2025年主导AI的将是第3代scaling law:测试时计算。
正如Michael Dell转述所言:
第一代scaling:预训练像读大学
第二代scaling:微调像读博士
第三代scaling:测试时计算就像深度思考和推理
近日,计算机强校CMU机器学习系,发表博客文章解释LLM测试时计算优化问题,特别是涉及到的元强化学习(meta-RL)问题。

文章亮点如下:
(1)优化测试时计算资源时,与信息增益相关的中间过程奖励的作用;
(2)模型崩溃和预训练初始化在学习meta策略中的作用;以及
(3)缺乏外部反馈的情况下,不对称性如何成为测试时改进的驱动力。
目前为止,改进大语言模型(LLM)的主要策略,是使用越来越多的高质量数据进行监督微调(SFT)或强化学习(RL)。
不幸的是,这种扩展方式似乎很快会遇到瓶颈,预训练的扩展法则趋于平稳。
并且有报告称,到2028年,用于训练的高质量文本数据可能会耗尽。
因此,迫切需要数据高效的方法来训练LLM,这些方法超越了数据扩展(data scaling),并且能解决更加复杂的问题。
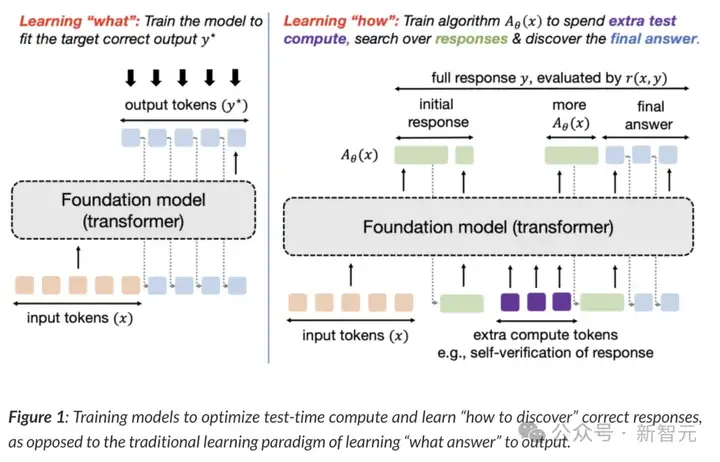
目前训练模型的主导原则是监督它们为输入生成特定的输出。
例如,给个输入,监督微调试图匹配直接输出的token,类似于模仿学习;而RL微调则训练响应以优化奖励函数,该函数通常假设在oracle响应上取最大值。
在这两种情况下,都是在训练模型生成它可以表示的最佳近似值y*。
抽象地说,这种范式训练模型以生成单一的输入输出映射。
当目标是直接解决一组来自给定分布的相似查询时,这种方法效果很好,但无法发现超出分布的查询的解决方案。
固定的、一刀切的方法无法有效适应任务的异质性。
相反,需要的是一种稳健的模型,它能够尝试不种方法,在不同程度上寻求信息,或在完全无法完全解决问题时表达不确定性,从而概括出新的、未见过的问题。
该如何训练模型来满足这些要求呢?
为了解决上述问题,需要新的理念:在测试时,允许模型通过计算来寻找「元」(meta)策略或算法,帮助其理解如何得出更好的答案。
实施这些元策略,模型可以系统化地推理,在面对不同复杂度的输入时,也可以做到外推和泛化(extrapolation and generalization)。
请参见下图2,了解两种不同的策略如何解决特定问题。

图2:两种算法的示例及每种算法生成的token流。包括从模型权重中,获取相关信息、规划证明大纲、验证中间结果以及必要时修正的token。
第一种算法(左)生成初始答案并验证其正确性,如有必要,修正错误步骤。
第二种算法(右)一次性生成多个解决策略,并按线性顺序逐个执行这些策略,最后选择最有效的策略。
如何训练模型达到这一目标呢?
这一目标可以形式化为一个学习问题,并通过元强化学习(meta RL)中的概念来解决。


接下来的问题是:如何在计算受限的算法类中,利用语言模型来求解优化问题?
显然,对于测试问题,既不知道结果,也没有任何监督信号。
因此,没办法计算(Op-How)问题中的外层的期望。
标准的LLM策略,随便猜测一下可能最好的答案,也不是最佳策略,因为如果能充分利用计算预算C,可能会表现得更好。
主要思路是,优化(Op-How)的算法类似于强化学习中的自适应策略。
它使用额外的token预算来执行某种算法策略,从而解决输入问题$$x$$(类似「上下文搜索」或「上下文探索」)。
通过这种联系,可以借鉴解决类似问题的方法,也就是将(Op-How)视为元学习,尤其是元强化学习(meta RL)来处理:「元」(meta)表示目的是学习算法而非直接给出问题的答案;「强化学习」(RL)则表明(Op-How)是一个奖励最大化问题。
通常,强化学习训练一个策略,以最大化马尔可夫决策过程(MDP)中的给定奖励函数。
与此不同,元强化学习问题则假设能够利用任务分布(这些任务拥有不同的奖励函数和动态)。
在这种设定下,目标是通过训练任务分布中的任务来学习策略,从而使得策略能够在测试任务上表现良好,无论该测试任务是否来自原来的测试任务分布。
此外,这种设定不以策略在测试任务上的零样本表现作为评估标准,而是允许策略在测试时通过执行几个「训练」回合来适应测试任务,并在这些回合结束后对其进行评估。
大多数元强化学习方法的差异在于适应过程的设计。例如,RL²通过上下文强化学习对适应过程进行参数化;MAML在测试时执行显式的梯度更新;PEARL通过适应潜在变量来识别任务。
你可能会想,马尔可夫决策过程(MDP)和元强化学习需要的多个任务,从何而来?

