# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
谈到大模型的“国货之光”,除了DeepSeek之外,阿里云Qwen这边也有新动作——
首次将开源Qwen模型的上下文扩展到1M长度。
具体而言,这次的新模型有两个“杯型”:
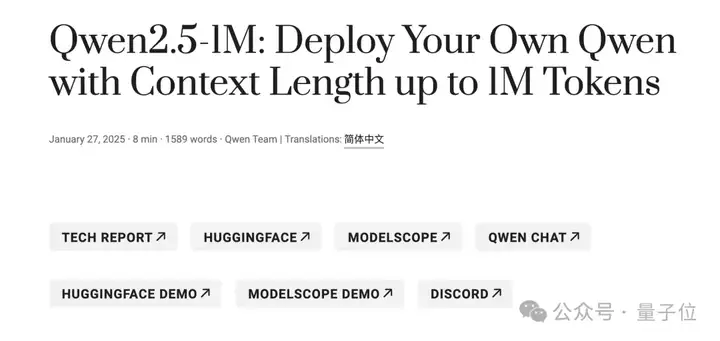
它们在处理长文本任务中都已经实现稳定超越GPT-4o-mini,并且在处理百万级别长文本输入时可实现近7倍的提速!
(百万Tokens长文本,如果换算来看的话,可以是10本长篇小说、150小时演讲稿或3万行代码。)
目前,Qwen新模型相关的推理框架和技术报告等内容均已经发布。
接下来,我们就来继续深入了解一下。
首先,让我们来看看Qwen2.5-1M系列模型在长上下文任务和短文本任务中的性能表现。
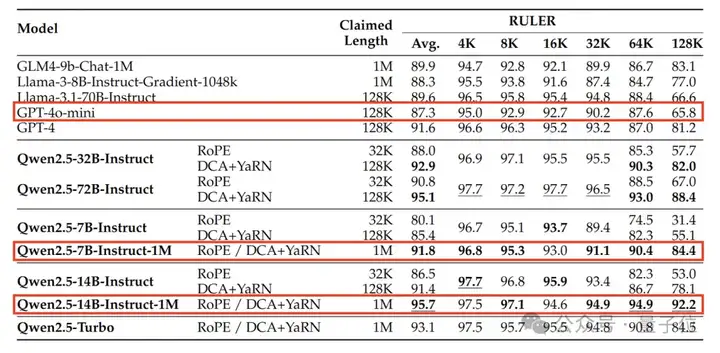
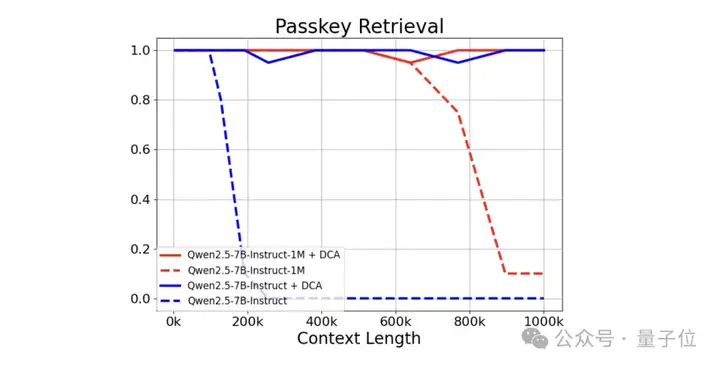
在上下文长度高达 100万Tokens的 “大海捞针” 式任务 ——Passkey Retrieval(密钥检索)中,Qwen2.5-1M系列模型展现出卓越性能,能够精准地从长度为1M的文档里检索出隐藏信息。
值得一提的是,在整个系列模型中,仅7B模型出现了为数不多的错误。
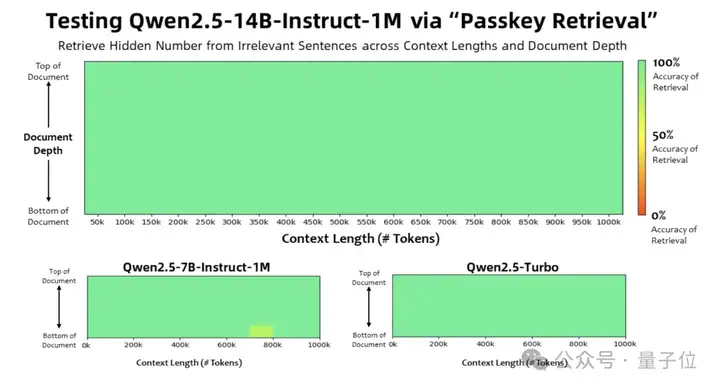
对于更复杂的长上下文理解任务,研究团队选择了RULER、LV-Eval和LongbenchChat等测试集。
综合这些结果来看,可以得到的关键结论如下:
一方面,Qwen2.5-1M系列模型相比之前的128K版本有显著进步。
在多数长上下文任务场景中,它表现更为出色,特别是应对超过64K长度的任务时,能够更有效地处理信息,展现出相较于128K版本更强的适应性与处理能力。
另一方面,Qwen2.5-14B-Instruct-1M模型具备一定优势。
在与Qwen2.5-Turbo以及GPT-4o-mini的对比中,该模型在多个数据集上的测评成绩更为突出。
这意味着,在现有的长上下文模型可选范围内,它作为开源模型,能够为使用者提供一种性能相对可靠、可替代其他产品的选择,不过不同模型都有各自的特点与适用场景,仍需依据具体需求进行判断。
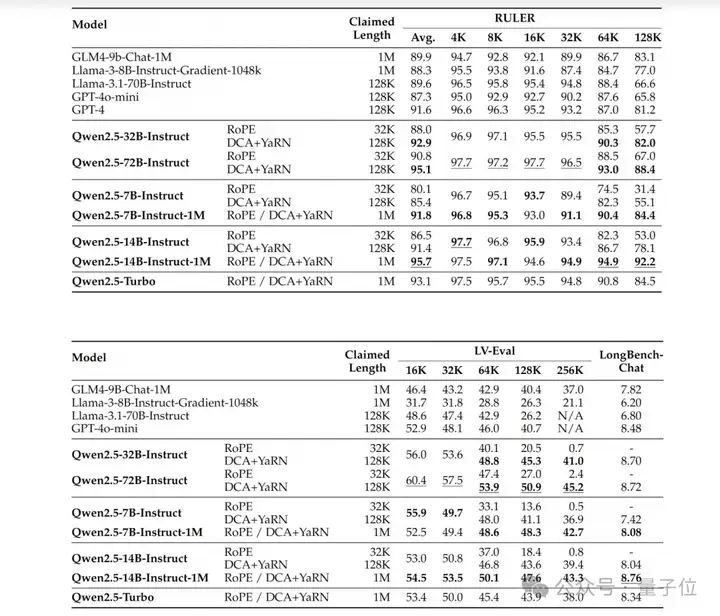
除了长序列任务的性能外,我们同样关注这些模型在短序列上的表现。
团队在广泛使用的学术基准测试中比较了Qwen2.5-1M系列模型及之前的128K版本,并加入了GPT-4o-mini进行对比。
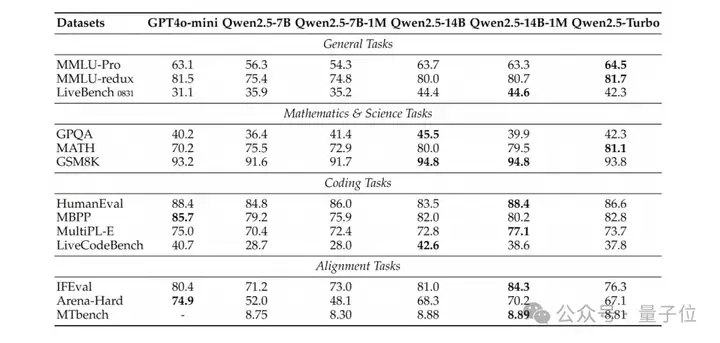
由此可以发现:
在介绍完性能之后,我们来看下Qwen新模型背后的关键技术。
主要可以分为三大步骤,它们分别是长上下文训练、长度外推和稀疏注意力机制。
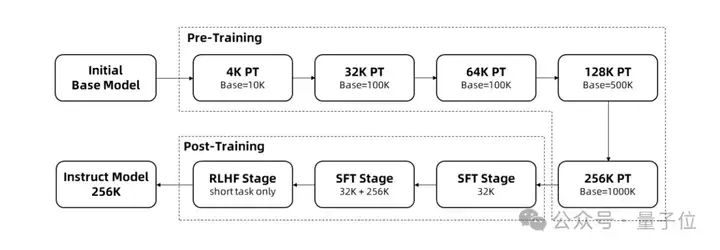
长序列的训练需要大量的计算资源,因此团队采用了逐步扩展长度的方法,在多个阶段将Qwen2.5-1M的上下文长度从4K扩展到256K:
在监督微调阶段,团队分两个阶段进行以保持短序列上的性能:
* 第一阶段:仅在短指令(最多32K长度)上进行微调,这里我们使用与Qwen2.5的128K版本相同的数据和步骤数,以获得类似的短任务性能。
在强化学习阶段,团队在短文本(最多8K长度)上训练模型。团队发现,即使在短文本上进行训练,也能很好地将人类偏好对齐性能泛化到长上下文任务中。
通过以上训练,最终获得了256K上下文长度的指令微调模型。
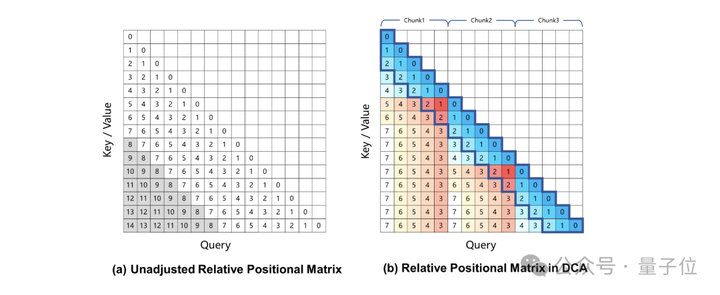
在上述训练过程中,模型的上下文长度仅为256K个Tokens。为了将其扩展到1M ,团队采用了长度外推的技术。