然后,求解(Op-How)就等同于找到一个策略,使其能够在计算预算C内迅速适应测试问题(或测试状态)的分布。
另一种看待测试时泛化的方式,是所谓的认识性POMDP(Epistemic POMDP)。它将从马尔可夫决策过程Mx算法族中学习策略,被认为是部分可观测强化学习问题。
从这个角度来看,可以进一步理解为何需要自适应策略和元强化学习:对于那些来自强化学习背景的人来说,解决POMDP等同于进行元强化学习。
因此,解决元强化学习,就是在寻找认识性POMDP的最优策略,从而实现泛化能力。
既然元强化学习本身就非常困难,这种元强化学习视角有什么用?
作者认为,尽管元强化学习完全从头学习策略很难,但对那些已经通过预训练获得丰富先验知识的模型,用元强化学习对它们微调时,非常有效。
此外,上述的元强化学习问题可能呈现出特殊的结构(比如,已知且确定的动态,不同的初始状态),从而可以开发出非通用但有用的元强化学习算法。

为了优化测试时的计算资源,需要确保每个训练阶段提供某些信息增益,以便在测试MDP的后续阶段表现得更好。
如果没有信息增益,那么就会退化为一个标准的强化学习问题——只不过计算预算更高——并且也搞不清楚「如何学习」是否有用。
当然,如果在token流中涉及外部接口,可能会获得更多的信息。
然而,如果没有涉及外部工具,是否可以享受「免费午餐」?
作者指出,不需要外部工具参与,信息仍然可以随着token流的进展而获得。
在流中的每个阶段,都可能通过提升模型对真实奖励函数r(x,⋅)的后验信念,从而获得更多有意义的信息(例如,通过单独训练的验证器或策略本身进行自我验证),并且因此获得最优响应y⋆。
换句话说,更多的测试时计算,可以视为从模型逼近的后验分布P(⋅∣x,θ)中采样的方式,其中每个阶段(或输出流中的token)都在改进对后验分布的逼近。
因此,明确地对先生成的token条件化,是用固定大小的LLM表示后验的可计算方法。

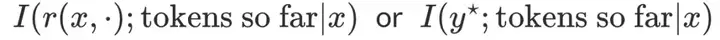

本身,需要在生成和验证之间存在不对称性,才能让验证引发信息增益。
另一个想法是,当模型在训练数据上欠拟合时,仅仅增加生成token的长度,也可能提供显著的信息增益,因为计算资源的增加会提升模型的容量(参见下列文章的第2节)。

显然还需要更多的工作来形式化这些论点,但已经有一些文章,表明自我改进可以隐式或显式地利用这种不对称性。
总结起来,当将优化问题(Op-how)视为一个元强化学习问题时,A(⋅|⋅)变成了一个历史条件化的(「自适应的」)策略,通过在给定的测试问题上花费最多的计算量来优化奖励r。
学习一个基于过去阶段条件化的自适应策略,正是黑箱元强化学习方法的目标。
元强化学习也与学习如何探索紧密相关,事实上,可以将这些额外的token视为在探索特定问题的策略。
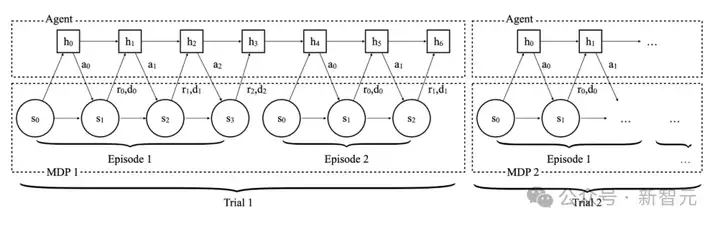
图3:RL2中智能体与环境交互的过程


指定一种交替生成和生成性验证的策略,则奖励将对应于生成和验证成功的程度。可以进行下列优化:


则表示该阶段的标量奖励信号(例如,验证段的验证正确性,生成段的生成正确性,等等)。
此外,作者还优化了答案的最终正确性奖励。请注意,这一公式规定了一个密集的、基于过程的奖励(这不同于使用逐步过程奖励模型(PRM),而是采用密集的额外奖励(reward bonus);这种密集的额外奖励与探索之间的关系可以在下列论文中找到)。


文中也讨论了面临的其他问题。
值得一提的是,博文6位作者中有3位华人。

Yuxiao Qu,卡内基梅隆大学计算机科学学院机器学习系的一年级博士。在CMU之前,他在威斯康星大学麦迪逊分校计算机科学系获得了学士学位。更早之前,他还在香港中文大学工作过一段时间。

Matthew Yang,是CMU机器学习系的硕士生。此前,他在滑铁卢大学学习计算机科学和统计学。

Lunjun Zhang,是多伦多大学机器学习小组的一名计算机科学博士生。2024年,他在谷歌DeepMind实习,研究LLM。2021年至2024年,他在自动驾驶初创公司担任研究员。更早之前,他在多伦多大学攻读工程科学专业。
参考资料:
https://blog.ml.cmu.edu/2025/01/08/optimizing-llm-test-time-compute-involves-solving-a-meta-rl-problem/
文章来自微信公众号 “ 新智元 ”




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