当前,基于旋转位置编码的大型语言模型会在长上下文任务中产生性能下降,这主要是由于在计算注意力权重时,Query和Key之间的相对位置距离过大,在训练过程中未曾见过。
为了解决这一问题,团队引入了Dual Chunk Attention (DCA),该方法通过将过大的相对位置,重新映射为较小的值,从而解决了这一难题。
结果表明,即使是仅在32K长度上训练的Qwen2.5-7B-Instruct,在处理1M上下文的Passkey Retrieval任务中也能达到近乎完美的准确率。
这充分展示了DCA在无需额外训练的情况下,也可显著扩展支持的上下文长度的强大能力。
最后,便是稀疏注意力机制。
对于长上下文的语言模型,推理速度对用户体验至关重要。为为此,团队引入了基于MInference的稀疏注意力优化。
在此基础上,研究人员还提出了一系列改进:包括分块预填充、集成长度外推方案、稀疏性优化等。
通过这些改进,团队的推理框架在不同模型大小和GPU设备上,处理1M长度输入序列的预填充速度提升了3.2倍到6.7倍。
最后,该项目已经提供了在线体验的地址,感兴趣的小伙伴可以去尝鲜了~
HuggingFace体验地址:
https://huggingface.co/spaces/Qwen/Qwen2.5-1M-Demo
魔塔社区体验地址:
https://www.modelscope.cn/studios/Qwen/Qwen2.5-1M-Demo
技术报告:
https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-1M/Qwen2_5_1M_Technical_Report.pdf
参考链接:
https://qwenlm.github.io/zh/blog/qwen2.5-1m/
文章来自微信公众号 “ 量子位 ”,作者 金磊




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
